39373
•
10 минут чтения
•


Индексация страниц сайта — это то, с чего начинается процесс поисковой оптимизации. Разрешение поисковым роботам получать доступ к вашему контенту означает, что ваши страницы готовы к посетителям, у них нет никаких технических проблем, и вы хотите, чтобы они отображались в результатах поиска, поэтому всеобъемлющая индексация на первый взгляд кажется огромным преимуществом.
Однако некоторые типы страниц лучше держать подальше от SERP, чтобы обеспечить свои рейтинги. Это значит, что вам нужно скрыть их от индексации. В этой статье я расскажу вам о типах контента, которые нужно скрыть от поисковых систем, и покажу, как это сделать.
Давайте перейдем к делу без лишних слов. Вот список страниц, которые лучше скрыть от поисковых систем, чтобы они не появлялись в результатах поиска.
Защита контента от прямого поискового трафика обязательна, когда страница содержит персональную информацию. Это страницы с конфиденциальными данными компании, информацией об альфа-продуктах, информацией о профилях пользователей, частной перепиской, платежными данными и т. д. Поскольку персональный контент должен быть скрыт от кого-либо, кроме владельца данных, Google (или любая поисковая система) не должна делать эти страницы видимыми для более широкой аудитории.
Если форма входа размещена не на главной странице, а на отдельной странице, то нет никакой реальной необходимости показывать эту страницу в SERP. Такие страницы не несут никакой дополнительной ценности для пользователей, что можно считать слабым контентом.
Это страницы, которые пользователи видят после успешного действия на веб-сайте, будь то покупка, регистрация или что-то еще. Эти страницы также, скорее всего, будут иметь скудный контент и не будут иметь никакой дополнительной ценности для пользователей поиска.
Контент на страницах такого типа дублирует контент основных страниц вашего веб-сайта, а это значит, что при сканировании и индексации такие страницы будут рассматриваться как полные дубликаты контента.
Это распространенная проблема для крупных сайтов электронной коммерции, на которых много товаров, отличающихся только размером или цветом. Google может не заметить разницу между ними и считать их дубликатами контента.
Когда пользователи заходят на ваш сайт из SERP, они ожидают нажать на вашу ссылку и найти ответ на свой запрос. А не на еще одну внутреннюю SERP с кучей ссылок. Поэтому если ваши внутренние SERP попадут в индекс, они, скорее всего, не принесут ничего, кроме низкого времени на странице и высокого показателя отказов.
Если все записи вашего блога написаны одним автором, то страница с биографией автора является точной копией домашней страницы блога.
Подобно страницам входа, формы подписки обычно не содержат ничего, кроме формы для ввода данных для подписки. Таким образом, страница а) пуста, б) не представляет никакой ценности для пользователей. Вот почему вам нужно ограничить поисковые системы от попадания их в SERP.
Практическое правило: страницы, находящиеся в процессе разработки, следует держать подальше от поисковых роботов до тех пор, пока они не будут полностью готовы к приему посетителей.
Зеркальные страницы — это идентичные копии ваших страниц на отдельном сервере/местоположении. Они будут считаться техническими дубликатами при сканировании и индексации.
Специальные предложения и рекламные страницы должны быть видны пользователям только после выполнения ими специальных действий или в течение определенного периода времени (специальные предложения, мероприятия и т. д.). После окончания мероприятия эти страницы не обязательно должны быть видны кому-либо, включая поисковые системы.
А теперь вопрос: как скрыть все вышеупомянутые страницы от надоедливых пауков и сохранить остальную часть вашего сайта видимой такой, какой она должна быть?
При настройке инструкций для поисковых систем у вас есть два варианта. Вы можете ограничить сканирование или ограничить индексацию страницы.
Возможно, самый простой и прямой способ ограничить доступ поисковых роботов к вашим страницам — это создать файл robots.txt. Файлы robots.txt позволяют вам проактивно исключить весь нежелательный контент из результатов поиска. С помощью этого файла вы можете ограничить доступ к одной странице, целому каталогу или даже к одному изображению или файлу.


Процедура довольно проста. Вы просто создаете файл.txt, который имеет следующие поля:
Обратите внимание, что некоторые сканеры (например, Google) также поддерживают дополнительное поле, называемое Allow:. Как следует из названия, Allow: позволяет явно перечислить файлы/папки, которые можно сканировать.
Ниже приведены некоторые основные примеры файлов robots.txt.


* в строке User-agent означает, что всем поисковым роботам предписано не сканировать никакие страницы вашего сайта, на что указывает /. Скорее всего, именно этого вы предпочли бы избежать, но теперь вы поняли.


В приведенном выше примере вы запрещаете боту Google Image сканировать ваши изображения в выбранном каталоге.
Дополнительные инструкции о том, как писать такие файлы вручную, можно найти в руководстве разработчика Google.
Но процесс создания robots.txt может быть полностью автоматизирован – существует широкий спектр инструментов, которые способны создавать такие файлы. Например, WebSite Auditor может легко скомпилировать файл robots.txt для вашего сайта.
Запустив инструмент и создав проект для своего веб-сайта, перейдите в раздел Структура сайта > Страницы, щелкните значок гаечного ключа и выберите Robots.txt.
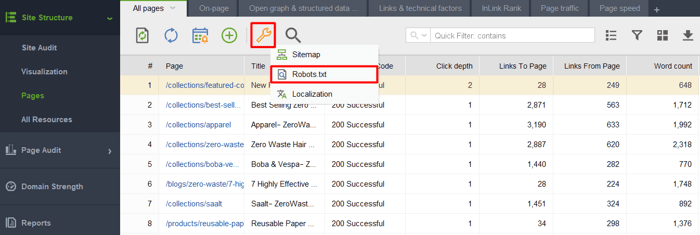
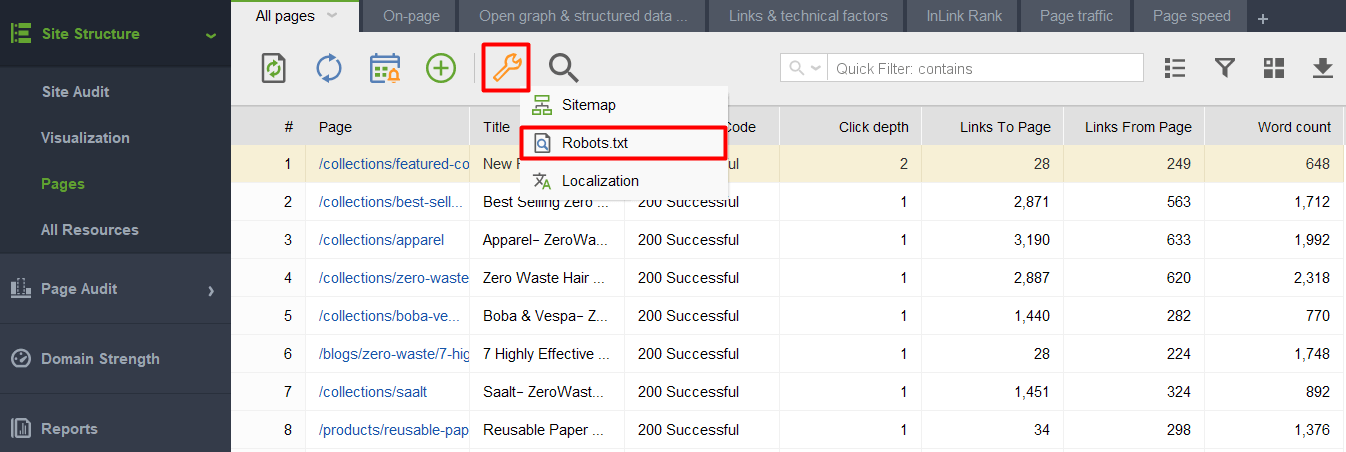
Затем нажмите Добавить правило и укажите инструкции. Выберите поисковый бот и каталог или страницу, для которой вы хотите ограничить сканирование.

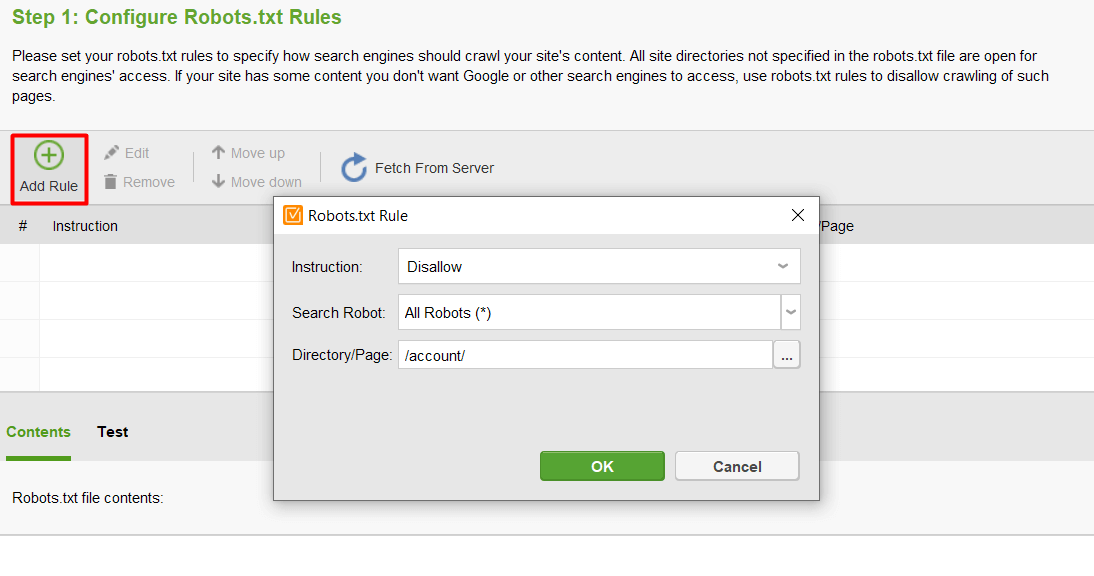
После завершения всех настроек нажмите «Далее», чтобы инструмент сгенерировал файл robots.txt, который вы затем сможете загрузить на свой веб-сайт.
Чтобы просмотреть заблокированные для сканирования ресурсы и убедиться, что вы не запретили сканирование чего-либо, что следует сканировать, перейдите в раздел Структура сайта > Аудит сайта и проверьте раздел Ресурсы, ограниченные для индексации:
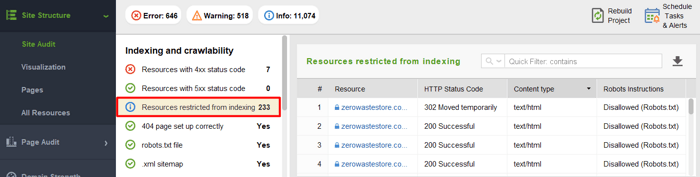

Также имейте в виду, что протокол robots.txt носит исключительно рекомендательный характер. Это не блокировка страниц вашего сайта, а скорее «Частное — не входить». Robots.txt может помешать «законопослушным» ботам (например, Google, Yahoo! и Bing) получить доступ к вашему контенту. Однако вредоносные боты просто игнорируют его и все равно просматривают ваш контент. Поэтому существует риск, что ваши личные данные могут быть скопированы, скомпилированы и повторно использованы под видом добросовестного использования. Если вы хотите сохранить свой контент на 100% безопасным, вам следует ввести более безопасные меры (например, добавить регистрацию на сайте, скрыть контент под паролем и т. д.).
Вот наиболее распространенные ошибки, которые люди допускают при создании файлов robots.txt. Внимательно прочтите эту часть.
1) Использование заглавных букв в имени файла. Имя файла robots.txt. Точка. Не Robots.txt и не ROBOTS.txt
2) Не помещать файл robots.txt в основной каталог
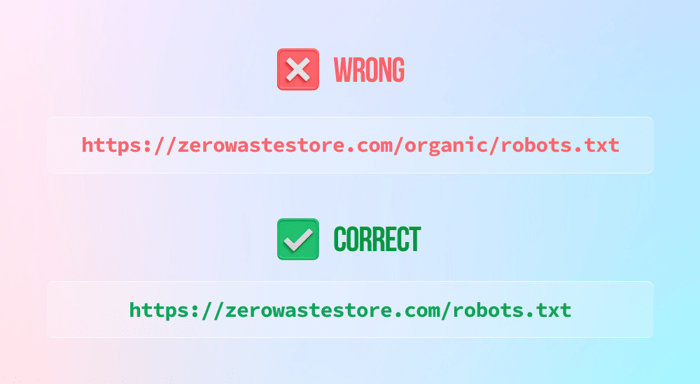

3) Заблокируйте весь свой веб-сайт (если вы этого не хотите), оставив запретную инструкцию следующим образом


4) Неправильное указание user-agent


5) Упоминание нескольких каталогов в одной строке запрета. Каждой странице или каталогу нужна отдельная строка


6) Оставляем строку user-agent пустой
7) Список всех файлов в каталоге. Если вы скрываете весь каталог, вам не нужно беспокоиться о перечислении каждого файла


8) Строка запрета инструкций вообще не упоминается


9) Отсутствие указания карты сайта в конце файла robots.txt
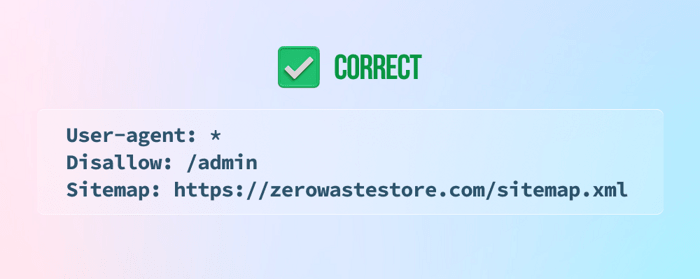

10) Добавление инструкции noindex в файл
Использование метатега robots noindex или тега X-Robots позволит поисковым роботам сканировать и получать доступ к вашей странице, но не позволит странице попасть в индекс, т. е. появиться в результатах поиска.
Теперь давайте рассмотрим каждый вариант подробнее.
Метатег robots noindex размещается в исходном коде HTML вашей страницы (раздел <head>). Процесс создания этих тегов требует лишь немного технических знаний и может быть легко выполнен даже начинающим SEO-специалистом.
Когда бот Google извлекает страницу, он видит метатег noindex и не включает эту страницу в веб-индекс. Страница все еще сканируется и существует по указанному URL, но не будет отображаться в результатах поиска независимо от того, как часто на нее ссылаются с любой другой страницы.
<meta name="robots" content="index, follow">
Добавление этого метатега в исходный HTML-код вашей страницы дает указание поисковому роботу проиндексировать эту страницу и все ссылки, ведущие с этой страницы.
<meta name="robots" content="index, nofollow">
Изменяя «follow» на «nofollow», вы влияете на поведение поискового бота. Вышеупомянутая конфигурация тега предписывает поисковой системе индексировать страницу, но не следовать по ссылкам, размещенным на ней.
<meta name="robots" content="noindex, follow">
Этот метатег сообщает поисковому боту, что нужно игнорировать страницу, на которой он размещен, но переходить по всем размещенным на ней ссылкам.
<meta name="robots" content="noindex, nofollow">
Этот тег, размещенный на странице, означает, что ни сама страница, ни содержащиеся на ней ссылки не будут просматриваться или индексироваться.
Помимо метатега robots noindex, вы можете скрыть страницу, настроив ответ заголовка HTTP с X-Robots-Tag со значением noindex или none.
Помимо страниц и элементов HTML, X-Robots-Tag позволяет вам noindex отдельных PDF-файлов, видео, изображений или любых других не-HTML-файлов, для которых использование метатегов robots невозможно.
Механизм очень похож на механизм тега noindex. Когда поисковый бот заходит на страницу, HTTP-ответ возвращает заголовок X-Robots-Tag с инструкциями noindex. Страница или файл все равно сканируются, но не отображаются в результатах поиска.
Это наиболее распространенный пример HTTP-ответа с указанием не индексировать страницу.
HTTP/1.1 200 ОК
(…)
X-Robots-Тег: noindex
(…)
Вы можете указать тип поискового бота, если вам нужно скрыть свою страницу от определенных ботов. В примере ниже показано, как скрыть страницу от любой другой поисковой системы, кроме Google, и запретить всем ботам переходить по ссылкам на этой странице:
X-Robots-Tag: googlebot: nofollow
X-Robots-Tag: otherbot: noindex, nofollow
Если тип робота не указан, инструкции будут действительны для всех типов поисковых роботов.
Чтобы ограничить индексацию определенных типов файлов на всем вашем сайте, вы можете добавить инструкции ответа X-Robots-Tag в файлы конфигурации программного обеспечения веб-сервера вашего сайта.
Вот как можно ограничить доступ ко всем PDF-файлам на сервере Apache:
<Файлы ~ "\.pdf$">
Заголовок набора X-Robots-Tag "noindex, nofollow"
</Файлы>
А это те же инструкции для NGINX:
местоположение ~* \.pdf$ {
add_header X-Robots-Tag "noindex, nofollow";
}
Чтобы ограничить индексацию одного элемента, для Apache используется следующий шаблон:
# файл htaccess должен быть помещен в каталог соответствующего файла.
<Файлы "unicorn.pdf">
Заголовок набора X-Robots-Tag "noindex, nofollow"
</Файлы>
А вот как ограничить индексацию одного элемента для NGINX:
местоположение = /secrets/unicorn.pdf {
add_header X-Robots-Tag "noindex, nofollow";
}
Хотя тег robots noindex кажется более простым решением для ограничения индексации ваших страниц, в некоторых случаях использование тега X-Robots-Tag для страниц является лучшим вариантом:
Тем не менее, помните, что только Google точно следует инструкциям X-Robots-Tag. Что касается остальных поисковых систем, нет никакой гарантии, что они правильно интерпретируют тег. Например, Seznam вообще не поддерживает теги x-robots. Поэтому, если вы планируете, чтобы ваш сайт отображался в различных поисковых системах, вам нужно будет использовать тег robots noindex в фрагментах HTML.
Наиболее распространенные ошибки, которые допускают пользователи при работе с тегами noindex:
1) Добавление страницы или элемента noindexed в файл robots.txt. Robots.txt ограничивает сканирование, поэтому поисковые роботы не будут заходить на страницу и видеть директивы noindex. Это означает, что ваша страница может быть проиндексирована без контента и все равно отображаться в результатах поиска.
Чтобы проверить, попали ли какие-либо из ваших страниц с тегом noindex в файл robots.txt, проверьте столбец «Инструкции для роботов» в разделе «Структура сайта» > «Страницы» в WebSite Auditor.
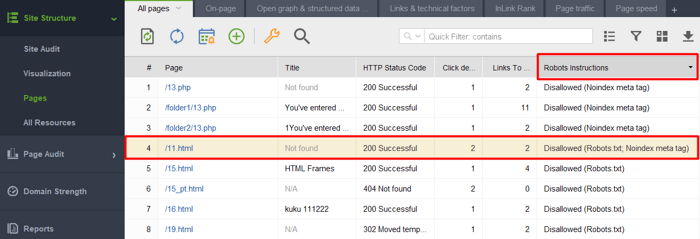
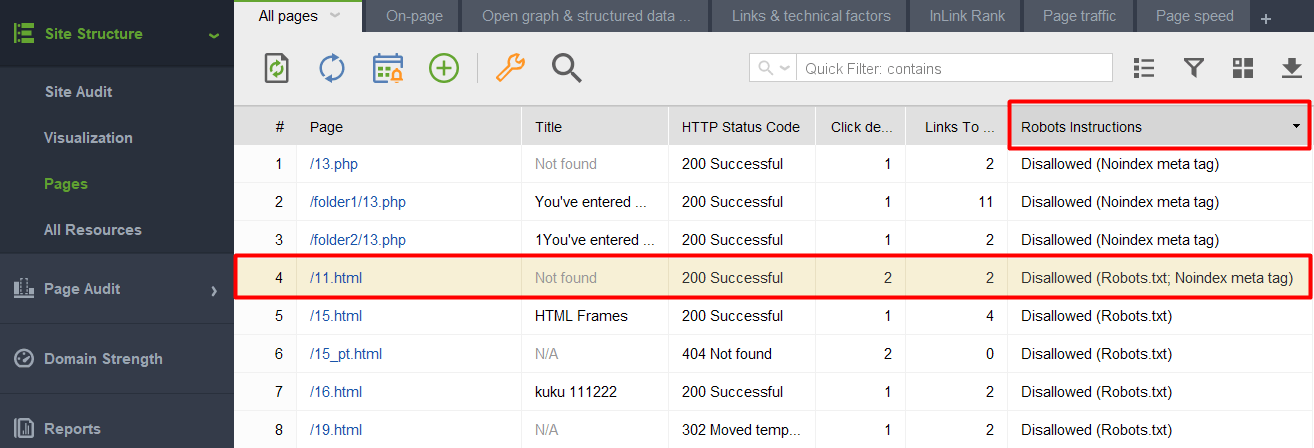
Примечание: Не забудьте включить параметры эксперта и снять отметку с параметра «Следовать инструкциям robots.txt» при сборке проекта, чтобы инструмент видел инструкции, но не следовал им.
2) Использование заглавных букв в директивах тегов. Согласно Google, все директивы чувствительны к регистру, поэтому будьте осторожны.
Теперь, когда с основными проблемами индексации контента все более-менее понятно, перейдем к нескольким нестандартным случаям, заслуживающим особого упоминания.
1) Убедитесь, что страницы, которые вы не хотите индексировать, не включены в вашу карту сайта. Карта сайта — это фактически способ сообщить поисковым системам, куда им следует идти в первую очередь при сканировании вашего сайта. И нет никаких причин просить поисковых роботов посещать страницы, которые вы не хотите, чтобы они видели.
2) Тем не менее, если вам нужно деиндексировать страницу, которая уже присутствует в карте сайта, не удаляйте страницу из карты сайта, пока она не будет повторно просканирована и деиндексирована поисковыми роботами. В противном случае деиндексация может занять больше времени, чем ожидалось.
3) Защитите страницы, содержащие конфиденциальные данные, с помощью паролей. Защита паролем — самый надежный способ скрыть конфиденциальный контент даже от тех ботов, которые не следуют инструкциям robots.txt. Поисковые системы не знают ваших паролей, поэтому они не попадут на страницу, не увидят конфиденциальный контент и не выведут страницу в SERP.
4) Чтобы поисковые роботы не индексировали саму страницу, но переходили по всем ссылкам на странице и индексировали содержимое по этим URL-адресам, настройте следующую директиву
<meta name="robots" content="noindex, follow">
Это обычная практика для страниц результатов внутреннего поиска, которые содержат много полезных ссылок, но сами по себе не несут никакой ценности.
5) Ограничения индексации могут быть указаны для конкретного робота. Например, вы можете заблокировать свою страницу от новостных ботов, ботов изображений и т. д. Имена ботов могут быть указаны для любого типа инструкций, будь то файл robots.txt, метатег robots или X-Robots-Tag.
Например, вы можете скрыть свои страницы специально от бота ChatGPT с помощью robots.txt. После объявления плагинов ChatGPT и GPT-4 (что означает, что OpenAI теперь может получать информацию из Интернета) владельцы веб-сайтов были обеспокоены использованием своего контента. Вопросы цитирования, плагиата и авторских прав стали актуальными для многих сайтов.
Теперь мир SEO раскололся: одни говорят, что нам следует заблокировать доступ GPTBot к нашим сайтам, другие говорят обратное, а третьи говорят, что нам нужно подождать, пока что-то не прояснится. В любом случае, у вас есть выбор.
И если вы твердо уверены, что вам необходимо заблокировать GPTBot, вот как это можно сделать:
Если вы хотите закрыть весь свой сайт.
Пользовательский агент: GPTBot
Запретить: /
Если вы хотите закрыть только определенную часть вашего сайта.
Пользовательский агент: GPTBot
Разрешить: /directory-1/
Запретить: /directory-2/
6) Не используйте тег noindex в A/B-тестах, когда часть ваших пользователей перенаправляется со страницы A на страницу B. Так как если noindex сочетается с 301 (постоянным) редиректом, то поисковые системы получат следующие сигналы:
В результате обе страницы А и Б исчезают из индекса.
Чтобы правильно настроить A/B-тест, используйте 302-редирект (временный) вместо 301. Это позволит поисковым системам сохранить старую страницу в индексе и вернуть ее по завершении теста. Если вы тестируете несколько версий страницы (A/B/C/D и т. д.), то используйте тег rel=canonical, чтобы отметить каноническую версию страницы, которая должна попасть в SERP.
7) Используйте тег noindex, чтобы скрыть временные целевые страницы. Если вы скрываете страницы со специальными предложениями, рекламные страницы, скидки или любой другой тип контента, который не должен просачиваться, то запрет этого контента с помощью файла robots.txt — не лучшая идея. Поскольку сверхлюбопытные пользователи все равно могут просматривать эти страницы в вашем файле robots.txt. Использование noindex в этом случае лучше, чтобы случайно не скомпрометировать «секретный» URL-адрес в открытом доступе.
Теперь вы знаете основы того, как найти и скрыть определенные страницы вашего сайта от внимания ботов поисковых систем. И, как видите, процесс на самом деле простой. Просто не смешивайте несколько типов инструкций на одной странице и будьте осторожны, чтобы не скрыть страницы, которые должны отображаться в поиске.
Я что-то пропустил? Поделитесь своими вопросами в комментариях.
| Linking websites | N/A |
| Backlinks | N/A |
| InLink Rank | N/A |








