39349
•
Lectura de 10 minutos
•


La indexación de las páginas del sitio es el punto de partida del proceso de optimización de motores de búsqueda. Permitir que los robots de los motores accedan a su contenido significa que sus páginas están listas para los visitantes, no tienen ningún problema técnico y desea que aparezcan en los SERP, por lo que la indexación integral parece un gran beneficio a primera vista.
Sin embargo, es mejor mantener ciertos tipos de páginas fuera de los SERP para asegurar su clasificación. Lo que significa que debe ocultarlas de la indexación. En esta publicación, lo guiaré a través de los tipos de contenido que debe ocultar de los motores de búsqueda y le mostraré cómo hacerlo.
Vayamos al grano sin más dilación. Aquí tienes la lista de páginas que es mejor ocultar a los buscadores para que no aparezcan en los SERP.
Proteger el contenido del tráfico de búsqueda directa es imprescindible cuando una página contiene información personal. Se trata de páginas con datos confidenciales de la empresa, información sobre productos alfa, información de perfiles de usuarios, correspondencia privada, datos de pago, etc. Como el contenido privado debe estar oculto a cualquier otra persona que no sea el propietario de los datos, Google (o cualquier motor de búsqueda) no debería hacer que estas páginas sean visibles para un público más amplio.
En caso de que un formulario de inicio de sesión no se coloque en una página de inicio sino en una página separada, no hay necesidad real de mostrar esta página en los SERP. Estas páginas no aportan ningún valor adicional para los usuarios, por lo que pueden considerarse contenido superficial.
Estas son las páginas que los usuarios ven después de una acción exitosa en un sitio web, ya sea una compra, un registro o cualquier otra cosa. Es probable que estas páginas también tengan poco contenido y aporten poco o ningún valor adicional para los usuarios que realizan búsquedas.
El contenido de este tipo de páginas duplica el de las páginas principales de su sitio web, lo que significa que estas páginas se tratarían como contenido duplicado total si se rastrearan e indexaran.
Este es un problema común en los grandes sitios web de comercio electrónico que tienen muchos productos que difieren solo en tamaño o color. Es posible que Google no logre distinguirlos y los trate como contenido duplicado.
Cuando los usuarios llegan a su sitio web desde los SERP, esperan hacer clic en su enlace y encontrar la respuesta a su consulta. No otro SERP interno con un montón de enlaces. Por lo tanto, si sus SERP internos logran indexarse, es probable que solo obtengan un bajo tiempo de permanencia en la página y una alta tasa de rebote.
Si su blog tiene todas las publicaciones escritas por un solo autor, entonces la página de biografía del autor es un duplicado puro de la página de inicio del blog.
Al igual que las páginas de inicio de sesión, los formularios de suscripción generalmente no incluyen nada más que el formulario para ingresar sus datos para suscribirse. Por lo tanto, la página a) está vacía y b) no ofrece ningún valor a los usuarios. Por eso, debe restringir que los motores de búsqueda los dirijan a los SERP.
Una regla general: las páginas que están en proceso de desarrollo deben mantenerse alejadas de los rastreadores de motores de búsqueda hasta que estén completamente listas para los visitantes.
Las páginas espejo son copias idénticas de sus páginas en un servidor o ubicación independiente. Se considerarán duplicados técnicos si se rastrean e indexan.
Las ofertas especiales y las páginas de anuncios solo están pensadas para que los usuarios las puedan ver después de que completen alguna acción especial o durante un período de tiempo determinado (ofertas especiales, eventos, etc.). Una vez finalizado el evento, nadie tiene por qué ver estas páginas, incluidos los motores de búsqueda.
Y ahora la pregunta es: ¿cómo ocultar todas las páginas mencionadas anteriormente de las molestas arañas y mantener el resto de su sitio web visible como debería ser?
Al configurar las instrucciones para los motores de búsqueda, tiene dos opciones: puede restringir el rastreo o puede restringir la indexación de una página.
Posiblemente, la forma más sencilla y directa de restringir el acceso de los rastreadores de los motores de búsqueda a sus páginas es mediante la creación de un archivo robots.txt. Los archivos robots.txt le permiten mantener de forma proactiva todo el contenido no deseado fuera de los resultados de búsqueda. Con este archivo, puede restringir el acceso a una sola página, a un directorio completo o incluso a una sola imagen o archivo.


El procedimiento es bastante sencillo. Solo hay que crear un archivo.txt que contenga los siguientes campos:
Tenga en cuenta que algunos rastreadores (por ejemplo, Google) también admiten un campo adicional llamado Allow:. Como su nombre lo indica, Allow: le permite enumerar explícitamente los archivos o carpetas que se pueden rastrear.
A continuación se explican algunos ejemplos básicos de archivos robots.txt.


* en la línea User-agent significa que todos los robots de los motores de búsqueda tienen instrucciones de no rastrear ninguna de las páginas de su sitio, lo que se indica con /. Lo más probable es que eso sea lo que preferiría evitar, pero ahora ya tiene la idea.


Con el ejemplo anterior, evita que el robot de imágenes de Google rastree sus imágenes en el directorio seleccionado.
Puede encontrar más instrucciones sobre cómo escribir dichos archivos manualmente en la guía para desarrolladores de Google.
Sin embargo, el proceso de creación de robots.txt se puede automatizar por completo: existe una amplia gama de herramientas capaces de crear dichos archivos. Por ejemplo, WebSite Auditor puede compilar fácilmente un archivo robots.txt para su sitio web.
Al iniciar la herramienta y crear un proyecto para su sitio web, vaya a Estructura del sitio > Páginas, haga clic en el ícono de llave inglesa y seleccione Robots.txt.
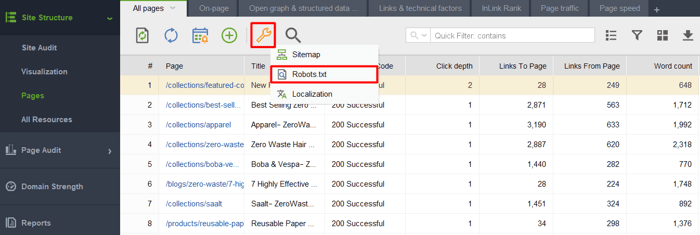
A continuación, haga clic en Agregar regla y especifique las instrucciones. Elija un robot de búsqueda y un directorio o página cuyo rastreo desee restringir.

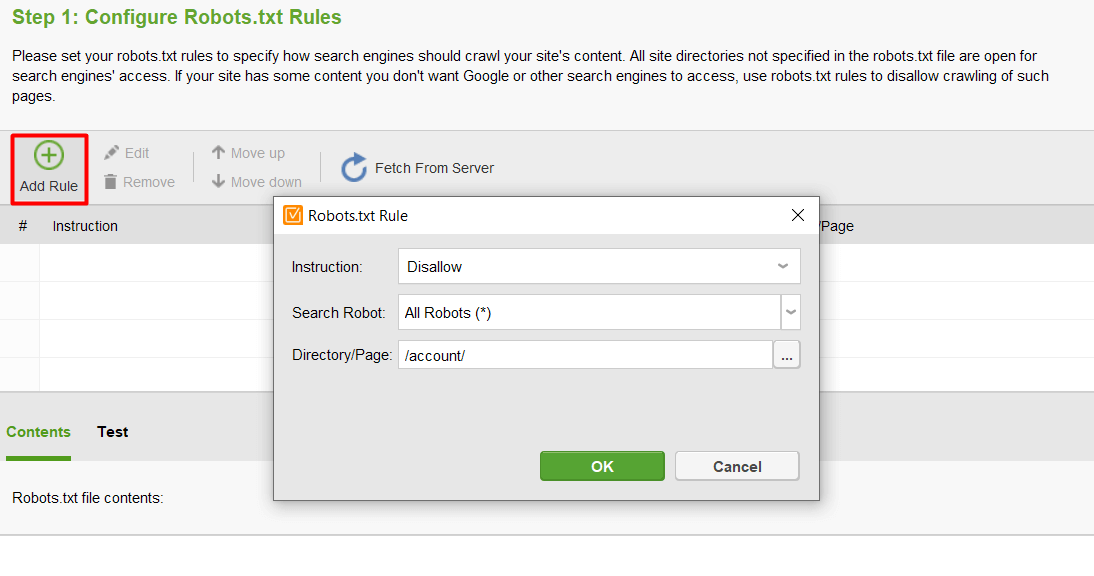
Una vez que haya terminado con todas las configuraciones, haga clic en Siguiente para permitir que la herramienta genere un archivo robots.txt que luego puede cargar en su sitio web.
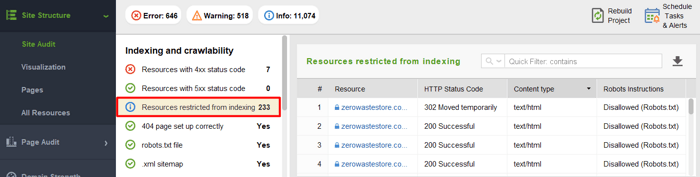
Para ver los recursos bloqueados para el rastreo y asegurarse de que no ha prohibido nada que deba rastrearse, vaya a Estructura del sitio > Auditoría del sitio y verifique la sección Recursos restringidos para la indexación:

Además, tenga en cuenta que el protocolo robots.txt es puramente informativo. No es un bloqueo de las páginas de su sitio, sino más bien una especie de "Privado: no entrar". Robots.txt puede impedir que los bots "respetuosos de la ley" (por ejemplo, los bots de Google, Yahoo! y Bing) accedan a su contenido. Sin embargo, los bots maliciosos simplemente lo ignoran y revisan su contenido de todos modos. Por lo tanto, existe el riesgo de que sus datos privados puedan ser extraídos, recopilados y reutilizados bajo la apariencia de uso legítimo. Si desea mantener su contenido 100% seguro, debe introducir medidas más seguras (por ejemplo, agregar un registro en un sitio, ocultar el contenido con una contraseña, etc.).
A continuación se enumeran los errores más comunes que se cometen al crear archivos robots.txt. Lea esta parte con atención.
1) Utilizar mayúsculas en el nombre del archivo. El nombre del archivo es robots.txt. Punto. Ni robots.txt ni ROBOTS.txt.
2) No colocar el archivo robots.txt en el directorio principal
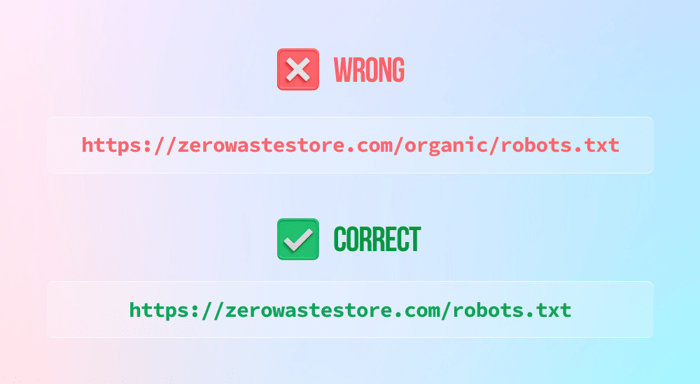

3) Bloquear todo su sitio web (a menos que lo desee) dejando la instrucción de no permitir de la siguiente manera


4) Especificar incorrectamente el agente de usuario


5) Mencionar varios catálogos en una línea de prohibición. Cada página o directorio necesita una línea separada.


6) Dejar la línea del agente de usuario vacía
7) Enumerar todos los archivos dentro de un directorio. Si se trata del directorio completo, no es necesario que se moleste en enumerar cada archivo.


8) No mencionar en absoluto la línea de instrucciones de no permitir


9) No indicar el mapa del sitio en la parte inferior del archivo robots.txt
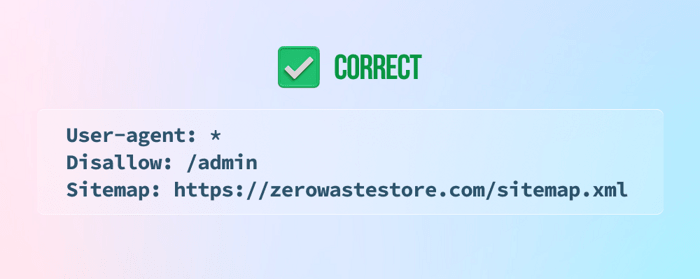

10) Agregar instrucciones noindex al archivo
El uso de una metaetiqueta robots noindex o la etiqueta X-Robots permitirá que los robots de los motores de búsqueda rastreen y accedan a su página, pero evitará que la página entre en el índice, es decir, que aparezca en los resultados de búsqueda.
Ahora veamos más de cerca cada opción.
La etiqueta meta robots noindex se coloca en el código fuente HTML de su página (sección <head>). El proceso de creación de estas etiquetas requiere solo un poco de conocimiento técnico y puede ser realizado fácilmente incluso por un experto en SEO.
Cuando el robot de Google obtiene la página, ve una etiqueta meta noindex y no incluye esta página en el índice web. La página se rastrea de todos modos y existe en la URL indicada, pero no aparecerá en los resultados de búsqueda sin importar la frecuencia con la que se vincule a ella desde cualquier otra página.
<meta name="robots" content="índice, seguir">
Agregar esta metaetiqueta al código fuente HTML de su página le indica a un robot de motor de búsqueda que indexe esta página y todos los enlaces que salen de ella.
<meta name="robots" contenido="índice, nofollow">
Al cambiar "follow" por "nofollow", se influye en el comportamiento del robot de un motor de búsqueda. La configuración de etiqueta mencionada anteriormente indica al motor de búsqueda que indexe una página, pero que no siga ningún enlace que se coloque en ella.
<meta name="robots" contenido="noindex, seguir">
Esta metaetiqueta le dice al robot de un motor de búsqueda que ignore la página en la que está colocada, pero que siga todos los enlaces colocados en ella.
<meta nombre="robots" contenido="noindex, nofollow">
Esta etiqueta colocada en una página significa que ni la página ni los enlaces que esta página contiene serán seguidos ni indexados.
Además de una metaetiqueta robots noindex, puedes ocultar una página configurando una respuesta de encabezado HTTP con una X-Robots-Tag con un valor noindex o none.
Además de páginas y elementos HTML, X-Robots-Tag le permite no indexar archivos PDF, videos, imágenes o cualquier otro archivo que no sea HTML donde no es posible usar metaetiquetas robots.
El mecanismo es muy parecido al de una etiqueta noindex. Una vez que un robot de búsqueda llega a una página, la respuesta HTTP devuelve un encabezado X-Robots-Tag con instrucciones noindex. Se rastrea una página o un archivo, pero no aparecerá en los resultados de búsqueda.
Este es el ejemplo más común de respuesta HTTP con la instrucción de no indexar una página.
HTTP/1.1 200 OK
(…)
Etiqueta de X-Robots: noindex
(…)
Puede especificar el tipo de robot de búsqueda si necesita ocultar su página a determinados robots. El siguiente ejemplo muestra cómo ocultar una página a cualquier otro motor de búsqueda que no sea Google y evitar que todos los robots sigan los enlaces de esa página:
Etiqueta de X-Robots: googlebot: nofollow
Etiqueta de X-Robots: otherbot: noindex, nofollow
Si no especifica el tipo de robot, las instrucciones serán válidas para todos los tipos de rastreadores.
Para restringir la indexación de ciertos tipos de archivos en todo su sitio web, puede agregar las instrucciones de respuesta de X-Robots-Tag a los archivos de configuración del software del servidor web de su sitio.
Así es como se restringen todos los archivos PDF en un servidor basado en Apache:
<Archivos ~ "\.pdf$">
Conjunto de encabezados X-Robots-Tag "noindex, nofollow"
</Archivos>
Y estas son las mismas instrucciones para NGINX:
ubicación ~* \.pdf$ {
agregar_encabezado Etiqueta X-Robots "noindex, nofollow";
}
Para restringir la indexación de un solo elemento, el patrón es el siguiente para Apache:
# el archivo htaccess debe colocarse en el directorio del archivo coincidente.
<Archivos "unicornio.pdf">
Conjunto de encabezados X-Robots-Tag "noindex, nofollow"
</Archivos>
Y así es como se restringe la indexación de un elemento para NGINX:
ubicación = /secretos/unicornio.pdf {
agregar_encabezado Etiqueta X-Robots "noindex, nofollow";
}
Aunque una etiqueta robots noindex parece una solución más sencilla para restringir la indexación de sus páginas, hay algunos casos en los que usar una etiqueta X-Robots-Tag para páginas es una mejor opción:
De todas formas, recuerda que solo Google sigue las instrucciones de X-Robots-Tag con seguridad. En cuanto al resto de motores de búsqueda, no hay garantía de que interpreten la etiqueta correctamente. Por ejemplo, Seznam no admite x-robots-tags en absoluto. Por lo tanto, si planeas que tu sitio web aparezca en varios motores de búsqueda, necesitarás usar una etiqueta robots noindex en los fragmentos HTML.
Los errores más comunes que cometen los usuarios al trabajar con las etiquetas noindex son los siguientes:
1) Agregar una página o un elemento no indexado al archivo robots.txt. Robots.txt restringe el rastreo, por lo que los robots de búsqueda no accederán a la página ni verán las directivas noindex. Esto significa que su página puede indexarse sin contenido y aun así aparecer en los resultados de búsqueda.
Para verificar si alguno de sus documentos con una etiqueta noindex entró en el archivo robots.txt, consulte la columna de instrucciones de Robots en la sección Estructura del sitio > Páginas de WebSite Auditor.
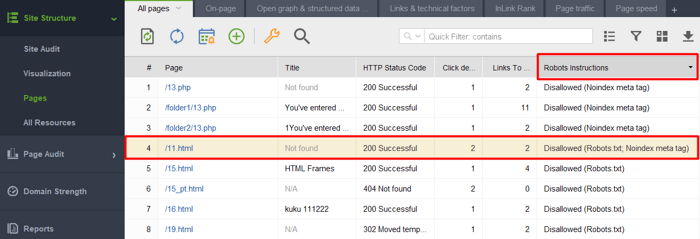
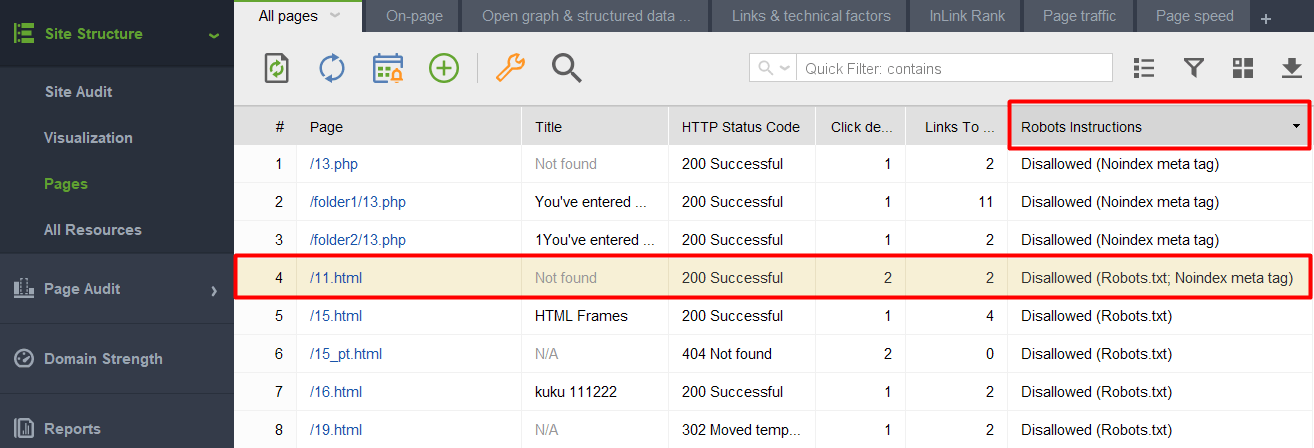
Nota: No olvide habilitar las opciones de experto y desmarcar la opción Seguir instrucciones de robots.txt al ensamblar su proyecto para que la herramienta vea las instrucciones pero no las siga.
2) Usar mayúsculas en las directivas de etiquetas. Según Google, todas las directivas distinguen entre mayúsculas y minúsculas, así que tenga cuidado.
Ahora que todo está más o menos claro con los principales problemas de indexación de contenidos, pasemos a varios casos no estándar que merecen una mención especial.
1) Asegúrate de que las páginas que no quieres que se indexen no estén incluidas en tu mapa del sitio. Un mapa del sitio es, en realidad, la forma de indicar a los motores de búsqueda a dónde ir primero cuando rastrean tu sitio web. Y no hay motivo para pedirles a los robots de búsqueda que visiten las páginas que no quieres que vean.
2) De todas formas, si necesitas desindexar una página que ya está presente en el mapa del sitio, no elimines la página del mapa del sitio hasta que los robots de búsqueda la vuelvan a rastrear y desindexar. De lo contrario, la desindexación puede tardar más tiempo del esperado.
3) Protege las páginas que contienen datos privados con contraseñas. La protección con contraseña es la forma más fiable de ocultar contenido confidencial incluso de aquellos robots que no siguen las instrucciones del archivo robots.txt. Los motores de búsqueda no conocen tus contraseñas, por lo que no podrán acceder a la página, ver el contenido confidencial y llevarla a un SERP.
4) Para que los robots de búsqueda no indexen la página en sí, sino que sigan todos los enlaces que tiene una página e indexen el contenido en esas URL, configure la siguiente directiva
<meta name="robots" contenido="noindex, seguir">
Esta es una práctica común para las páginas de resultados de búsqueda internas, que contienen muchos enlaces útiles pero que no tienen ningún valor en sí mismas.
5) Se pueden especificar restricciones de indexación para un robot específico. Por ejemplo, puede bloquear su página para que no accedan a robots de noticias, robots de imágenes, etc. Los nombres de los robots se pueden especificar para cualquier tipo de instrucciones, ya sea un archivo robots.txt, una etiqueta meta robots o una etiqueta X-Robots-Tag.
Por ejemplo, puedes ocultar tus páginas específicamente al bot ChatGPT con robots.txt. Desde el anuncio de los complementos ChatGPT y GPT-4 (que significa que OpenAI ahora puede obtener información de la web), los propietarios de sitios web han estado preocupados por el uso de su contenido. Los problemas de citas, plagio y derechos de autor se volvieron graves para muchos sitios.
Ahora el mundo del SEO está dividido: algunos dicen que deberíamos bloquear el acceso de GPTBot a nuestros sitios, otros dicen lo contrario y otros dicen que debemos esperar hasta que algo esté más claro. En cualquier caso, tienes una opción.
Y si crees firmemente que necesitas bloquear GPTBot, aquí te explicamos cómo puedes hacerlo:
Si desea cerrar todo su sitio.
Agente de usuario: GPTBot
No permitir: /
Si desea cerrar solo una parte particular de su sitio.
Agente de usuario: GPTBot
Permitir: /directorio-1/
No permitir: /directorio-2/
6) No utilice una etiqueta noindex en pruebas A/B cuando una parte de sus usuarios sea redirigida de la página A a la página B. Si noindex se combina con una redirección 301 (permanente), los motores de búsqueda recibirán las siguientes señales:
Como resultado, las páginas A y B desaparecen del índice.
Para configurar correctamente la prueba A/B, utilice una redirección 302 (que es temporal) en lugar de 301. Esto permitirá que los motores de búsqueda mantengan la página anterior en el índice y la recuperen cuando finalice la prueba. Si está probando varias versiones de una página (A/B/C/D, etc.), utilice la etiqueta rel=canonical para marcar la versión canónica de una página que debería aparecer en los SERP.
7) Utiliza una etiqueta noindex para ocultar páginas de destino temporales. Si estás ocultando páginas con ofertas especiales, páginas de anuncios, descuentos o cualquier tipo de contenido que no debería filtrarse, no permitir este contenido con un archivo robots.txt no es la mejor idea, ya que los usuarios súper curiosos pueden ver estas páginas en tu archivo robots.txt. En este caso, es mejor utilizar noindex para no comprometer accidentalmente la URL "secreta" en público.
Ahora ya conoces los conceptos básicos sobre cómo encontrar y ocultar determinadas páginas de tu sitio web de la atención de los robots de los motores de búsqueda. Y, como ves, el proceso es realmente sencillo. Simplemente no mezcles varios tipos de instrucciones en una sola página y ten cuidado de no ocultar las páginas que sí deben aparecer en la búsqueda.
¿Me he olvidado de algo? Comparte tus preguntas en los comentarios.








