44736
•
Leitura de 10 minutos
•


A indexação de páginas do site é o que o processo de otimização de mecanismos de busca começa. Permitir que robôs de mecanismos acessem seu conteúdo significa que suas páginas estão prontas para visitantes, elas não têm problemas técnicos e você quer que elas apareçam em SERPs, então a indexação abrangente parece um grande benefício à primeira vista.
No entanto, certos tipos de páginas seriam melhor mantidos longe dos SERPs para garantir suas classificações. O que significa que você precisa ocultá-los da indexação. Nesta postagem, vou guiá-lo pelos tipos de conteúdo a serem ocultados dos mecanismos de busca e mostrar como fazer isso.
Vamos direto ao assunto sem mais delongas. Aqui está a lista de páginas que você deve esconder dos mecanismos de busca, para que elas não apareçam nos SERPs.
Proteger o conteúdo do tráfego de pesquisa direta é essencial quando uma página contém informações pessoais. Essas são as páginas com detalhes confidenciais da empresa, informações sobre produtos alfa, informações de perfis de usuários, correspondência privada, dados de pagamento, etc. Como o conteúdo privado deve ser escondido de qualquer outra pessoa, exceto do proprietário dos dados, o Google (ou qualquer mecanismo de busca) não deve tornar essas páginas visíveis para públicos mais amplos.
Caso um formulário de login seja colocado não em uma homepage, mas em uma página separada, não há necessidade real de mostrar essa página em SERPs. Essas páginas não carregam nenhum valor adicional para os usuários, o que pode ser considerado conteúdo superficial.
Essas são as páginas que os usuários veem após uma ação bem-sucedida em um site, seja uma compra, registro ou qualquer outra coisa. Essas páginas também provavelmente têm conteúdo superficial e carregam pouco ou nenhum valor adicional para os pesquisadores.
O conteúdo desse tipo de página duplica o das páginas principais do seu site, o que significa que essas páginas seriam tratadas como duplicatas totais de conteúdo se rastreadas e indexadas.
Este é um problema comum para grandes sites de comércio eletrônico que têm muitos produtos que diferem apenas em tamanho ou cor. O Google pode não conseguir dizer a diferença entre eles e tratá-los como duplicatas de conteúdo.
Quando os usuários vêm ao seu site a partir de SERPs, eles esperam clicar no seu link e encontrar a resposta para a consulta deles. Não outro SERP interno com um monte de links. Então, se seus SERPs internos forem indexados, eles provavelmente não trarão nada além de pouco tempo na página e uma alta taxa de rejeição.
Se o seu blog tiver todas as postagens escritas por um único autor, a página biográfica do autor será uma cópia pura da página inicial do blog.
Assim como as páginas de login, os formulários de assinatura geralmente não apresentam nada além do formulário para inserir seus dados para assinar. Assim, a página a) está vazia, b) não entrega valor aos usuários. É por isso que você tem que restringir os mecanismos de busca de puxá-los para SERPs.
Uma regra prática: páginas que estão em processo de desenvolvimento devem ser mantidas longe dos rastreadores de mecanismos de busca até que estejam totalmente prontas para visitantes.
As páginas espelho são cópias idênticas das suas páginas em um servidor/local separado. Elas serão consideradas duplicatas técnicas se rastreadas e indexadas.
Ofertas especiais e páginas de anúncios devem ficar visíveis para os usuários somente após eles concluírem quaisquer ações especiais ou durante um certo período de tempo (ofertas especiais, eventos, etc.). Após o término do evento, essas páginas não precisam ser vistas por ninguém, incluindo mecanismos de busca.
E agora a questão é: como esconder todas as páginas mencionadas acima dos spiders irritantes e manter o resto do seu site visível como deveria ser?
Ao configurar as instruções para mecanismos de busca, você tem duas opções. Você pode restringir o rastreamento ou pode restringir a indexação de uma página.
Possivelmente, a maneira mais simples e direta de restringir o acesso de rastreadores de mecanismos de busca às suas páginas é criando um arquivo robots.txt. Arquivos robots.txt permitem que você mantenha proativamente todo o conteúdo indesejado fora dos resultados da pesquisa. Com esse arquivo, você pode restringir o acesso a uma única página, um diretório inteiro ou até mesmo uma única imagem ou arquivo.


O procedimento é bem fácil. Você só cria um arquivo.txt que tem os seguintes campos:
Observe que alguns rastreadores (por exemplo, Google) também oferecem suporte a um campo adicional chamado Allow:. Como o nome indica, Allow: permite que você liste explicitamente os arquivos/pastas que podem ser rastreados.
Aqui estão alguns exemplos básicos de arquivos robots.txt explicados.


* na linha User-agent significa que todos os robôs de mecanismos de busca são instruídos a não rastrear nenhuma das páginas do seu site, o que é indicado por /. Provavelmente, é isso que você preferiria evitar, mas agora você entendeu a ideia.


No exemplo acima, você restringe o bot de imagens do Google de rastrear suas imagens no diretório selecionado.
Você pode encontrar mais instruções sobre como escrever esses arquivos manualmente no guia do desenvolvedor do Google.
Mas o processo de criação de robots.txt pode ser totalmente automatizado – há uma ampla gama de ferramentas que são capazes de criar tais arquivos. Por exemplo, o WebSite Auditor pode facilmente compilar um arquivo robots.txt para seu site.
Ao iniciar a ferramenta e criar um projeto para seu site, vá para Estrutura do site > Páginas, clique no ícone de chave inglesa e selecione Robots.txt.
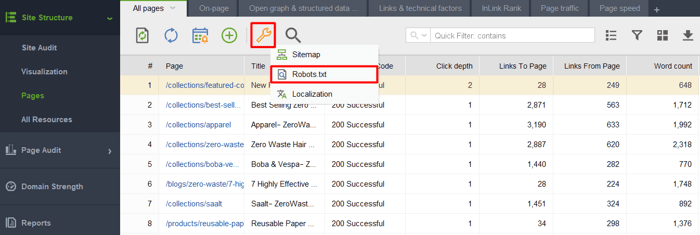
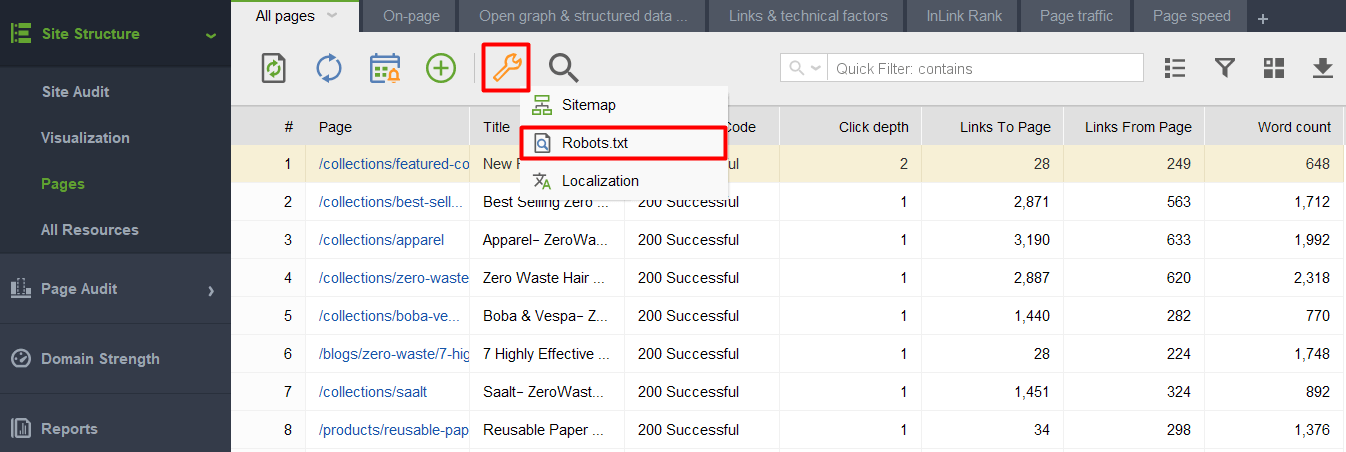
Em seguida, clique em Adicionar regra e especifique as instruções. Escolha um bot de busca e um diretório ou página para o qual você deseja restringir o rastreamento.

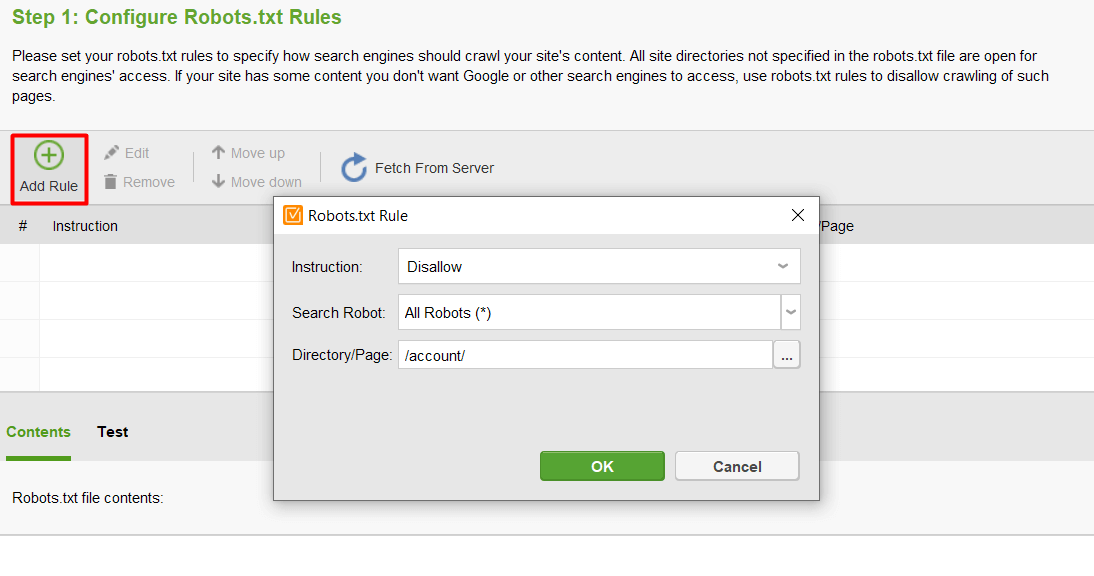
Depois de concluir todas as configurações, clique em Avançar para permitir que a ferramenta gere um arquivo robots.txt que você poderá enviar para seu site.
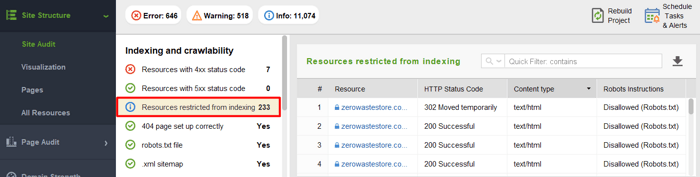
Para ver os recursos bloqueados para rastreamento e certificar-se de que você não desautorizou nada que deveria ser rastreado, vá para Estrutura do Site > Auditoria do Site e verifique a seção Recursos restritos para indexação:

Além disso, lembre-se de que o protocolo robots.txt é puramente consultivo. Não é um bloqueio nas páginas do seu site, mas mais como um "Privado - mantenha fora". O robots.txt pode impedir que bots "cumpridores da lei" (por exemplo, bots do Google, Yahoo! e Bing) acessem seu conteúdo. No entanto, bots maliciosos simplesmente o ignoram e acessam seu conteúdo de qualquer maneira. Portanto, há um risco de que seus dados privados sejam raspados, compilados e reutilizados sob o pretexto de uso justo. Se você quiser manter seu conteúdo 100% seguro, deve introduzir medidas mais seguras (por exemplo, adicionar registro em um site, ocultar conteúdo sob uma senha, etc.).
Aqui estão os erros mais comuns que as pessoas cometem ao criar arquivos robots.txt. Leia esta parte com cuidado.
1) Usando letras maiúsculas no nome do arquivo. O nome do arquivo é robots.txt. Ponto. Não Robots.txt, e não ROBOTS.txt
2) Não colocar o arquivo robots.txt no diretório principal
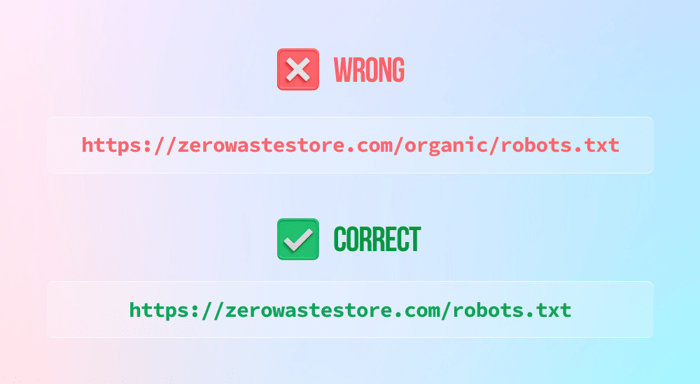

3) Bloquear todo o seu site (a menos que você queira) deixando a instrução de proibição da seguinte maneira


4) Especificar incorretamente o agente do usuário


5) Mencionar vários catálogos por linha de disallow. Cada página ou diretório precisa de uma linha separada


6) Deixar a linha do agente do usuário vazia
7) Listar todos os arquivos dentro de um diretório. Se for o diretório inteiro que você está escondendo, você não precisa se preocupar em listar cada arquivo


8) Não mencionar a linha de instruções de proibição


9) Não informar o mapa do site no final do arquivo robots.txt
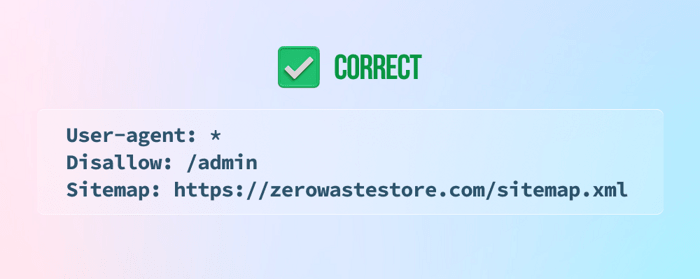

10) Adicionando instruções noindex ao arquivo
Usar uma meta tag robots noindex ou a X-Robots-tag permitirá que os robôs dos mecanismos de busca rastreiem e acessem sua página, mas impedirá que a página entre no índice, ou seja, que apareça nos resultados da pesquisa.
Agora vamos analisar mais detalhadamente cada opção.
Uma meta tag robots noindex é colocada no código-fonte HTML da sua página (seção <head>). O processo de criação dessas tags requer apenas um pouquinho de conhecimento técnico e pode ser feito facilmente até mesmo por um SEO júnior.
Quando o bot do Google busca a página, ele vê uma meta tag noindex e não inclui essa página no índice da web. A página ainda é rastreada e existe no URL fornecido, mas não aparecerá nos resultados da pesquisa, não importa quantas vezes ela seja vinculada a partir de qualquer outra página.
<meta name="robôs" content="index, seguir">
Adicionar essa metatag ao código-fonte HTML da sua página informa a um robô de mecanismo de busca para indexar esta página e todos os links que partem dela.
<meta name="robôs" content="index, nofollow">
Ao mudar 'follow' para 'nofollow', você influencia o comportamento de um bot de mecanismo de busca. A configuração de tag mencionada acima instrui um mecanismo de busca a indexar uma página, mas não a seguir nenhum link que seja colocado nela.
<meta name="robôs" content="noindex, seguir">
Esta metatag informa ao robô do mecanismo de busca para ignorar a página em que está localizado, mas seguir todos os links colocados nela.
<meta name="robôs" content="noindex, nofollow">
Esta tag colocada em uma página significa que nem a página nem os links que esta página contém serão seguidos ou indexados.
Além de uma meta tag robots noindex, você pode ocultar uma página configurando uma resposta de cabeçalho HTTP com uma X-Robots-Tag com um valor noindex ou none.
Além de páginas e elementos HTML, o X-Robots-Tag permite que você não indexe arquivos PDF separados, vídeos, imagens ou quaisquer outros arquivos não HTML onde não seja possível usar meta tags de robôs.
O mecanismo é bem parecido com o de uma tag noindex. Quando um bot de busca chega a uma página, a resposta HTTP retorna um cabeçalho X-Robots-Tag com instruções noindex. Uma página ou um arquivo ainda é rastreado, mas não aparecerá nos resultados da busca.
Este é o exemplo mais comum de resposta HTTP com a instrução para não indexar uma página.
HTTP/1.1 200 OK
(…)
X-Robots-Tag: noindex
(…)
Você pode especificar o tipo de bot de busca se precisar ocultar sua página de certos bots. O exemplo abaixo mostra como ocultar uma página de qualquer outro mecanismo de busca, exceto o Google, e restringir todos os bots de seguir os links naquela página:
X-Robots-Tag: googlebot: nofollow
X-Robots-Tag: outrobot: noindex, nofollow
Se você não especificar o tipo de robô, as instruções serão válidas para todos os tipos de rastreadores.
Para restringir a indexação de certos tipos de arquivos em todo o seu site, você pode adicionar as instruções de resposta X-Robots-Tag aos arquivos de configuração do software do servidor web do seu site.
É assim que você restringe todos os arquivos PDF em um servidor baseado em Apache:
<Arquivos ~ "\.pdf$">
Conjunto de cabeçalhos X-Robots-Tag "noindex, nofollow"
</Arquivos>
E estas são as mesmas instruções para o NGINX:
localização ~* \.pdf$ {
add_header X-Robots-Tag "noindex, nofollow";
}
Para restringir a indexação de um único elemento, o padrão é o seguinte para o Apache:
# o arquivo htaccess deve ser colocado no diretório do arquivo correspondente.
<Arquivos "unicorn.pdf">
Conjunto de cabeçalhos X-Robots-Tag "noindex, nofollow"
</Arquivos>
E é assim que você restringe a indexação de um elemento para NGINX:
localização = /secrets/unicorn.pdf {
add_header X-Robots-Tag "noindex, nofollow";
}
Embora uma tag robots noindex pareça uma solução mais fácil para restringir a indexação de suas páginas, há alguns casos em que usar uma X-Robots-Tag para páginas é uma opção melhor:
Ainda assim, lembre-se de que é somente o Google que segue as instruções do X-Robots-Tag com certeza. Quanto ao resto dos mecanismos de busca, não há garantia de que eles interpretarão a tag corretamente. Por exemplo, o Seznam não suporta x‑robots-tags de forma alguma. Então, se você está planejando que seu site apareça em vários mecanismos de busca, você precisará usar uma tag robots noindex nos snippets HTML.
Os erros mais comuns que os usuários cometem ao trabalhar com as tags noindex são os seguintes:
1) Adicionar uma página ou elemento noindexed ao arquivo robots.txt. O robots.txt restringe o rastreamento, portanto, os robôs de busca não virão para a página e verão as diretivas noindex. Isso significa que sua página pode ser indexada sem conteúdo e ainda aparecer nos resultados da pesquisa.
Para verificar se algum dos seus artigos com uma tag noindex foi parar no arquivo robots.txt, verifique a coluna de instruções do Robots na seção Estrutura do Site > Páginas do WebSite Auditor.
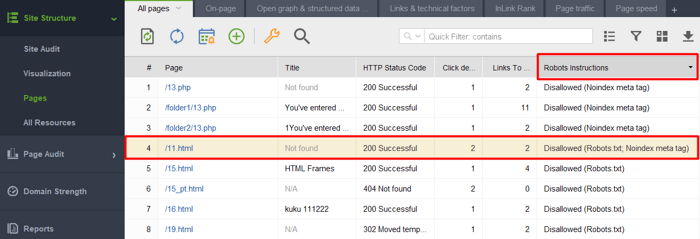
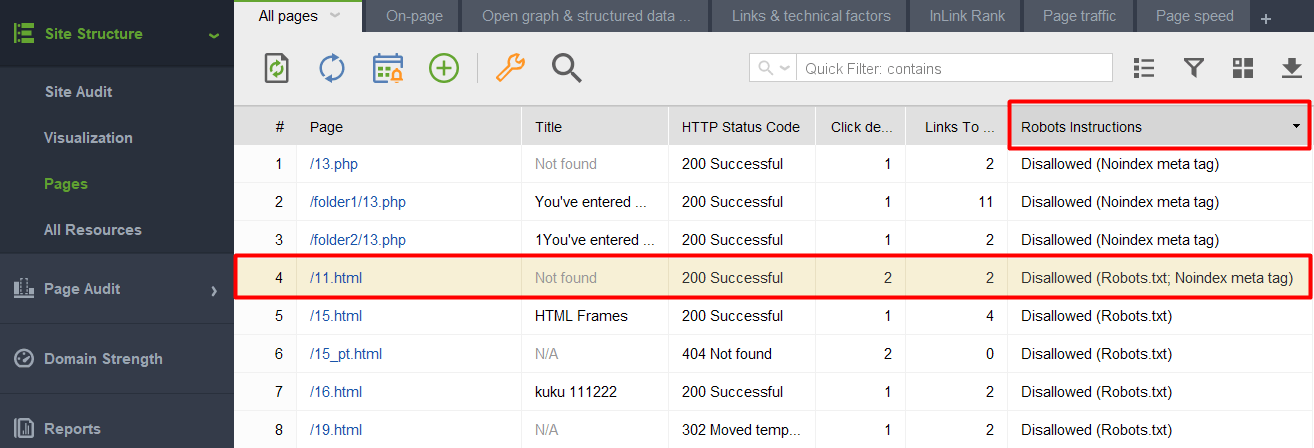
Observação: não se esqueça de habilitar as opções de especialista e desmarcar a opção Seguir instruções do robots.txt ao montar seu projeto para que a ferramenta veja as instruções, mas não as siga.
2) Usar letras maiúsculas em diretivas de tag. De acordo com o Google, todas as diretivas diferenciam maiúsculas de minúsculas, então tome cuidado.
Agora que tudo está mais ou menos claro com os principais problemas de indexação de conteúdo, vamos passar para vários casos não padronizados que merecem menção especial.
1) Certifique-se de que as páginas que você não quer que sejam indexadas não estejam incluídas no seu sitemap. Um sitemap é, na verdade, a maneira de dizer aos mecanismos de busca onde ir primeiro ao rastrear seu site. E não há razão para pedir aos robôs de busca para visitar as páginas que você não quer que eles vejam.
2) Ainda assim, se você precisar desindexar uma página que já esteja presente no sitemap, não remova uma página do sitemap até que ela seja rastreada novamente e desindexada pelos robôs de busca. Caso contrário, a desindexação pode levar mais tempo do que o esperado.
3) Proteja as páginas que contêm dados privados com senhas. A proteção por senha é a maneira mais confiável de ocultar conteúdo sensível, mesmo daqueles bots que não seguem as instruções do robots.txt. Os mecanismos de busca não sabem suas senhas, portanto, eles não chegarão à página, não verão o conteúdo sensível e não levarão a página para um SERP.
4) Para fazer com que os robôs de busca não indexem a página em si, mas sigam todos os links que uma página possui e indexem o conteúdo nesses URLs, configure a seguinte diretiva
<meta name="robôs" content="noindex, seguir">
Essa é uma prática comum em páginas de resultados de pesquisa interna, que contêm muitos links úteis, mas não têm nenhum valor em si.
5) Restrições de indexação podem ser especificadas para um robô específico. Por exemplo, você pode bloquear sua página de bots de notícias, bots de imagens, etc. Os nomes dos bots podem ser especificados para qualquer tipo de instrução, seja um arquivo robots.txt, meta tag robots ou X-Robots-Tag.
Por exemplo, você pode ocultar suas páginas especificamente do bot ChatGPT com robots.txt. Desde o anúncio dos plugins ChatGPT e GPT-4 (o que significa que o OpenAI agora pode obter informações da web), os proprietários de sites têm se preocupado com o uso de seu conteúdo. As questões de citação, plágio e direitos autorais se tornaram agudas para muitos sites.
Agora o mundo do SEO está dividido: alguns dizem que devemos bloquear o GPTBot de acessar nossos sites, outros dizem o oposto, e o terceiro diz que precisamos esperar até que algo fique mais claro. Em todo caso, você tem uma escolha.
E se você acredita firmemente que precisa bloquear o GPTBot, veja como fazer isso:
Se você quiser fechar todo o seu site.
Agente do usuário: GPTBot
Não permitir: /
Se você quiser fechar apenas uma parte específica do seu site.
Agente do usuário: GPTBot
Permitir: /diretório-1/
Não permitir: /diretório-2/
6) Não use uma tag noindex em testes A/B quando uma parte dos seus usuários for redirecionada da página A para a página B. Como se o noindex fosse combinado com o redirecionamento 301 (permanente), os mecanismos de busca receberiam os seguintes sinais:
Como resultado, ambas as páginas A e B desaparecem do índice.
Para configurar seu teste A/B corretamente, use um redirecionamento 302 (que é temporário) em vez de 301. Isso permitirá que os mecanismos de busca mantenham a página antiga no índice e a tragam de volta quando você terminar o teste. Se você estiver testando várias versões de uma página (A/B/C/D etc.), use a tag rel=canonical para marcar a versão canônica de uma página que deve entrar nos SERPs.
7) Use uma tag noindex para ocultar landing pages temporárias. Se você estiver ocultando páginas com ofertas especiais, páginas de anúncios, descontos ou qualquer tipo de conteúdo que não deve vazar, então desabilitar esse conteúdo com um arquivo robots.txt não é a melhor ideia. Como usuários supercuriosos ainda podem visualizar essas páginas no seu arquivo robots.txt. Usar noindex é melhor neste caso, para não comprometer acidentalmente a URL “secreta” em público.
Agora você sabe o básico sobre como encontrar e ocultar certas páginas do seu site da atenção dos robôs dos mecanismos de busca. E, como você vê, o processo é realmente fácil. Só não misture vários tipos de instruções em uma única página e tome cuidado para não ocultar as páginas que precisam aparecer na busca.
Eu esqueci de alguma coisa? Compartilhe suas perguntas nos comentários.
| Linking websites | N/A |
| Backlinks | N/A |
| InLink Rank | N/A |


