39351
•
10-minutę czytania
•


Indeksowanie stron witryny to początek procesu optymalizacji pod kątem wyszukiwarek. Umożliwienie robotom wyszukiwarek dostępu do treści oznacza, że Twoje strony są gotowe na przyjęcie odwiedzających, nie mają żadnych problemów technicznych i chcesz, aby wyświetlały się w SERP-ach, więc wszechstronna indeksacja wydaje się na pierwszy rzut oka ogromną korzyścią.
Jednak pewne typy stron lepiej trzymać z dala od SERP-ów, aby zabezpieczyć swoje rankingi. Oznacza to, że musisz je ukryć przed indeksowaniem. W tym poście poprowadzę Cię przez typy treści, które należy ukryć przed wyszukiwarkami i pokażę Ci, jak to zrobić.
Przejdźmy do konkretów bez zbędnych ceregieli. Oto lista stron, które lepiej ukryć przed wyszukiwarkami, aby nie pojawiały się w SERP-ach.
Ochrona treści przed bezpośrednim ruchem wyszukiwania jest koniecznością, gdy strona zawiera dane osobowe. Są to strony z poufnymi danymi firmy, informacjami o produktach alfa, informacjami o profilach użytkowników, prywatną korespondencją, danymi płatniczymi itp. Ponieważ prywatna treść powinna być ukryta przed kimkolwiek innym niż właściciel danych, Google (lub jakakolwiek wyszukiwarka) nie powinna udostępniać tych stron szerszej publiczności.
W przypadku, gdy formularz logowania nie jest umieszczony na stronie głównej, ale na osobnej stronie, nie ma rzeczywistej potrzeby pokazywania tej strony w SERP-ach. Takie strony nie niosą żadnej dodatkowej wartości dla użytkowników, co może być uznane za cienką treść.
Są to strony, które użytkownicy widzą po udanej akcji na stronie internetowej, czy to zakup, rejestracja, czy cokolwiek innego. Te strony prawdopodobnie mają również cienką treść i nie mają żadnej dodatkowej wartości dla osób wyszukujących.
Treść na stronach tego typu jest duplikatem treści stron głównych Twojej witryny. Oznacza to, że po przeszukaniu i zindeksowaniu strony te będą traktowane jako całkowite duplikaty treści.
To częsty problem dużych witryn e-commerce, które mają wiele produktów różniących się jedynie rozmiarem lub kolorem. Google może nie być w stanie odróżnić ich od siebie i traktować je jako duplikaty treści.
Kiedy użytkownicy trafiają na Twoją stronę z SERP-ów, spodziewają się, że klikną Twój link i znajdą odpowiedź na swoje pytanie. Nie kolejny wewnętrzny SERP z mnóstwem linków. Więc jeśli Twoje wewnętrzne SERP-y zostaną zindeksowane, prawdopodobnie nie przyniosą nic poza krótkim czasem spędzonym na stronie i wysokim współczynnikiem odrzuceń.
Jeśli wszystkie wpisy na Twoim blogu mają autora, to strona z biografią autora jest dokładną kopią strony głównej bloga.
Podobnie jak strony logowania, formularze subskrypcji zazwyczaj nie zawierają niczego poza formularzem wprowadzania danych w celu subskrypcji. Zatem strona a) jest pusta, b) nie dostarcza użytkownikom żadnej wartości. Dlatego musisz ograniczyć wyszukiwarkom możliwość przyciągania ich do SERP-ów.
Zasada jest taka, że strony będące w trakcie opracowywania muszą być chronione przed robotami wyszukiwarek do czasu, aż będą w pełni gotowe do przyjęcia odwiedzających.
Strony lustrzane to identyczne kopie Twoich stron na oddzielnym serwerze/w oddzielnym miejscu. Będą one uważane za techniczne duplikaty, jeśli zostaną przeszukane i zindeksowane.
Oferty specjalne i strony reklamowe mają być widoczne dla użytkowników dopiero po wykonaniu przez nich specjalnych działań lub w określonym czasie (oferty specjalne, wydarzenia itp.). Po zakończeniu wydarzenia strony te nie muszą być widoczne dla nikogo, w tym wyszukiwarek.
I teraz pojawia się pytanie: jak ukryć wszystkie wyżej wymienione strony przed uciążliwymi robotami sieciowymi, a jednocześnie zachować resztę witryny widoczną tak, jak być powinna?
Podczas konfigurowania instrukcji dla wyszukiwarek masz dwie opcje. Możesz ograniczyć indeksowanie lub ograniczyć indeksowanie strony.
Być może najprostszym i najbardziej bezpośrednim sposobem ograniczenia dostępu robotów wyszukiwarek do Twoich stron jest utworzenie pliku robots.txt. Pliki robots.txt pozwalają proaktywnie usuwać wszelkie niechciane treści z wyników wyszukiwania. Za pomocą tego pliku możesz ograniczyć dostęp do pojedynczej strony, całego katalogu, a nawet pojedynczego obrazu lub pliku.


Procedura jest dość prosta. Wystarczy utworzyć plik.txt, który ma następujące pola:
Należy pamiętać, że niektóre roboty indeksujące (na przykład Google) obsługują również dodatkowe pole o nazwie Allow: (Zezwalaj):. Jak sama nazwa wskazuje, pole Allow: (Zezwalaj): umożliwia wyraźne wskazanie plików/folderów, które mogą zostać przeszukane.
Poniżej wyjaśniono kilka podstawowych przykładów plików robots.txt.


* w wierszu User-agent oznacza, że wszystkie boty wyszukiwarek są instruowane, aby nie indeksować żadnej ze stron Twojej witryny, co jest oznaczone /. Najprawdopodobniej wolałbyś tego uniknąć, ale teraz rozumiesz, o co chodzi.


W powyższym przykładzie ograniczasz robotowi Google’a możliwość indeksowania Twoich zdjęć w wybranym katalogu.
Więcej instrukcji dotyczących ręcznego zapisywania takich plików znajdziesz w przewodniku Google Developers Guide.
Ale proces tworzenia pliku robots.txt może być w pełni zautomatyzowany – istnieje szeroka gama narzędzi, które są w stanie tworzyć takie pliki. Na przykład WebSite Auditor może łatwo skompilować plik robots.txt dla Twojej witryny.
Po uruchomieniu narzędzia i utworzeniu projektu witryny przejdź do sekcji Struktura witryny > Strony, kliknij ikonę klucza i wybierz plik Robots.txt.
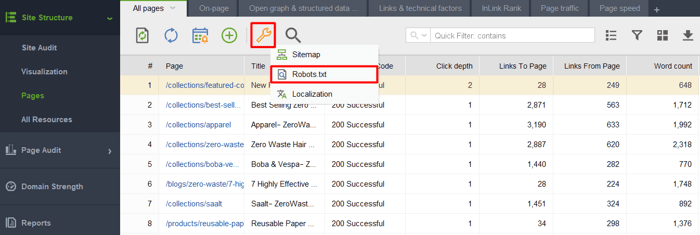
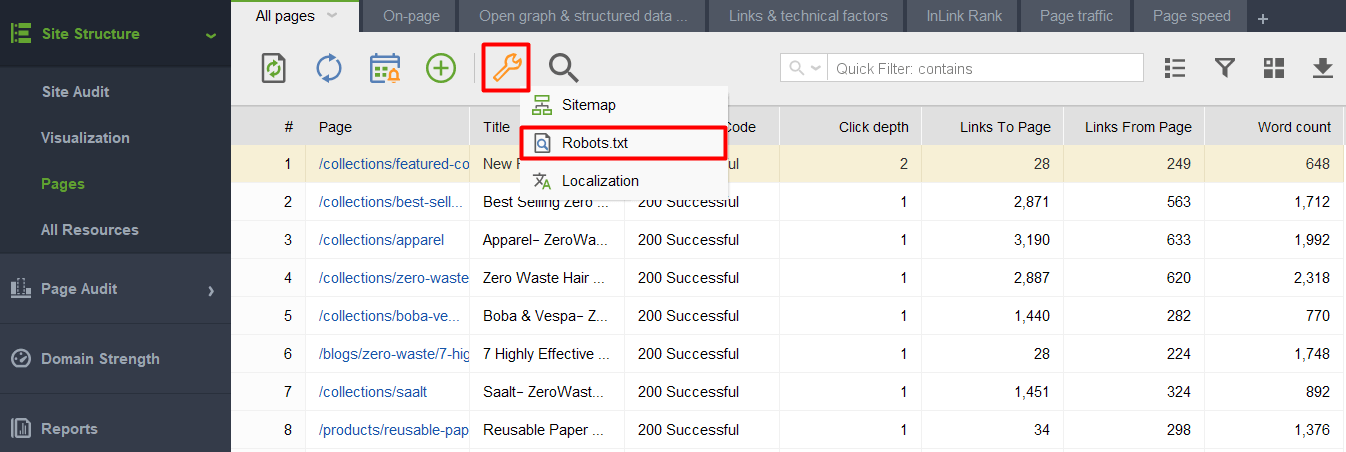
Następnie kliknij Dodaj regułę i określ instrukcje. Wybierz bota wyszukiwania i katalog lub stronę, dla których chcesz ograniczyć indeksowanie.

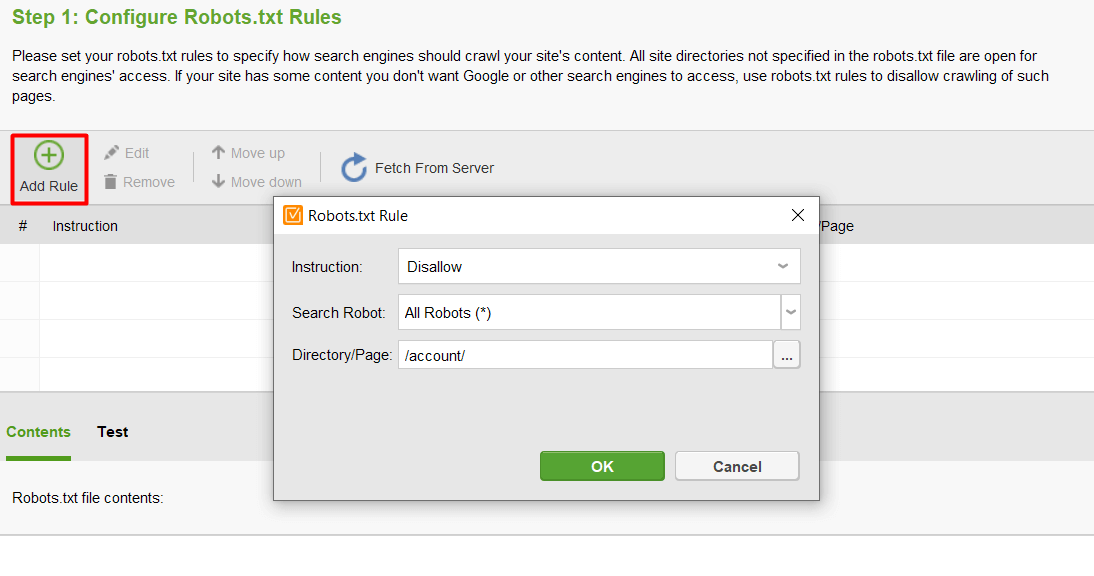
Po wprowadzeniu wszystkich ustawień kliknij Dalej, aby narzędzie wygenerowało plik robots.txt, który możesz przesłać do swojej witryny.
Aby zobaczyć zasoby zablokowane przed indeksowaniem i upewnić się, że nie zablokowano niczego, co powinno zostać przeszukane, przejdź do sekcji Struktura witryny > Audyt witryny i sprawdź sekcję Zasoby, których indeksowanie jest zabronione:
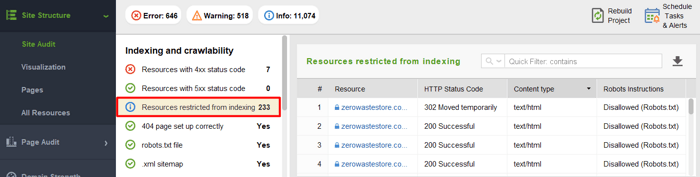

Pamiętaj również, że protokół robots.txt ma charakter czysto doradczy. Nie jest to blokada stron Twojej witryny, ale raczej „Prywatne — nie wpuszczaj”. Robots.txt może uniemożliwić „przestrzegającym prawa” botom (np. botom Google, Yahoo! i Bing) dostęp do Twojej zawartości. Jednak złośliwe boty po prostu go ignorują i mimo wszystko przeglądają Twoją zawartość. Istnieje więc ryzyko, że Twoje prywatne dane mogą zostać zeskrobane, skompilowane i ponownie wykorzystane pod pozorem dozwolonego użytku. Jeśli chcesz, aby Twoja zawartość była w 100% bezpieczna, powinieneś wprowadzić bezpieczniejsze środki (np. dodanie rejestracji na stronie, ukrycie zawartości pod hasłem itp.).
Oto najczęstsze błędy, które ludzie popełniają podczas tworzenia plików robots.txt. Przeczytaj tę część uważnie.
1) Używanie wielkich liter w nazwie pliku. Nazwa pliku to robots.txt. Kropka. Nie Robots.txt i nie ROBOTS.txt
2) Nie umieszczanie pliku robots.txt w katalogu głównym
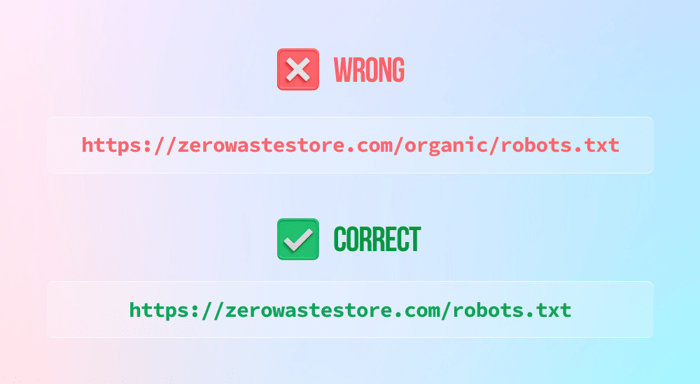

3) Zablokowanie całej witryny (chyba że chcesz) poprzez pozostawienie instrukcji disallow w następujący sposób


4) Nieprawidłowe określenie agenta użytkownika


5) Wymienianie kilku katalogów w jednym wierszu disallow. Każda strona lub katalog wymaga osobnego wiersza


6) Pozostawienie wiersza user-agent pustego
7) Wylistowanie wszystkich plików w katalogu. Jeśli ukrywasz cały katalog, nie musisz zawracać sobie głowy wylistowaniem każdego pojedynczego pliku.


8) W ogóle nie wspominając o linii instrukcji disallow


9) Brak podania mapy witryny na dole pliku robots.txt
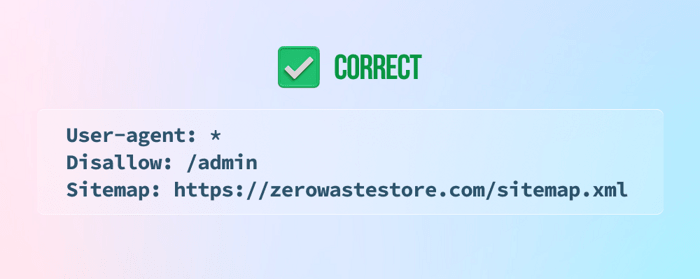

10) Dodanie instrukcji noindex do pliku
Użycie znacznika meta robots noindex lub znacznika X-Robots umożliwi robotom wyszukiwarek indeksowanie i dostęp do Twojej strony, ale uniemożliwi jej umieszczenie w indeksie, tj. wyświetlenie w wynikach wyszukiwania.
Przyjrzyjmy się teraz bliżej każdej opcji.
Meta tag robots noindex jest umieszczany w źródle HTML Twojej strony (sekcja <head>). Proces tworzenia tych tagów wymaga jedynie odrobiny wiedzy technicznej i może być łatwo wykonany nawet przez początkującego SEO.
Gdy bot Google pobiera stronę, widzi meta tag noindex i nie uwzględnia tej strony w indeksie internetowym. Strona jest nadal indeksowana i istnieje pod podanym adresem URL, ale nie pojawi się w wynikach wyszukiwania, niezależnie od tego, jak często jest linkowana z innej strony.
<meta name="robots" content="index, follow">
Dodanie tego meta tagu do kodu źródłowego HTML strony spowoduje, że robot wyszukiwarki zindeksuje tę stronę i wszystkie linki prowadzące do tej strony.
<meta name="robots" content="index, nofollow">
Zmieniając 'follow' na 'nofollow' wpływasz na zachowanie bota wyszukiwarki. Wspomniana powyżej konfiguracja tagu instruuje wyszukiwarkę, aby indeksowała stronę, ale nie śledziła żadnych linków, które są na niej umieszczone.
<meta name="robots" content="noindex, follow">
Ten meta tag informuje robota wyszukiwarki, aby zignorował stronę, na której się znajduje, ale podążał za wszystkimi linkami na niej umieszczonymi.
<meta name="robots" content="noindex, nofollow">
Umieszczenie tego znacznika na stronie oznacza, że ani ta strona, ani zawarte na niej linki nie będą śledzone ani indeksowane.
Oprócz znacznika meta „noindex” dla robotów możesz ukryć stronę, ustawiając odpowiedź nagłówka HTTP z znacznikiem X-Robots o wartości „noindex” lub „none”.
Oprócz stron i elementów HTML, X-Robots-Tag pozwala na noindexowanie oddzielnych plików PDF, filmów, obrazów i innych plików w formacie innym niż HTML, w przypadku których użycie tagów meta robots nie jest możliwe.
Mechanizm jest bardzo podobny do znacznika noindex. Gdy bot wyszukiwania wejdzie na stronę, odpowiedź HTTP zwraca nagłówek X-Robots-Tag z instrukcjami noindex. Strona lub plik nadal są indeksowane, ale nie pojawią się w wynikach wyszukiwania.
Oto najczęstszy przykład odpowiedzi HTTP zawierającej polecenie, aby nie indeksować strony.
HTTP/1.1 200 OK
(…)
X-Robots-Tag: noindex
(…)
Możesz określić typ bota wyszukiwania, jeśli chcesz ukryć swoją stronę przed niektórymi botami. Poniższy przykład pokazuje, jak ukryć stronę przed dowolną inną wyszukiwarką oprócz Google i ograniczyć wszystkim botom możliwość podążania za linkami na tej stronie:
X-Robots-Tag: googlebot: nofollow
X-Robots-Tag: innybot: noindex, nofollow
Jeśli nie określisz typu robota, instrukcje będą dotyczyć wszystkich typów robotów gąsienicowych.
Aby ograniczyć indeksowanie określonych typów plików w całej witrynie, możesz dodać instrukcje odpowiedzi X-Robots-Tag do plików konfiguracyjnych oprogramowania serwera WWW swojej witryny.
Oto jak ograniczyć wszystkie pliki PDF na serwerze opartym na Apache:
<Pliki ~ "\.pdf$">
Zestaw nagłówków X-Robots-Tag „noindex, nofollow”
</Pliki>
A oto te same instrukcje dla NGINX:
lokalizacja ~* \.pdf$ {
dodaj_nagłówek X-Robots-Tag "noindex, nofollow";
}
Aby ograniczyć indeksowanie pojedynczego elementu, dla serwera Apache stosuje się następujący wzorzec:
# plik htaccess musi być umieszczony w katalogu dopasowanego pliku.
<Pliki "unicorn.pdf">
Zestaw nagłówków X-Robots-Tag „noindex, nofollow”
</Pliki>
A tak ograniczasz indeksowanie jednego elementu dla NGINX:
lokalizacja = /secrets/unicorn.pdf {
dodaj_nagłówek X-Robots-Tag "noindex, nofollow";
}
Chociaż znacznik robots noindex wydaje się łatwiejszym rozwiązaniem ograniczającym indeksowanie stron, istnieją przypadki, w których lepszym rozwiązaniem jest użycie znacznika X-Robots:
Pamiętaj jednak, że tylko Google na pewno stosuje się do instrukcji X-Robots-Tag. Jeśli chodzi o pozostałe wyszukiwarki, nie ma gwarancji, że zinterpretują one tag poprawnie. Na przykład Seznam w ogóle nie obsługuje x-robots-tags. Więc jeśli planujesz, że Twoja witryna będzie wyświetlana w różnych wyszukiwarkach, musisz użyć tagu robots noindex w fragmentach kodu HTML.
Najczęstsze błędy popełniane przez użytkowników podczas pracy ze znacznikami noindex to:
1) Dodanie strony lub elementu noindexed do pliku robots.txt. Plik robots.txt ogranicza indeksowanie, więc roboty wyszukiwarek nie wejdą na stronę i nie zobaczą dyrektyw noindex. Oznacza to, że Twoja strona może zostać zaindeksowana bez treści i nadal pojawiać się w wynikach wyszukiwania.
Aby sprawdzić, czy któryś z Twoich dokumentów ze znacznikiem noindex został umieszczony w pliku robots.txt, sprawdź kolumnę Instrukcje robotów w sekcji Struktura witryny > Strony narzędzia WebSite Auditor.
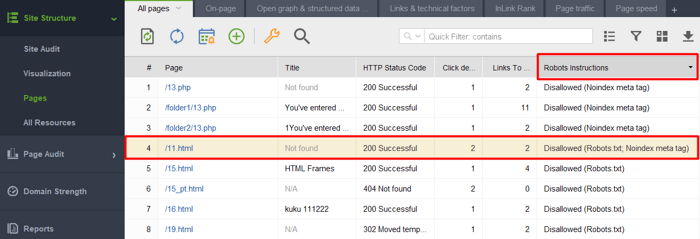
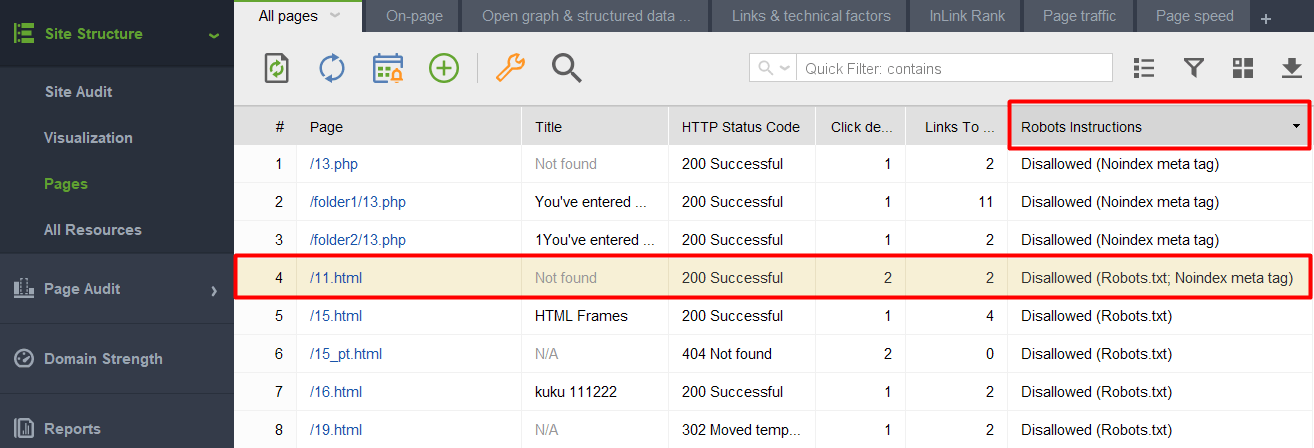
Uwaga: Nie zapomnij włączyć opcji eksperckich i odznaczyć opcji Postępuj zgodnie z instrukcją robots.txt podczas składania projektu. Dzięki temu narzędzie będzie widzieć instrukcje, ale ich nie będzie przestrzegać.
2) Używanie wielkich liter w dyrektywach tagów. Według Google wszystkie dyrektywy są wrażliwe na wielkość liter, więc bądź ostrożny.
Teraz, gdy wszystko jest już mniej więcej jasne w kwestii głównych problemów indeksowania treści, możemy omówić kilka niestandardowych przypadków, które zasługują na szczególną uwagę.
1) Upewnij się, że strony, których nie chcesz indeksować, nie są uwzględnione w mapie witryny. Mapa witryny to w rzeczywistości sposób informowania wyszukiwarek, gdzie mają się udać najpierw podczas indeksowania Twojej witryny. I nie ma powodu, aby prosić roboty wyszukiwarek o odwiedzanie stron, których nie chcesz im pokazywać.
2) Mimo to, jeśli musisz deindeksować stronę, która już znajduje się w mapie witryny, nie usuwaj strony z mapy witryny, dopóki nie zostanie ona ponownie przeszukana i deindeksowana przez roboty wyszukiwarek. W przeciwnym razie deindeksowanie może zająć więcej czasu, niż oczekiwano.
3) Chroń strony zawierające prywatne dane za pomocą haseł. Ochrona hasłem to najpewniejszy sposób na ukrycie poufnej treści nawet przed tymi botami, które nie stosują się do instrukcji robots.txt. Wyszukiwarki nie znają Twoich haseł, więc nie dotrą do strony, nie zobaczą poufnej treści i nie przeniosą strony do SERP.
4) Aby roboty wyszukiwarek nie indeksowały samej strony, lecz podążały za wszystkimi linkami na stronie i indeksowały zawartość tych adresów URL, skonfiguruj następującą dyrektywę
<meta name="robots" content="noindex, follow">
Jest to powszechna praktyka na stronach z wynikami wyszukiwania wewnętrznego, które zawierają wiele przydatnych linków, ale same w sobie nie niosą żadnej wartości.
5) Ograniczenia indeksowania mogą być określone dla konkretnego robota. Na przykład możesz zablokować swoją stronę przed botami informacyjnymi, botami obrazkowymi itp. Nazwy botów mogą być określone dla dowolnego typu instrukcji, czy to pliku robots.txt, meta tagu robots, czy X-Robots-Tag.
Na przykład możesz ukryć swoje strony specjalnie przed botem ChatGPT za pomocą pliku robots.txt. Od czasu ogłoszenia wtyczek ChatGPT i GPT-4 (co oznacza, że OpenAI może teraz pobierać informacje z sieci), właściciele witryn martwią się o wykorzystanie ich treści. Kwestie cytowania, plagiatu i praw autorskich stały się dotkliwe dla wielu witryn.
Teraz świat SEO jest podzielony: niektórzy mówią, że powinniśmy zablokować dostęp GPTBot do naszych stron, inni mówią odwrotnie, a trzecia mówi, że musimy poczekać, aż coś stanie się jaśniejsze. W każdym razie masz wybór.
A jeśli naprawdę uważasz, że musisz zablokować GPTBot, oto jak to zrobić:
Jeśli chcesz zamknąć całą swoją witrynę.
User-agent: GPTBot
Uniemożliwić: /
Jeśli chcesz zamknąć tylko określoną część swojej witryny.
User-agent: GPTBot
Zezwalaj: /katalog-1/
Nie zezwalaj: /katalog-2/
6) Nie używaj znacznika noindex w testach A/B, jeśli część użytkowników zostanie przekierowana ze strony A na stronę B. Tak jakby znacznik noindex był połączony z przekierowaniem 301 (stałym), wyszukiwarki otrzymają następujące sygnały:
W rezultacie obie strony, A i B, znikną z indeksu.
Aby poprawnie skonfigurować test A/B, użyj przekierowania 302 (które jest tymczasowe) zamiast 301. Pozwoli to wyszukiwarkom zachować starą stronę w indeksie i przywrócić ją po zakończeniu testu. Jeśli testujesz kilka wersji strony (A/B/C/D itd.), użyj znacznika rel=canonical, aby oznaczyć kanoniczną wersję strony, która powinna znaleźć się w SERP-ach.
7) Użyj tagu noindex, aby ukryć tymczasowe strony docelowe. Jeśli ukrywasz strony ze specjalnymi ofertami, stronami reklamowymi, rabatami lub jakimkolwiek rodzajem treści, które nie powinny wyciekać, to zablokowanie tej treści za pomocą pliku robots.txt nie jest najlepszym pomysłem. Ponieważ superciekawi użytkownicy nadal mogą przeglądać te strony w pliku robots.txt. W tym przypadku lepiej jest użyć tagu noindex, aby przypadkowo nie narazić „tajnego” adresu URL na ryzyko publiczne.
Teraz znasz podstawy, jak znaleźć i ukryć określone strony swojej witryny przed botami wyszukiwarek. I, jak widzisz, proces ten jest naprawdę prosty. Po prostu nie mieszaj kilku typów instrukcji na jednej stronie i uważaj, aby nie ukryć stron, które muszą pojawić się w wyszukiwarce.
Czy coś pominąłem? Podziel się swoimi pytaniami w komentarzach.








