38800
•
10 perces olvasás
•


Az oldalak indexelésével kezdődik a keresőoptimalizálási folyamat. Ha engedélyezi a motorbotoknak, hogy hozzáférjenek a tartalomhoz, az azt jelenti, hogy oldalai készen állnak a látogatók számára, nincsenek technikai problémáik, és szeretné, hogy megjelenjenek a SERP-ben, így a mindenre kiterjedő indexelés első látásra hatalmas előnynek tűnik.
Azonban bizonyos típusú oldalakat jobb távol tartani a SERP-től, hogy megőrizze a helyezést. Ez azt jelenti, hogy el kell rejtenie őket az indexelés elől. Ebben a bejegyzésben végigvezetem azon tartalomtípusokon, amelyeket el kell rejteni a keresőmotorok elől, és megmutatom, hogyan kell ezt megtenni.
Térjünk bele minden további nélkül az üzletbe. Íme azoknak az oldalaknak a listája, amelyeket érdemesebb elrejteni a keresőmotorok elől, hogy ne jelenjenek meg a SERP-ekben.
A tartalom védelme a közvetlen keresési forgalomtól kötelező, ha egy oldal személyes adatokat tartalmaz. Ezek azok az oldalak, amelyek bizalmas cégadatokat, információkat az alfa termékekről, felhasználói profilok információit, privát levelezést, fizetési adatokat stb. tartalmaznak. Mivel a privát tartalmat az adattulajdonoson kívül senki más elől el kell rejteni, a Google (vagy bármely keresőmotor) ne tegye láthatóvá ezeket az oldalakat szélesebb közönség számára.
Abban az esetben, ha a bejelentkezési űrlapot nem egy kezdőlapon, hanem egy külön oldalon helyezik el, nincs igazán szükség az oldal megjelenítésére a SERP-ben. Az ilyen oldalak nem jelentenek többletértéket a felhasználók számára, ami vékony tartalomnak tekinthető.
Ezek azok az oldalak, amelyeket a felhasználók egy webhelyen végrehajtott sikeres művelet után látnak, legyen az vásárlás, regisztráció vagy bármi más. Ezek az oldalak valószínűleg vékony tartalommal is rendelkeznek, és alig vagy egyáltalán nem hordoznak további értéket a keresők számára.
Az ilyen típusú oldalak tartalma megduplázza webhelye fő oldalainak tartalmát, ami azt jelenti, hogy feltérképezés és indexelés esetén ezeket az oldalakat teljes tartalommásodpéldányként kezeljük.
Ez gyakori probléma a nagy e-kereskedelmi webhelyeknél, amelyek sok olyan terméket tartalmaznak, amelyek csak méretükben vagy színükben különböznek egymástól. Előfordulhat, hogy a Google-nak nem sikerül különbséget tennie ezek között, és nem kezeli őket ismétlődő tartalomként.
Amikor a felhasználók SERP-ről érkeznek webhelyére, arra számítanak, hogy rákattintnak a linkre, és megtalálják a választ kérdésükre. Nem egy másik belső SERP egy csomó hivatkozással. Tehát ha a belső SERP-jei indexelődnek, akkor valószínűleg csak alacsony időt és magas visszafordulási arányt fognak hozni.
Ha a blogodban az összes bejegyzést egyetlen szerző írta, akkor a szerző életrajzi oldala a blog kezdőlapjának másodpéldánya.
Hasonlóan a bejelentkezési oldalakhoz, az előfizetési űrlapok általában nem tartalmaznak mást, mint az adatbeviteli űrlapot az előfizetéshez. Így az a) oldal üres, b) nem ad értéket a felhasználóknak. Ezért kell korlátoznia, hogy a keresőmotorok SERP-re húzzák őket.
Ökölszabály: a fejlesztés alatt álló oldalakat távol kell tartani a keresőrobotoktól, amíg teljesen készen nem állnak a látogatók rendelkezésére.
A tükrözött oldalak az oldalak azonos másolatai egy külön szerveren/helyen. Feltérképezés és indexelés esetén technikai ismétlődésnek minősülnek.
Az akciós ajánlatok és a hirdetési oldalak csak akkor jelennek meg a felhasználók számára, ha speciális műveleteket hajtanak végre, vagy egy bizonyos időtartamon belül (különleges ajánlatok, események stb.). Az esemény befejeztével ezeket az oldalakat senkinek sem kell látnia, beleértve a keresőket sem.
És most a kérdés: hogyan lehet elrejteni az összes fent említett oldalt a bosszantó pókoktól, és hogyan lehet webhelye többi részét láthatóvá tenni, ahogy annak lennie kell?
A keresőmotoroknak szóló utasítások beállítása során két lehetőség közül választhat. Korlátozhatja a feltérképezést, vagy korlátozhatja az oldal indexelését.
Valószínűleg a legegyszerűbb és legközvetlenebb módja annak, hogy korlátozza a keresőrobotok hozzáférését az oldalaihoz, ha létrehoz egy robots.txt fájlt. A Robots.txt fájlok segítségével proaktívan távol tarthatja a nem kívánt tartalmat a keresési eredmények közül. Ezzel a fájllal korlátozhatja a hozzáférést egyetlen oldalra, egy teljes könyvtárra, vagy akár egyetlen képre vagy fájlra.


Az eljárás meglehetősen egyszerű. Csak hozzon létre egy.txt fájlt, amely a következő mezőket tartalmazza:
Vegye figyelembe, hogy egyes feltérképező robotok (például a Google) egy további Engedélyezés mezőt is támogatnak:. Ahogy a neve is sugallja, az Allow: lehetővé teszi a bejárható fájlok/mappák explicit felsorolását.
Íme néhány alapvető példa a robots.txt fájlokra.


* a User-agent sorban azt jelenti, hogy minden keresőrobot arra utasítja, hogy ne térképezze fel webhelye egyik oldalát sem, amit a / jel jelez. Valószínűleg ez az, amit szívesebben kerülne, de most rájött az ötlet.


A fenti példával korlátozza, hogy a Google Image botja feltérképezze a képeket a kiválasztott könyvtárban.
Az ilyen fájlok kézi írására vonatkozó további utasításokat a Google fejlesztői útmutatójában talál.
De a robots.txt létrehozásának folyamata teljesen automatizálható – az ilyen fájlok létrehozására alkalmas eszközök széles skálája létezik. A WebSite Auditor például könnyen összeállíthat egy robots.txt fájlt az Ön webhelyéhez.
Amikor elindítja az eszközt, és létrehoz egy projektet webhelyéhez, lépjen a Webhelyszerkezet > Oldalak menüpontra, kattintson a csavarkulcs ikonra, és válassza ki a Robots.txt fájlt.
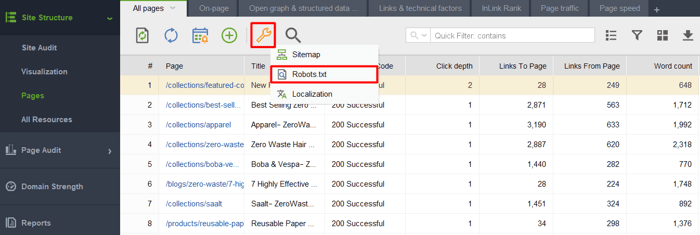
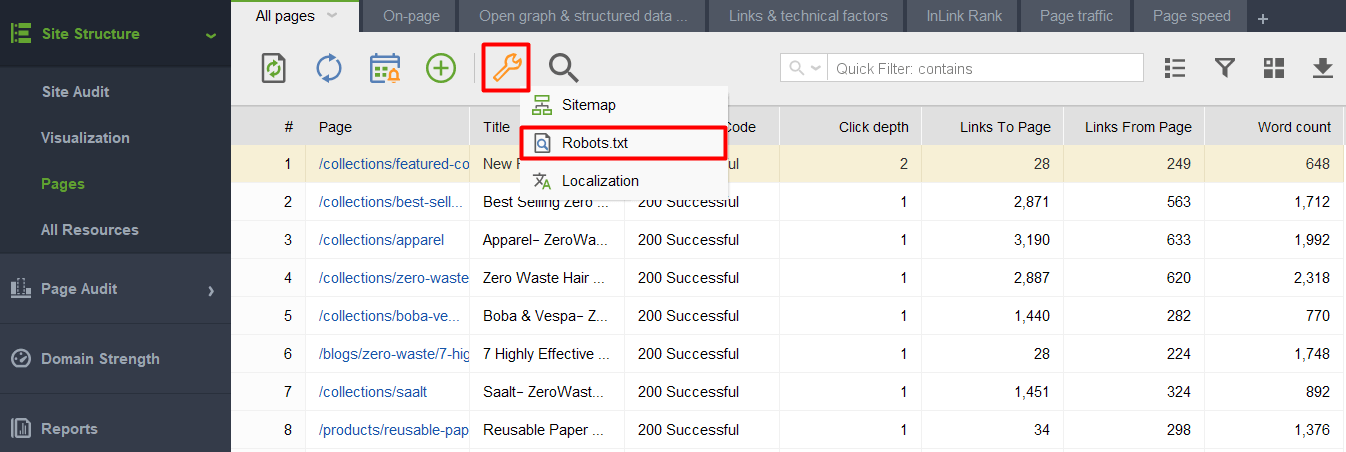
Ezután kattintson a Szabály hozzáadása gombra, és adja meg az utasításokat. Válasszon egy keresőrobotot és egy könyvtárat vagy oldalt, amelynek feltérképezését korlátozni szeretné.

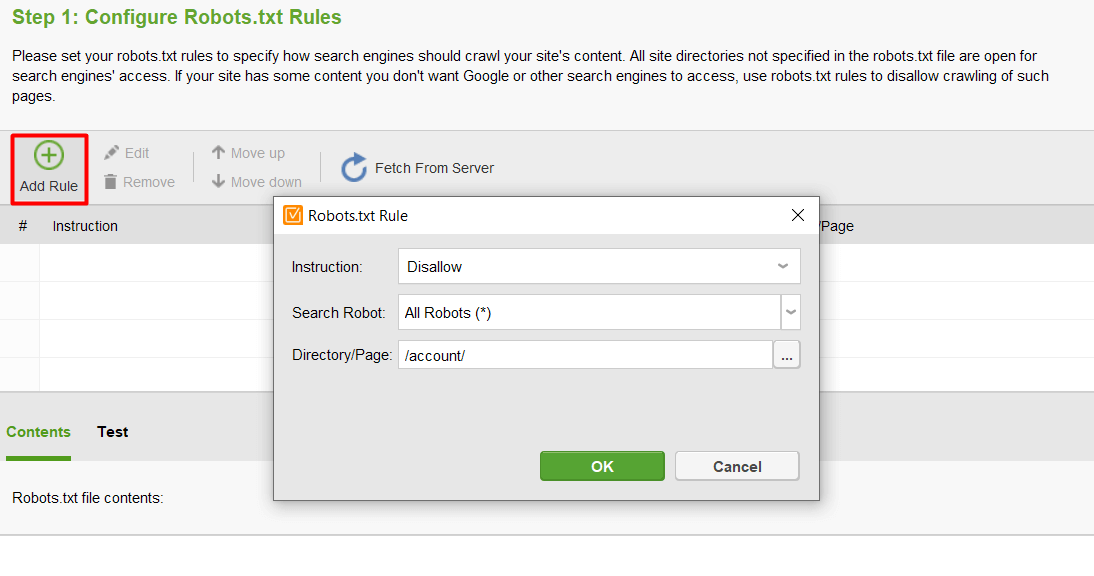
Ha végzett az összes beállítással, kattintson a Tovább gombra, hogy az eszköz létrehozzon egy robots.txt fájlt, amelyet aztán feltölthet webhelyére.
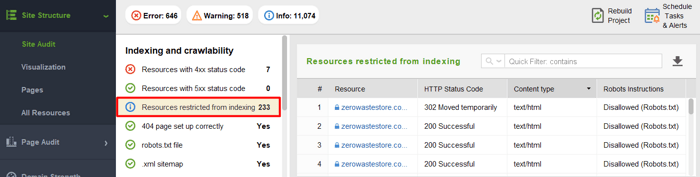
Ha meg szeretné tekinteni a feltérképezésben letiltott erőforrásokat, és megbizonyosodni arról, hogy nem tiltott le semmit, amit fel kellene térképezni, nyissa meg a Webhelyszerkezet > Webhely-ellenőrzés menüpontot, és ellenőrizze az Indexelésben korlátozott erőforrások részt:

Ne feledje továbbá, hogy a robots.txt protokoll pusztán tájékoztató jellegű. Ez nem a webhely oldalainak zárolása, hanem inkább egy "Privát – maradj távol". A Robots.txt megakadályozhatja, hogy a „törvénytisztelő” robotok (pl. Google, Yahoo! és Bing robotok) hozzáférjenek az Ön tartalmához. A rosszindulatú robotok azonban egyszerűen figyelmen kívül hagyják, és így is végigmennek a tartalomon. Fennáll tehát annak a veszélye, hogy személyes adatait a méltányos használat leple alatt lekaparják, összeállítják és újra felhasználják. Ha tartalmait 100%-ban biztonságban szeretné tartani, biztonságosabb intézkedéseket kell bevezetnie (pl. regisztráció hozzáadása egy webhelyen, tartalom elrejtése jelszó alá stb.).
Íme, a robots.txt fájlok létrehozásakor elkövetett leggyakoribb hibák. Olvassa el figyelmesen ezt a részt.
1) Használjon nagybetűt a fájlnévben. A fájl neve robots.txt. Időszak. Nem Robots.txt, és nem ROBOTS.txt
2) Nem helyezi el a robots.txt fájlt a főkönyvtárba
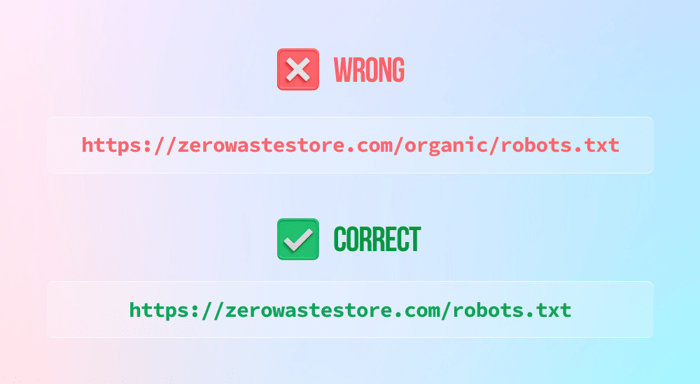

3) A teljes webhely blokkolása (hacsak nem szeretné) a tiltó utasítás elhagyásával a következő módon


4) A user-agent helytelen megadása


5) Több katalógus említése egy tiltó soronként. Minden oldalnak vagy könyvtárnak külön sorra van szüksége


6) A user-agent sor üresen hagyása
7) Az összes fájl listázása egy könyvtárban. Ha az egész könyvtárat elrejti, akkor nem kell minden egyes fájl felsorolásával bajlódnia.


8) Egyáltalán nem említi a tiltó utasításokat


9) Nincs feltüntetve a webhelytérkép a robots.txt fájl alján
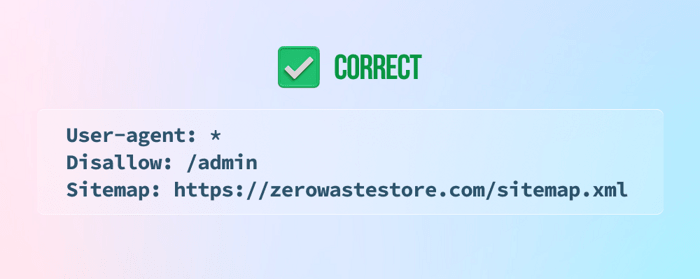

10) Noindex utasítások hozzáadása a fájlhoz
A robots noindex metatag vagy az X-Robots-tag használata lehetővé teszi a keresőrobotok számára, hogy feltérképezzék és hozzáférjenek az oldalához, de megakadályozza, hogy az oldal bekerüljön az indexbe, azaz megjelenjen a keresési eredmények között.
Most nézzük meg közelebbről az egyes lehetőségeket.
A rendszer egy robots noindex metacímkét helyez el az oldal HTML-forrásába (<head> szakasz). A címkék létrehozásának folyamata csak egy kis technikai tudást igényel, és még egy fiatal keresőoptimalizáló is könnyen elvégezheti.
Amikor a Google robot lekéri az oldalt, egy noindex metacímkét lát, és nem veszi fel ezt az oldalt az internetes indexbe. Az oldal továbbra is fel van térképezve, és létezik a megadott URL-címen, de nem jelenik meg a keresési eredmények között, függetlenül attól, hogy milyen gyakran hivatkoznak rá bármely másik oldalról.
<meta name="robots" content="index, follow">
Ha hozzáadja ezt a metacímkét az oldal HTML-forrásához, akkor a keresőrobot utasítja a keresőrobotot, hogy indexelje ezt az oldalt és az oldalról érkező összes hivatkozást.
<meta name="robots" content="index, nofollow">
A „follow” (követés) „nofollow”-ra cserélésével befolyásolja a keresőrobot viselkedését. A fent említett címkekonfiguráció arra utasítja a keresőmotort, hogy indexeljen egy oldalt, de ne kövesse az azon elhelyezett hivatkozásokat.
<meta name="robots" content="noindex, follow">
Ez a metacímke arra utasítja a keresőrobotot, hogy figyelmen kívül hagyja az oldalt, amelyen elhelyezte, de kövesse az összes rajta elhelyezett linket.
<meta name="robots" content="noindex, nofollow">
Ez az oldalon elhelyezett címke azt jelenti, hogy sem az oldalt, sem az ezen az oldalon található hivatkozásokat nem követi és nem indexeli.
A robots noindex metatag mellett elrejthet egy oldalt, ha beállít egy HTTP-fejléc választ egy noindex vagy none értékkel rendelkező X-Robots-Tag-gel.
Az oldalak és HTML-elemek mellett az X-Robots-Tag lehetővé teszi különálló PDF-fájlok, videók, képek vagy bármely más nem HTML-fájl noindexelését, ahol a robots metacímkék használata nem lehetséges.
A mechanizmus nagyjából olyan, mint egy noindex címkéé. Ha egy keresőrobot megérkezik egy oldalra, a HTTP-válasz egy X-Robots-Tag fejlécet ad vissza noindex utasításokkal. Egy oldal vagy fájl továbbra is feltérképezett, de nem jelenik meg a keresési eredmények között.
Ez a leggyakoribb példa a HTTP-válaszra, amely az oldalt ne indexelje.
HTTP/1.1 200 OK
(…)
X-Robots-Tag: noindex
(…)
Megadhatja a keresőrobot típusát, ha el kell rejtenie oldalát bizonyos robotok elől. Az alábbi példa bemutatja, hogyan rejthet el egy oldalt a Google kivételével bármely más keresőmotor elől, és hogyan korlátozhatja az összes botot az oldalon található hivatkozások követésében:
X-Robots-Tag: googlebot: nofollow
X-Robots-Tag: otherbot: noindex, nofollow
Ha nem adja meg a robot típusát, az utasítások minden típusú bejáróra érvényesek.
Ha korlátozni szeretné bizonyos típusú fájlok indexelését a teljes webhelyen, hozzáadhatja az X-Robots-Tag válaszutasításokat webhelye webszerver-szoftverének konfigurációs fájljaihoz.
Így korlátozhatja az összes PDF-fájlt egy Apache-alapú szerveren:
<Fájlok ~ "\.pdf$">
Fejléckészlet X-Robots-Tag "noindex, nofollow"
</Fájlok>
És ezek ugyanazok az utasítások az NGINX-hez:
hely ~* \.pdf$ {
add_header X-Robots-Tag "noindex, nofollow";
}
Egyetlen elem indexelésének korlátozásához a minta a következő Apache esetében:
# a htaccess fájlt az illesztett fájl könyvtárába kell helyezni.
<Fájlok "unicorn.pdf">
Fejléckészlet X-Robots-Tag "noindex, nofollow"
</Fájlok>
És így korlátozhatja egy elem indexelését az NGINX számára:
hely = /titkok/unicorn.pdf {
add_header X-Robots-Tag "noindex, nofollow";
}
Bár a robots noindex címke egyszerűbb megoldásnak tűnik az oldalak indexelésének korlátozására, vannak olyan esetek, amikor az X-Robots-Tag használata az oldalakhoz jobb megoldás:
Ennek ellenére ne feledje, hogy csak a Google követi biztosan az X-Robots-Tag utasításait. Ami a többi keresőmotort illeti, nincs garancia arra, hogy helyesen értelmezik a címkét. Például a Seznam egyáltalán nem támogatja az x-robots-tagokat. Tehát ha azt tervezi, hogy webhelye különböző keresőmotorokban jelenjen meg, akkor a HTML-kódrészletekben egy robots noindex címkét kell használnia.
A következők a leggyakoribb hibák, amelyeket a felhasználók a noindex címkékkel való munka során elkövetnek:
1) Egy noindexelt oldal vagy elem hozzáadása a robots.txt fájlhoz. A Robots.txt korlátozza a feltérképezést, így a keresőrobotok nem jönnek az oldalra, és nem látják a noindex utasításokat. Ez azt jelenti, hogy oldala tartalom nélkül indexelhető, és továbbra is megjelenhet a keresési eredmények között.
Ha ellenőrizni szeretné, hogy a noindex címkével rendelkező papírok valamelyike bekerült-e a robots.txt fájlba, ellenőrizze a Webhely-ellenőrző Webhelyszerkezet > Oldalak részében a Robots utasítások oszlopát.
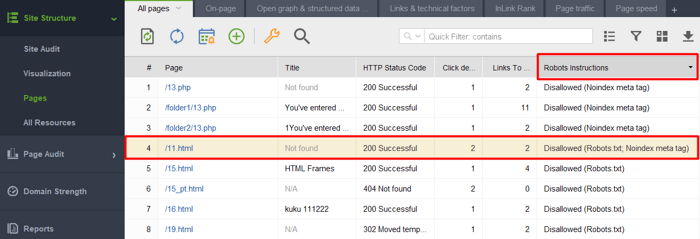
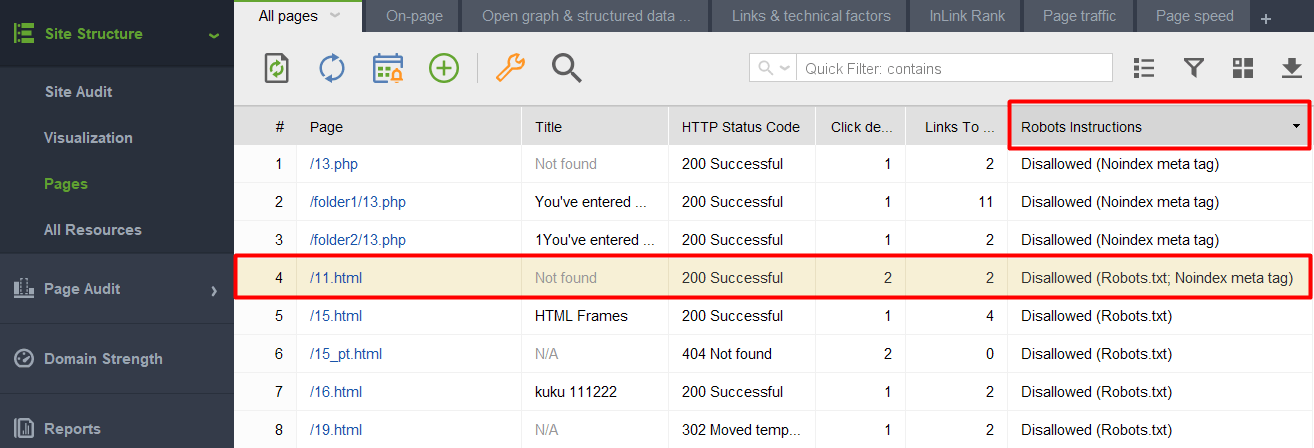
Megjegyzés: Ne felejtse el engedélyezni a szakértői beállításokat, és törölje a jelölést a Robots.txt utasítások követése jelölőnégyzetből a projekt összeállításakor, hogy az eszköz lássa az utasításokat, de ne kövesse azokat.
2) Nagybetűk használata a címke direktívákban. A Google szerint minden utasítás megkülönbözteti a kis- és nagybetűket, ezért legyen óvatos.
Most, hogy minden többé-kevésbé világos a főbb tartalomindexelési problémákkal kapcsolatban, térjünk át néhány nem szabványos esetre, amelyek külön említést érdemelnek.
1) Győződjön meg arról, hogy azok az oldalak, amelyeket nem szeretne indexelni, nem szerepelnek webhelytérképében. A webhelytérkép valójában az a módja, hogy megmondja a keresőmotoroknak, merre induljanak el először a webhely feltérképezésekor. És nincs ok arra kérni a keresőrobotokat, hogy látogassák meg azokat az oldalakat, amelyeket nem szeretne látni.
2) Mégis, ha olyan oldalt kell deindexelnie, amely már szerepel a webhelytérképen, ne távolítson el egy oldalt a webhelytérképről, amíg azt a keresőrobotok újra fel nem térképezték és ki nem indexelték. Ellenkező esetben a deindexálás a vártnál tovább tarthat.
3) Védje jelszavakkal a személyes adatokat tartalmazó oldalakat. A jelszavas védelem a legmegbízhatóbb módja annak, hogy elrejtse az érzékeny tartalmat még azoktól a robotoktól is, amelyek nem követik a robots.txt utasításait. A keresőmotorok nem ismerik a jelszavakat, így nem jutnak el az oldalra, nem látják az érzékeny tartalmat, és nem hozzák az oldalt SERP-be.
4) Ha azt szeretné, hogy a keresőrobotok magát az oldalt noindexeljék, de kövessék az oldalon található összes linket, és indexeljék a tartalmat ezeken az URL-eken, állítsa be a következő direktívát
<meta name="robots" content="noindex, follow">
Ez bevett gyakorlat a belső keresési eredményoldalakon, amelyek sok hasznos linket tartalmaznak, de önmagukban nem hordoznak értéket.
5) Egy adott robothoz indexelési korlátozások adhatók meg. Például lezárhatja oldalát a hírrobotok, képrobotok stb. elől. A robotok neve bármilyen típusú utasításhoz megadható, legyen az robots.txt fájl, robots metacímke vagy X-Robots-Tag.
Például elrejtheti oldalait kifejezetten a ChatGPT bot elől a robots.txt segítségével. A ChatGPT-bővítmények és a GPT-4 bejelentése óta (ami azt jelenti, hogy az OpenAI immár információkat kaphat az internetről), a webhelyek tulajdonosai aggódnak tartalmuk felhasználása miatt. A hivatkozások, a plágium és a szerzői jogok kérdése számos webhely számára akut jelentőségűvé vált.
A SEO világa most megosztott: egyesek szerint blokkolnunk kellene a GPTBot-ot, hogy hozzáférjen oldalainkhoz, mások szerint az ellenkezőjét, a harmadikak szerint pedig várnunk kell, amíg valami világossá válik. Mindenesetre van választásod.
És ha határozottan úgy gondolja, hogy le kell tiltania a GPTBotot, a következőképpen teheti meg:
Ha be szeretné zárni az egész webhelyet.
Felhasználói ügynök: GPTBot
Letiltás: /
Ha webhelyének csak egy bizonyos részét szeretné bezárni.
Felhasználói ügynök: GPTBot
Engedélyezés: /könyvtár-1/
Disallow: /könyvtár-2/
6) Ne használjon noindex címkét az A/B teszteknél, amikor a felhasználók egy részét átirányítják az A oldalról a B oldalra. Mintha a noindex 301-es (állandó) átirányítással lenne kombinálva, akkor a keresőmotorok a következő jelzéseket kapják:
Ennek eredményeként mind az A, mind a B oldal eltűnik az indexből.
Az A/B-teszt megfelelő beállításához használjon 302-es átirányítást (amely ideiglenes) 301 helyett. Ez lehetővé teszi a keresőmotorok számára, hogy a régi oldalt indexben tartsák, és a teszt befejezésekor visszahozzák. Ha egy oldal több verzióját teszteli (A/B/C/D stb.), akkor a rel=canonical címkével jelölje meg az oldal gyűjtőverzióját, amelynek be kell kerülnie a SERP-be.
7) Használjon noindex címkét az ideiglenes céloldalak elrejtéséhez. Ha különleges ajánlatokat, hirdetési oldalakat, kedvezményeket vagy bármilyen olyan tartalmat rejt el, amelynek nem szabad kiszivárognia, akkor nem a legjobb ötlet a tartalom letiltása egy robots.txt fájl segítségével. A rendkívül kíváncsi felhasználók továbbra is megtekinthetik ezeket az oldalakat a robots.txt fájlban. Ebben az esetben jobb a noindex használata, hogy véletlenül se kerüljön veszélybe a „titkos” URL nyilvánosan.
Most már ismeri az alapokat, hogyan kereshet meg és rejthet el webhelye bizonyos oldalait a keresőrobotok figyelme elől. És amint látja, a folyamat valójában egyszerű. Csak ne keverjen többféle utasítást egyetlen oldalon, és legyen óvatos, nehogy elrejtse azokat az oldalakat, amelyeknek meg kell jelenniük a keresésben.
Lemaradtam valamiről? Ossza meg kérdéseit a megjegyzésekben.
| Linking websites | N/A |
| Backlinks | N/A |
| InLink Rank | N/A |


