39427
•
10 minutes de lecture
•


L'indexation des pages du site est le point de départ du processus d'optimisation des moteurs de recherche. Laisser les robots des moteurs accéder à votre contenu signifie que vos pages sont prêtes à accueillir les visiteurs, qu'elles ne présentent aucun problème technique et que vous souhaitez qu'elles apparaissent dans les SERP. Une indexation complète semble donc être un énorme avantage à première vue.
Cependant, certains types de pages doivent être tenus à l'écart des SERP pour sécuriser votre classement. Cela signifie que vous devez les cacher de l'indexation. Dans cet article, je vais vous guider à travers les types de contenu à cacher aux moteurs de recherche et vous montrer comment procéder.
Passons aux choses sérieuses sans plus attendre. Voici la liste des pages qu'il vaut mieux cacher aux moteurs de recherche, pour ne pas les faire apparaître dans les SERP.
La protection du contenu contre le trafic de recherche direct est indispensable lorsqu'une page contient des informations personnelles. Il s'agit des pages contenant des informations confidentielles sur l'entreprise, des informations sur les produits Alpha, des informations sur les profils des utilisateurs, de la correspondance privée, des données de paiement, etc. Comme le contenu privé doit être caché à toute autre personne que le propriétaire des données, Google (ou tout autre moteur de recherche) ne doit pas rendre ces pages visibles à un public plus large.
Si un formulaire de connexion n'est pas placé sur une page d'accueil mais sur une page distincte, il n'est pas vraiment nécessaire d'afficher cette page dans les SERP. De telles pages n'apportent aucune valeur ajoutée aux utilisateurs, ce qui peut être considéré comme un contenu léger.
Il s'agit des pages que les utilisateurs voient après une action réussie sur un site Web, qu'il s'agisse d'un achat, d'une inscription ou de toute autre action. Ces pages sont également susceptibles d'avoir un contenu peu riche et d'apporter peu ou pas de valeur ajoutée aux internautes.
Le contenu de ce type de pages duplique celui des pages principales de votre site Web, ce qui signifie que ces pages seraient traitées comme des doublons de contenu total si elles étaient explorées et indexées.
Il s'agit d'un problème courant pour les grands sites de commerce électronique qui proposent de nombreux produits qui ne diffèrent que par la taille ou la couleur. Google peut ne pas réussir à faire la différence entre ces produits et les traiter comme des doublons de contenu.
Lorsque les utilisateurs accèdent à votre site Web à partir des SERP, ils s'attendent à cliquer sur votre lien et à trouver la réponse à leur requête. Pas une autre SERP interne avec un tas de liens. Donc, si vos SERP internes parviennent à être indexées, elles n'apporteront probablement rien d'autre qu'un temps passé sur la page réduit et un taux de rebond élevé.
Si votre blog contient tous les articles écrits par un seul auteur, alors la page biographique de l'auteur est une pure copie de la page d'accueil d'un blog.
Tout comme les pages de connexion, les formulaires d'abonnement ne contiennent généralement rien d'autre que le formulaire de saisie de vos données pour vous inscrire. Ainsi, la page a) est vide, b) n'offre aucune valeur aux utilisateurs. C'est pourquoi vous devez empêcher les moteurs de recherche de les intégrer aux SERP.
Règle générale: les pages en cours de développement doivent être tenues à l’écart des robots d’exploration des moteurs de recherche jusqu’à ce qu’elles soient entièrement prêtes à accueillir les visiteurs.
Les pages miroir sont des copies identiques de vos pages sur un serveur/emplacement distinct. Elles seront considérées comme des doublons techniques si elles sont explorées et indexées.
Les offres spéciales et les pages publicitaires ne sont censées être visibles par les utilisateurs qu'après avoir effectué des actions spéciales ou pendant une certaine période (offres spéciales, événements, etc.). Une fois l'événement terminé, ces pages ne doivent plus être visibles par qui que ce soit, y compris par les moteurs de recherche.
Et maintenant, la question est: comment cacher toutes les pages mentionnées ci-dessus aux araignées embêtantes et garder le reste de votre site Web visible comme il se doit?
Lorsque vous définissez les instructions pour les moteurs de recherche, vous avez deux options: vous pouvez restreindre l'exploration ou l'indexation d'une page.
Le moyen le plus simple et le plus direct d'empêcher les robots d'exploration des moteurs de recherche d'accéder à vos pages est probablement de créer un fichier robots.txt. Les fichiers robots.txt vous permettent de bloquer de manière proactive tout contenu indésirable des résultats de recherche. Avec ce fichier, vous pouvez restreindre l'accès à une seule page, à un répertoire entier ou même à une seule image ou à un seul fichier.


La procédure est assez simple. Il suffit de créer un fichier.txt contenant les champs suivants:
Notez que certains robots d'exploration (par exemple Google) prennent également en charge un champ supplémentaire appelé Autoriser:. Comme son nom l'indique, Autoriser: vous permet de lister explicitement les fichiers/dossiers qui peuvent être explorés.
Voici quelques exemples de base de fichiers robots.txt expliqués.


* dans la ligne User-agent signifie que tous les robots des moteurs de recherche ont pour instruction de ne pas explorer les pages de votre site, ce qui est indiqué par /. C'est probablement ce que vous préféreriez éviter, mais maintenant vous avez compris l'idée.


En utilisant l'exemple ci-dessus, vous empêchez le robot d'imagerie de Google d'explorer vos images dans le répertoire sélectionné.
Vous trouverez plus d'instructions sur la façon d' écrire ces fichiers manuellement dans le guide du développeur Google.
Mais le processus de création d'un fichier robots.txt peut être entièrement automatisé: il existe une large gamme d'outils capables de créer de tels fichiers. Par exemple, WebSite Auditor peut facilement compiler un fichier robots.txt pour votre site Web.
Lorsque vous lancez l'outil et créez un projet pour votre site Web, accédez à Structure du site > Pages, cliquez sur l'icône en forme de clé et sélectionnez Robots.txt.
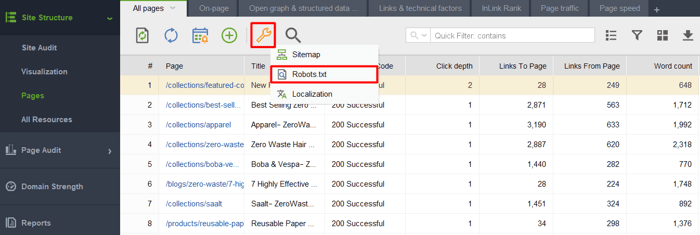
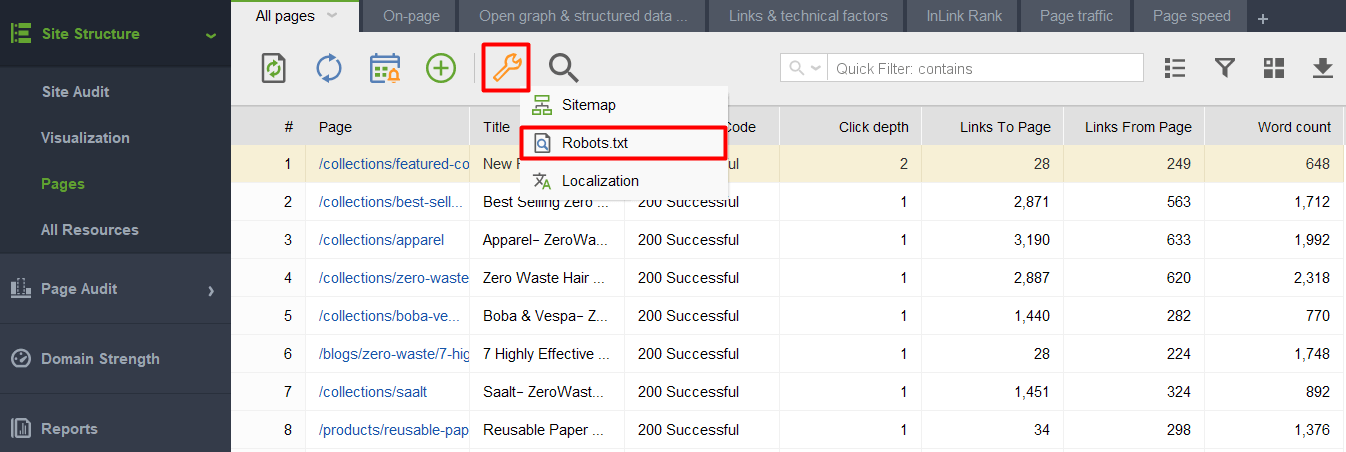
Cliquez ensuite sur Ajouter une règle et spécifiez les instructions. Choisissez un robot de recherche et un répertoire ou une page pour lesquels vous souhaitez restreindre l'exploration.

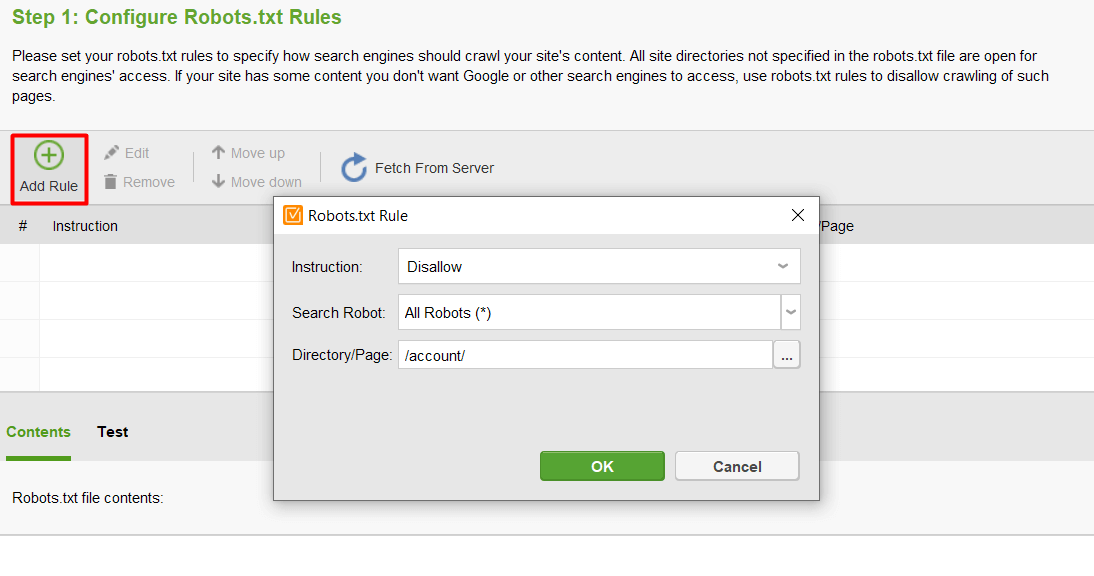
Une fois que vous avez terminé tous vos paramètres, cliquez sur Suivant pour laisser l'outil générer un fichier robots.txt que vous pouvez ensuite télécharger sur votre site Web.
Pour voir les ressources bloquées à l'exploration et vous assurer que vous n'avez rien interdit qui devrait être exploré, accédez à Structure du site > Audit du site et vérifiez la section Ressources interdites à l'indexation:
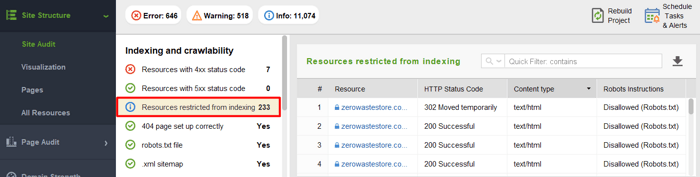

De plus, n'oubliez pas que le protocole robots.txt est purement consultatif. Il ne s'agit pas d'un verrou sur les pages de votre site, mais plutôt d'une sorte de « Privé - ne pas entrer ». Robots.txt peut empêcher les robots « respectueux des lois » (par exemple les robots Google, Yahoo! et Bing) d'accéder à votre contenu. Cependant, les robots malveillants l'ignorent tout simplement et parcourent votre contenu de toute façon. Il existe donc un risque que vos données privées soient récupérées, compilées et réutilisées sous couvert d'utilisation équitable. Si vous souhaitez que votre contenu soit 100 % sûr, vous devez mettre en place des mesures plus sécurisées (par exemple, ajouter une inscription sur un site, masquer le contenu sous un mot de passe, etc.).
Voici les erreurs les plus courantes que les gens font lors de la création de fichiers robots.txt. Lisez attentivement cette partie.
1) Utiliser des majuscules dans le nom du fichier. Le nom du fichier est robots.txt. Point final. Pas Robots.txt, ni ROBOTS.txt
2) Ne pas placer le fichier robots.txt dans le répertoire principal
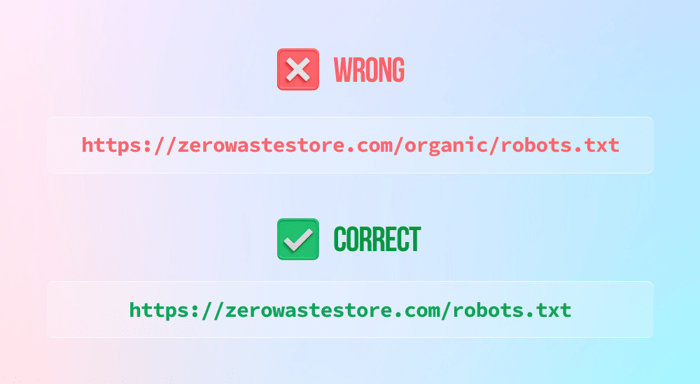

3) Bloquer l'intégralité de votre site Web (sauf si vous le souhaitez) en laissant l'instruction d'interdiction de la manière suivante


4) Spécification incorrecte de l'agent utilisateur


5) Il est interdit de mentionner plusieurs catalogues par ligne. Chaque page ou répertoire doit avoir une ligne distincte


6) Laisser la ligne user-agent vide
7) Lister tous les fichiers d'un répertoire. Si vous cachez l'intégralité du répertoire, vous n'avez pas besoin de répertorier chaque fichier individuellement.


8) Ne pas mentionner du tout la ligne d'instructions d'interdiction


9) Ne pas indiquer le plan du site au bas du fichier robots.txt
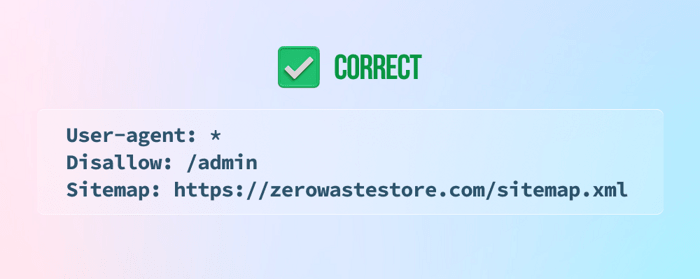

10) Ajout d'instructions noindex au fichier
L'utilisation d'une balise méta robots noindex ou de la balise X-Robots permettra aux robots des moteurs de recherche d'explorer et d'accéder à votre page, mais empêchera la page d'entrer dans l'index, c'est-à-dire d'apparaître dans les résultats de recherche.
Regardons maintenant de plus près chaque option.
Une balise méta robots noindex est placée dans la source HTML de votre page (section <head>). Le processus de création de ces balises ne nécessite qu'un minimum de connaissances techniques et peut être facilement réalisé même par un SEO junior.
Lorsque le robot Google récupère la page, il voit une balise méta noindex et n'inclut pas cette page dans l'index Web. La page est toujours explorée et existe à l'URL donnée, mais n'apparaîtra pas dans les résultats de recherche, quelle que soit la fréquence à laquelle elle est liée à partir d'une autre page.
<meta name="robots" content="index, suivre">
L'ajout de cette balise méta dans la source HTML de votre page indique à un robot de moteur de recherche d'indexer cette page et tous les liens provenant de cette page.
<meta name="robots" content="index, nofollow">
En remplaçant « follow » par « nofollow », vous influencez le comportement d'un robot de moteur de recherche. La configuration de balise mentionnée ci-dessus indique à un moteur de recherche d'indexer une page mais de ne pas suivre les liens qui y sont placés.
<meta name="robots" content="noindex, follow">
Cette balise méta indique au robot d'un moteur de recherche d'ignorer la page sur laquelle elle est placée, mais de suivre tous les liens qui y sont placés.
<meta name="robots" content="noindex, nofollow">
Cette balise placée sur une page signifie que ni la page ni les liens que cette page contient ne seront suivis ou indexés.
Outre une balise méta robots noindex, vous pouvez masquer une page en configurant une réponse d'en-tête HTTP avec une balise X-Robots avec une valeur noindex ou none.
En plus des pages et des éléments HTML, X-Robots-Tag vous permet d'indexer séparément des fichiers PDF, des vidéos, des images ou tout autre fichier non HTML pour lequel l'utilisation de balises méta robots n'est pas possible.
Le mécanisme est assez similaire à celui d'une balise noindex. Lorsqu'un robot de recherche accède à une page, la réponse HTTP renvoie un en-tête X-Robots-Tag avec des instructions noindex. Une page ou un fichier est toujours exploré, mais n'apparaît pas dans les résultats de recherche.
Il s’agit de l’exemple le plus courant de réponse HTTP avec l’instruction de ne pas indexer une page.
HTTP/1.1 200 OK
(…)
X-Robots-Tag: noindex
(…)
Vous pouvez spécifier le type de robot de recherche si vous devez masquer votre page à certains robots. L'exemple ci-dessous montre comment masquer une page à tout autre moteur de recherche que Google et empêcher tous les robots de suivre les liens de cette page:
X-Robots-Tag: googlebot: nofollow
X-Robots-Tag: autrebot: noindex, nofollow
Si vous ne spécifiez pas le type de robot, les instructions seront valables pour tous les types de robots.
Pour restreindre l'indexation de certains types de fichiers sur l'ensemble de votre site Web, vous pouvez ajouter les instructions de réponse X-Robots-Tag aux fichiers de configuration du logiciel serveur Web de votre site.
Voici comment restreindre tous les fichiers PDF sur un serveur basé sur Apache:
<Fichiers ~ "\.pdf$">
Ensemble d'en-têtes X-Robots-Tag "noindex, nofollow"
</Fichiers>
Et voici les mêmes instructions pour NGINX:
emplacement ~* \.pdf$ {
ajouter_en-tête X-Robots-Tag "noindex, nofollow";
}
Pour restreindre l'indexation d'un seul élément, le modèle est le suivant pour Apache:
# le fichier htaccess doit être placé dans le répertoire du fichier correspondant.
<Fichiers "licorne.pdf">
Ensemble d'en-têtes X-Robots-Tag "noindex, nofollow"
</Fichiers>
Et voici comment restreindre l’indexation d’un élément pour NGINX:
emplacement = /secrets/unicorn.pdf {
ajouter_en-tête X-Robots-Tag "noindex, nofollow";
}
Bien qu'une balise robots noindex semble être une solution plus simple pour empêcher l'indexation de vos pages, il existe certains cas où l'utilisation d'une balise X-Robots pour les pages est une meilleure option:
Cependant, n'oubliez pas que seul Google suit à la lettre les instructions de la balise X-Robots. Quant aux autres moteurs de recherche, rien ne garantit qu'ils interprètent correctement la balise. Par exemple, Seznam ne prend pas du tout en charge les balises x-robots. Par conséquent, si vous prévoyez que votre site Web apparaisse sur plusieurs moteurs de recherche, vous devrez utiliser une balise robots noindex dans les extraits HTML.
Les erreurs les plus courantes commises par les utilisateurs lorsqu'ils travaillent avec les balises noindex sont les suivantes:
1) Ajout d'une page ou d'un élément non indexé au fichier robots.txt. Robots.txt restreint l'exploration, ainsi les robots de recherche ne parviendront pas sur la page et ne verront pas les directives noindex. Cela signifie que votre page peut être indexée sans contenu et apparaître quand même dans les résultats de recherche.
Pour vérifier si l'un de vos documents avec une balise noindex est entré dans le fichier robots.txt, vérifiez la colonne Instructions Robots dans la section Structure du site > Pages de WebSite Auditor.
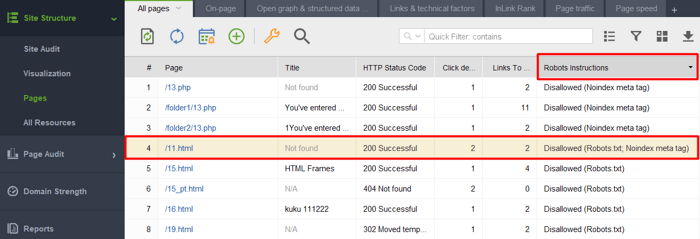
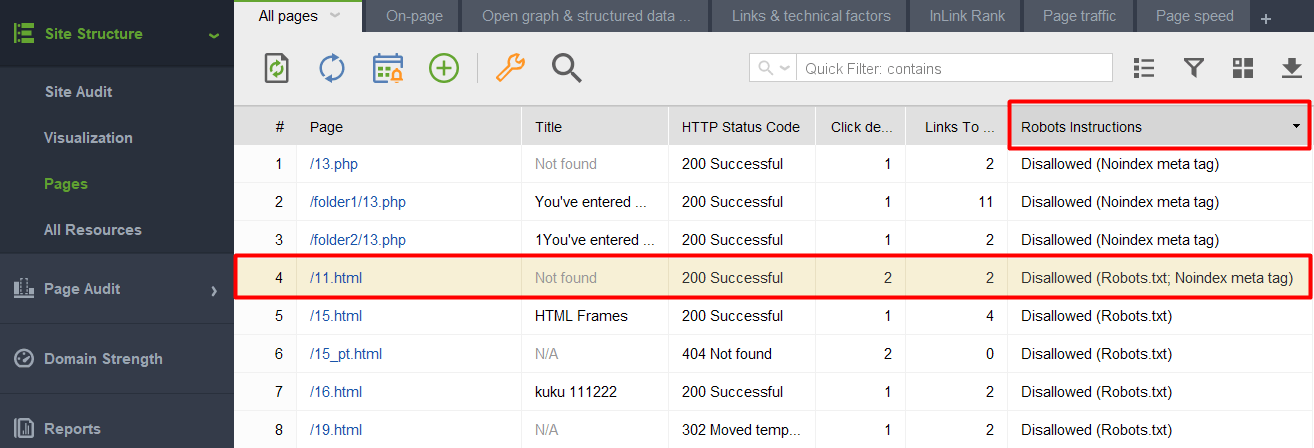
Remarque: n'oubliez pas d'activer les options expert et de décocher l'option Suivre les instructions robots.txt lors de l'assemblage de votre projet pour que l'outil voie les instructions mais ne les suive pas.
2) Utilisation des majuscules dans les directives de balises. Selon Google, toutes les directives sont sensibles à la casse, alors soyez prudent.
Maintenant que tout est plus ou moins clair avec les principaux problèmes d'indexation de contenu, passons à plusieurs cas non standard qui méritent une mention spéciale.
1) Assurez-vous que les pages que vous ne souhaitez pas indexer ne sont pas incluses dans votre plan de site. Un plan de site est en fait le moyen d'indiquer aux moteurs de recherche où aller en premier lors de l'exploration de votre site Web. Et il n'y a aucune raison de demander aux robots de recherche de visiter les pages que vous ne souhaitez pas qu'ils voient.
2) Cependant, si vous devez désindexer une page déjà présente dans le plan du site, ne supprimez pas une page du plan du site avant qu'elle ne soit à nouveau explorée et désindexée par les robots de recherche. Dans le cas contraire, la désindexation peut prendre plus de temps que prévu.
3) Protégez les pages contenant des données privées avec des mots de passe. La protection par mot de passe est le moyen le plus fiable de cacher le contenu sensible même aux robots qui ne suivent pas les instructions du fichier robots.txt. Les moteurs de recherche ne connaissent pas vos mots de passe, ils n'accèderont donc pas à la page, ne verront pas le contenu sensible et n'amèneront pas la page dans une SERP.
4) Pour que les robots de recherche n'indexent pas la page elle-même mais suivent tous les liens d'une page et indexent le contenu de ces URL, configurez la directive suivante
<meta name="robots" content="noindex, follow">
Il s'agit d'une pratique courante pour les pages de résultats de recherche internes, qui contiennent de nombreux liens utiles mais n'ont aucune valeur en elles-mêmes.
5) Des restrictions d'indexation peuvent être spécifiées pour un robot spécifique. Par exemple, vous pouvez verrouiller votre page contre les robots de news, les robots d'images, etc. Les noms des robots peuvent être spécifiés pour tout type d'instructions, qu'il s'agisse d'un fichier robots.txt, d'une balise méta robots ou d'une balise X-Robots.
Par exemple, vous pouvez masquer vos pages spécifiquement au bot ChatGPT avec robots.txt. Depuis l'annonce des plugins ChatGPT et de GPT-4 (qui signifie qu'OpenAI peut désormais obtenir des informations sur le Web), les propriétaires de sites Web s'inquiètent de l'utilisation de leur contenu. Les problèmes de citation, de plagiat et de droits d'auteur sont devenus aigus pour de nombreux sites.
Le monde du SEO est désormais divisé: certains disent qu'il faut bloquer l'accès de GPTBot à nos sites, d'autres disent le contraire, et d'autres encore disent qu'il faut attendre que les choses se précisent. Dans tous les cas, vous avez le choix.
Et si vous croyez fermement que vous devez bloquer GPTBot, voici comment vous pouvez le faire:
Si vous souhaitez fermer tout votre site.
Agent utilisateur: GPTBot
Interdire: /
Si vous souhaitez fermer uniquement une partie particulière de votre site.
Agent utilisateur: GPTBot
Autoriser: /répertoire-1/
Interdire: /directory-2/
6) N'utilisez pas de balise noindex dans les tests A/B lorsqu'une partie de vos utilisateurs est redirigée de la page A vers la page B. Comme si noindex était combiné avec une redirection 301 (permanente), les moteurs de recherche recevraient les signaux suivants:
En conséquence, les deux pages A et B disparaissent de l’index.
Pour configurer correctement votre test A/B, utilisez une redirection 302 (qui est temporaire) au lieu de 301. Cela permettra aux moteurs de recherche de conserver l'ancienne page dans l'index et de la récupérer une fois le test terminé. Si vous testez plusieurs versions d'une page (A/B/C/D, etc.), utilisez la balise rel=canonical pour marquer la version canonique d'une page qui doit apparaître dans les SERP.
7) Utilisez une balise noindex pour masquer les pages de destination temporaires. Si vous masquez des pages avec des offres spéciales, des pages publicitaires, des remises ou tout type de contenu qui ne doit pas être divulgué, interdire ce contenu avec un fichier robots.txt n'est pas la meilleure idée. Les utilisateurs très curieux peuvent toujours consulter ces pages dans votre fichier robots.txt. Dans ce cas, il est préférable d'utiliser noindex, afin de ne pas compromettre accidentellement l'URL « secrète » en public.
Vous connaissez désormais les bases pour trouver et masquer certaines pages de votre site Web afin de les empêcher d'être repérées par les robots des moteurs de recherche. Et comme vous pouvez le constater, le processus est en fait simple. Il suffit de ne pas mélanger plusieurs types d'instructions sur une seule page et de faire attention à ne pas masquer les pages qui doivent apparaître dans la recherche.
Ai-je oublié quelque chose? Partagez vos questions dans les commentaires.
| Linking websites | N/A |
| Backlinks | N/A |
| InLink Rank | N/A |


