44751
•
10-minütige Lektüre
•


Der Suchmaschinenoptimierungsprozess beginnt mit der Indexierung von Seiten. Wenn Sie Suchmaschinen-Bots Zugriff auf Ihre Inhalte gewähren, bedeutet dies, dass Ihre Seiten für Besucher bereit sind, keine technischen Probleme aufweisen und in den SERPs angezeigt werden sollen. Daher klingt eine umfassende Indexierung auf den ersten Blick nach einem großen Vorteil.
Bestimmte Seitentypen sollten jedoch besser von den SERPs ferngehalten werden, um Ihr Ranking zu sichern. Das bedeutet, dass Sie sie vor der Indizierung verbergen müssen. In diesem Beitrag führe ich Sie durch die Inhaltstypen, die Sie vor Suchmaschinen verbergen können, und zeige Ihnen, wie Sie das tun.
Kommen wir ohne weitere Umschweife zur Sache. Hier ist die Liste der Seiten, die Sie besser vor Suchmaschinen verbergen sollten, damit sie nicht in den SERPs erscheinen.
Der Schutz von Inhalten vor direktem Suchverkehr ist ein Muss, wenn eine Seite persönliche Informationen enthält. Dies sind die Seiten mit vertraulichen Unternehmensdetails, Informationen zu Alpha-Produkten, Informationen zu Benutzerprofilen, privater Korrespondenz, Zahlungsdaten usw. Da private Inhalte vor allen anderen als dem Dateneigentümer verborgen sein sollten, sollte Google (oder jede andere Suchmaschine) diese Seiten nicht für ein breiteres Publikum sichtbar machen.
Wenn ein Anmeldeformular nicht auf der Homepage, sondern auf einer separaten Seite platziert wird, besteht kein wirklicher Grund, diese Seite in den SERPs anzuzeigen. Solche Seiten bieten keinen zusätzlichen Wert für Benutzer und können als dünner Inhalt angesehen werden.
Dies sind die Seiten, die Benutzer nach einer erfolgreichen Aktion auf einer Website sehen, sei es ein Kauf, eine Registrierung oder etwas anderes. Diese Seiten haben wahrscheinlich auch nur wenig Inhalt und bieten wenig bis keinen Mehrwert für Suchende.
Der Inhalt dieser Seitenart ist ein Duplikat des Inhalts der Hauptseiten Ihrer Website. Dies bedeutet, dass diese Seiten beim Crawlen und Indexieren als Duplikate ihres gesamten Inhalts behandelt würden.
Dies ist ein häufiges Problem bei großen E-Commerce-Websites, die viele Produkte anbieten, die sich nur in Größe oder Farbe unterscheiden. Google kann den Unterschied zwischen diesen möglicherweise nicht erkennen und behandelt sie als Inhaltsduplikate.
Wenn Benutzer über SERPs auf Ihre Website gelangen, erwarten sie, dass sie auf Ihren Link klicken und die Antwort auf ihre Frage finden. Nicht auf eine weitere interne SERP mit einer Reihe von Links. Wenn Ihre internen SERPs also indexiert werden, führen sie wahrscheinlich nur zu einer geringen Verweildauer auf der Seite und einer hohen Absprungrate.
Wenn alle Beiträge Ihres Blogs von einem einzigen Autor stammen, handelt es sich bei der Biografieseite des Autors um ein reines Duplikat der Homepage des Blogs.
Ähnlich wie Anmeldeseiten enthalten Abonnementformulare normalerweise nichts weiter als das Formular zum Eingeben Ihrer Daten zum Abonnieren. Daher ist die Seite a) leer und b) bietet den Benutzern keinen Mehrwert. Aus diesem Grund müssen Sie Suchmaschinen daran hindern, sie in die SERPs zu ziehen.
Als Faustregel gilt: Seiten, die sich im Entwicklungsprozess befinden, müssen von den Crawlern der Suchmaschinen ferngehalten werden, bis sie vollständig für Besucher bereit sind.
Spiegelseiten sind identische Kopien Ihrer Seiten auf einem separaten Server/Standort. Sie werden als technische Duplikate betrachtet, wenn sie gecrawlt und indexiert werden.
Sonderangebote und Werbeseiten sind für Benutzer nur sichtbar, nachdem sie spezielle Aktionen ausgeführt haben oder während eines bestimmten Zeitraums (Sonderangebote, Veranstaltungen usw.). Nach Abschluss der Veranstaltung müssen diese Seiten für niemanden mehr sichtbar sein, auch nicht für Suchmaschinen.
Und nun stellt sich die Frage: Wie können Sie alle oben genannten Seiten vor lästigen Spidern verbergen und gleichzeitig dafür sorgen, dass der Rest Ihrer Website so sichtbar bleibt, wie es sein sollte?
Beim Einrichten der Anweisungen für Suchmaschinen haben Sie zwei Möglichkeiten. Sie können das Crawling oder die Indizierung einer Seite einschränken.
Der wohl einfachste und direkteste Weg, den Zugriff von Suchmaschinen-Crawlern auf Ihre Seiten zu beschränken, ist die Erstellung einer robots.txt-Datei. Mit robots.txt-Dateien können Sie alle unerwünschten Inhalte proaktiv aus den Suchergebnissen heraushalten. Mit dieser Datei können Sie den Zugriff auf eine einzelne Seite, ein ganzes Verzeichnis oder sogar ein einzelnes Bild oder eine einzelne Datei beschränken.


Das Verfahren ist ziemlich einfach. Sie erstellen einfach eine TXT-Datei mit den folgenden Feldern:
Beachten Sie, dass einige Crawler (z. B. Google) auch ein zusätzliches Feld namens Allow: unterstützen. Wie der Name schon sagt, können Sie mit Allow: die Dateien/Ordner explizit auflisten, die gecrawlt werden können.
Hier werden einige grundlegende Beispiele für robots.txt-Dateien erläutert.


* in der User-Agent -Zeile bedeutet, dass alle Suchmaschinen-Bots angewiesen werden, keine Ihrer Seiten zu crawlen. Dies wird durch / angezeigt. Wahrscheinlich möchten Sie das lieber vermeiden, aber jetzt verstehen Sie, was ich meine.


Mit dem obigen Beispiel verhindern Sie, dass der Image Bot von Google Ihre Bilder im ausgewählten Verzeichnis crawlen kann.
Weitere Anweisungen zum manuellen Schreiben solcher Dateien finden Sie im Google Developer's Guide.
Der Prozess der Erstellung von robots.txt kann jedoch vollständig automatisiert werden – es gibt eine Vielzahl von Tools, die solche Dateien erstellen können. Beispielsweise kann WebSite Auditor problemlos eine robots.txt-Datei für Ihre Website erstellen.
Wenn Sie das Tool starten und ein Projekt für Ihre Website erstellen, gehen Sie zu Site-Struktur > Seiten, klicken Sie auf das Schraubenschlüsselsymbol und wählen Sie Robots.txt aus.
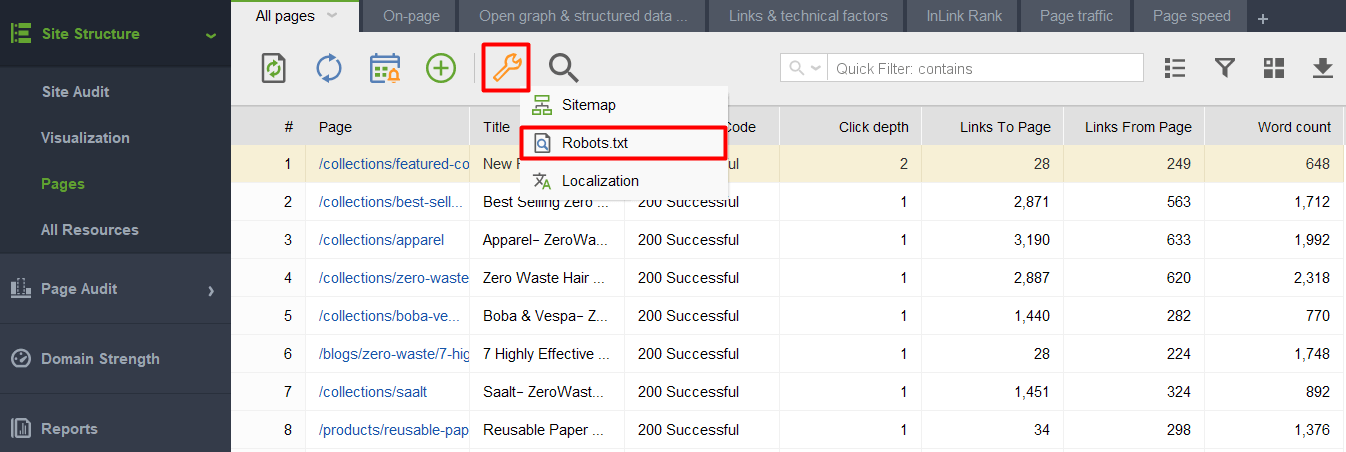
Klicken Sie dann auf Regel hinzufügen und geben Sie die Anweisungen an. Wählen Sie einen Suchbot und ein Verzeichnis oder eine Seite aus, für die Sie das Crawling einschränken möchten.

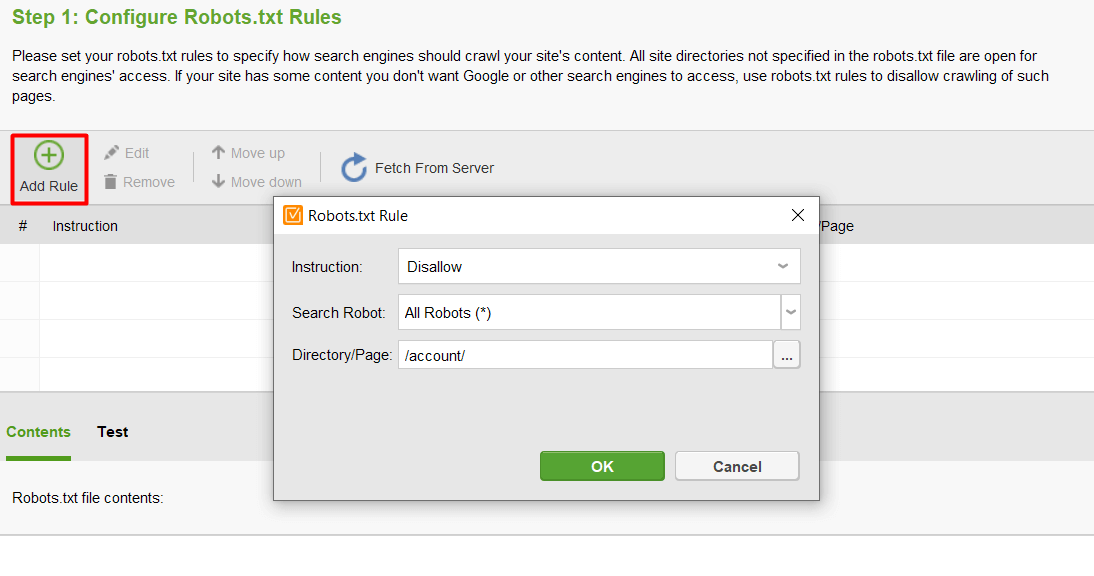
Wenn Sie mit allen Einstellungen fertig sind, klicken Sie auf „Weiter“, damit das Tool eine robots.txt-Datei generiert, die Sie dann auf Ihre Website hochladen können.
Um die vom Crawlen blockierten Ressourcen anzuzeigen und sicherzustellen, dass Sie nichts verboten haben, was gecrawlt werden sollte, gehen Sie zu Site-Struktur > Site-Audit und prüfen Sie den Abschnitt Von der Indizierung ausgeschlossene Ressourcen:
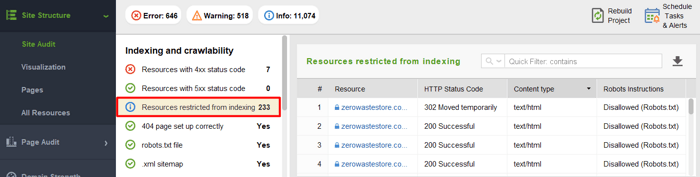

Beachten Sie auch, dass das robots.txt-Protokoll rein beratend ist. Es ist keine Sperre für Ihre Site-Seiten, sondern eher eine „Privat – draußen bleiben“-Anweisung. Robots.txt kann „gesetzestreue“ Bots (z. B. Google-, Yahoo!- und Bing-Bots) daran hindern, auf Ihre Inhalte zuzugreifen. Bösartige Bots ignorieren es jedoch einfach und durchsuchen Ihre Inhalte trotzdem. Es besteht also das Risiko, dass Ihre privaten Daten unter dem Deckmantel der fairen Nutzung abgeschöpft, kompiliert und wiederverwendet werden. Wenn Sie Ihre Inhalte 100 % sicher halten möchten, sollten Sie sicherere Maßnahmen ergreifen (z. B. Registrierung auf einer Site hinzufügen, Inhalte hinter einem Passwort verbergen usw.).
Hier sind die häufigsten Fehler, die beim Erstellen von robots.txt-Dateien gemacht werden. Lesen Sie diesen Teil sorgfältig durch.
1) Verwenden Sie Großbuchstaben im Dateinamen. Der Name der Datei lautet robots.txt. Punkt. Nicht Robots.txt und nicht ROBOTS.txt
2) Die Datei robots.txt wird nicht im Hauptverzeichnis abgelegt
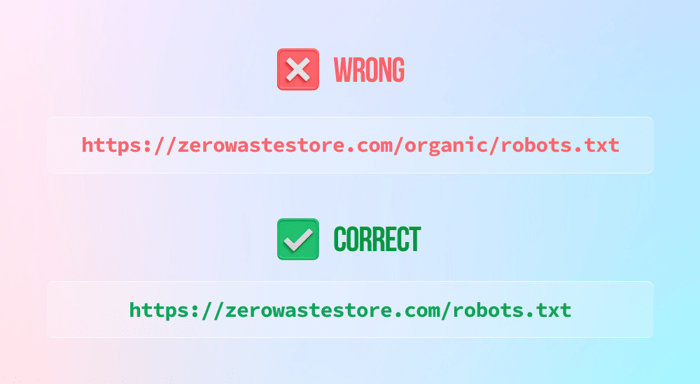

3) Blockieren Sie Ihre gesamte Website (sofern Sie dies nicht möchten), indem Sie die Disallow-Anweisung folgendermaßen belassen


4) Falsche Angabe des User-Agents


5) Erwähnung mehrerer Kataloge pro Disallow-Zeile. Jede Seite oder jedes Verzeichnis benötigt eine eigene Zeile


6) Die User-Agent-Zeile leer lassen
7) Auflisten aller Dateien in einem Verzeichnis. Wenn Sie das gesamte Verzeichnis ausblenden, müssen Sie sich nicht die Mühe machen, jede einzelne Datei aufzulisten.


8) Die Zeile mit den Disallow-Anweisungen wird überhaupt nicht erwähnt


9) Keine Angabe der Sitemap am Ende der robots.txt-Datei
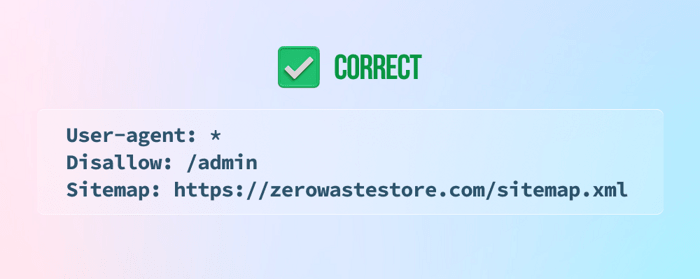

10) Hinzufügen von Noindex-Anweisungen zur Datei
Die Verwendung eines Robots-Noindex-Metatags oder des X-Robots-Tags ermöglicht es den Bots der Suchmaschinen, Ihre Seite zu crawlen und darauf zuzugreifen, verhindert jedoch, dass die Seite in den Index aufgenommen wird, d. h. in den Suchergebnissen erscheint.
Sehen wir uns nun jede Option genauer an.
Ein Robots-Noindex-Metatag wird in den HTML-Quellcode Ihrer Seite eingefügt (<head>-Abschnitt). Das Erstellen dieser Tags erfordert nur wenig technisches Know-how und kann selbst von einem unerfahrenen SEO problemlos durchgeführt werden.
Wenn der Google-Bot die Seite abruft, sieht er ein Noindex-Meta-Tag und nimmt diese Seite nicht in den Webindex auf. Die Seite wird zwar noch gecrawlt und existiert unter der angegebenen URL, wird aber nicht in den Suchergebnissen angezeigt, egal wie oft von einer anderen Seite aus auf sie verlinkt wird.
<meta name="robots" content="index, folgen">
Durch das Hinzufügen dieses Meta-Tags zum HTML-Quellcode Ihrer Seite weisen Sie den Bot einer Suchmaschine an, diese Seite und alle von dieser Seite ausgehenden Links zu indizieren.
<meta name="robots" content="index, nofollow">
Indem Sie „follow“ in „nofollow“ ändern, beeinflussen Sie das Verhalten eines Suchmaschinen-Bots. Die oben erwähnte Tag-Konfiguration weist eine Suchmaschine an, eine Seite zu indizieren, aber keinen darauf platzierten Links zu folgen.
<meta name="robots" content="noindex, folgen">
Dieses Meta-Tag weist den Bot einer Suchmaschine an, die Seite, auf der es platziert ist, zu ignorieren, aber allen darauf platzierten Links zu folgen.
<meta name="robots" content="noindex, nofollow">
Dieses auf einer Seite platzierte Tag bedeutet, dass weder die Seite noch die auf dieser Seite enthaltenen Links verfolgt oder indexiert werden.
Neben einem Robots-Noindex-Metatag können Sie eine Seite ausblenden, indem Sie eine HTTP-Header-Antwort mit einem X-Robots-Tag mit einem Noindex- oder None- Wert einrichten.
Zusätzlich zu Seiten und HTML-Elementen können Sie mit X-Robots-Tag einzelne PDF-Dateien, Videos, Bilder oder andere Nicht-HTML-Dateien, bei denen die Verwendung von Robots-Meta-Tags nicht möglich ist, nicht indizieren.
Der Mechanismus ähnelt weitgehend dem eines Noindex-Tags. Sobald ein Suchbot auf eine Seite gelangt, gibt die HTTP-Antwort einen X-Robots-Tag-Header mit Noindex-Anweisungen zurück. Eine Seite oder Datei wird zwar noch gecrawlt, erscheint aber nicht in den Suchergebnissen.
Dies ist das häufigste Beispiel für eine HTTP-Antwort mit der Anweisung, eine Seite nicht zu indizieren.
HTTP/1.1 200 OK
(…)
X-Robots-Tag: noindex
(…)
Sie können den Typ des Suchbots angeben, wenn Sie Ihre Seite vor bestimmten Bots verbergen möchten. Das folgende Beispiel zeigt, wie Sie eine Seite vor allen anderen Suchmaschinen außer Google verbergen und alle Bots daran hindern, den Links auf dieser Seite zu folgen:
X-Robots-Tag: googlebot: nofollow
X-Robots-Tag: otherbot: noindex, nofollow
Wenn Sie den Robotertyp nicht angeben, gelten die Anweisungen für alle Crawlertypen.
Um die Indizierung bestimmter Dateitypen auf Ihrer gesamten Website einzuschränken, können Sie die X-Robots-Tag-Antwortanweisungen zu den Konfigurationsdateien der Webserversoftware Ihrer Site hinzufügen.
So schränken Sie alle PDF-Dateien auf einem Apache-basierten Server ein:
<Dateien ~ "\.pdf$">
Header-Set X-Robots-Tag "noindex, nofollow"
</Dateien>
Und dies sind die gleichen Anweisungen für NGINX:
Standort ~* \.pdf$ {
add_header X-Robots-Tag "noindex, nofollow";
}
Um die Indizierung auf ein einzelnes Element zu beschränken, lautet das Muster für Apache wie folgt:
# die htaccess-Datei muss im Verzeichnis der übereinstimmenden Datei abgelegt werden.
<Dateien "Einhorn.pdf">
Header-Set X-Robots-Tag "noindex, nofollow"
</Dateien>
Und so schränken Sie die Indizierung eines Elements für NGINX ein:
Standort = /secrets/unicorn.pdf {
add_header X-Robots-Tag "noindex, nofollow";
}
Obwohl ein Robots-Noindex-Tag eine einfachere Lösung zu sein scheint, um die Indizierung Ihrer Seiten einzuschränken, gibt es einige Fälle, in denen die Verwendung eines X-Robots-Tags für Seiten eine bessere Option ist:
Denken Sie jedoch daran, dass nur Google die Anweisungen für X-Robots-Tags befolgt. Für die übrigen Suchmaschinen gibt es keine Garantie, dass sie das Tag richtig interpretieren. Seznam unterstützt beispielsweise X-Robots-Tags überhaupt nicht. Wenn Sie also planen, dass Ihre Website in verschiedenen Suchmaschinen angezeigt wird, müssen Sie in den HTML-Snippets ein Robots-Noindex-Tag verwenden.
Die häufigsten Fehler, die Benutzer beim Arbeiten mit Noindex-Tags machen, sind die folgenden:
1) Hinzufügen einer nicht indexierten Seite oder eines nicht indexierten Elements zur robots.txt-Datei. Robots.txt schränkt das Crawling ein, sodass Suchroboter die Seite nicht aufrufen und die Noindex-Anweisungen nicht sehen. Das bedeutet, dass Ihre Seite möglicherweise ohne Inhalt indexiert wird und trotzdem in den Suchergebnissen erscheint.
Um zu überprüfen, ob einige Ihrer Seiten mit einem Noindex-Tag in die Datei robots.txt gelangt sind, prüfen Sie die Spalte „Robots-Anweisungen“ im Abschnitt „Site-Struktur > Seiten“ des WebSite Auditors.
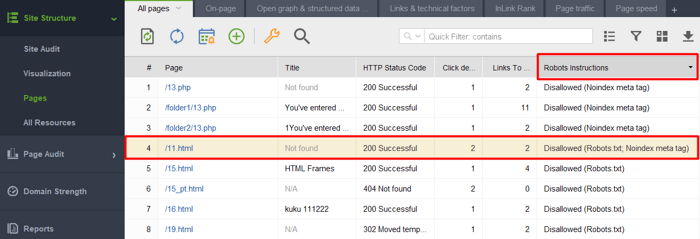
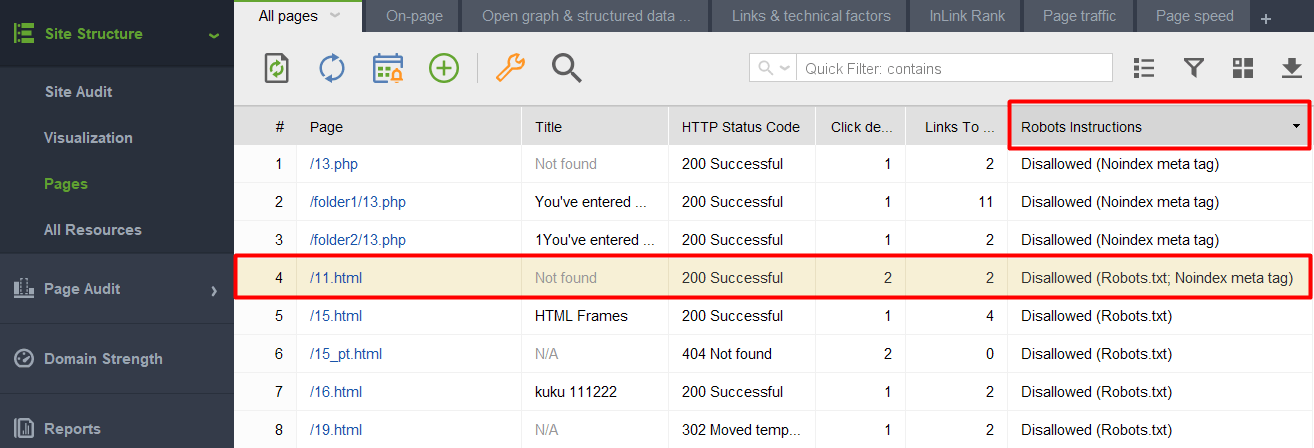
Hinweis: Vergessen Sie nicht, beim Zusammenstellen Ihres Projekts die Expertenoptionen zu aktivieren und die Option „Robots.txt-Anweisungen befolgen“ zu deaktivieren, damit das Tool die Anweisungen zwar sieht, ihnen aber nicht folgt.
2) Verwenden Sie Großbuchstaben in Tag-Direktiven. Laut Google sind alle Direktiven case-sensitiv, seien Sie also vorsichtig.
Nachdem nun die wichtigsten Probleme bei der Inhaltsindizierung mehr oder weniger geklärt sind, wenden wir uns nun mehreren nicht standardmäßigen Fällen zu, die eine besondere Erwähnung verdienen.
1) Stellen Sie sicher, dass die Seiten, die Sie nicht indexieren möchten, nicht in Ihrer Sitemap enthalten sind. Mithilfe einer Sitemap können Sie Suchmaschinen mitteilen, wo sie beim Crawlen Ihrer Website zuerst hingehen sollen. Und es gibt keinen Grund, Suchmaschinen-Bots zu bitten, die Seiten zu besuchen, die sie nicht sehen sollen.
2) Wenn Sie dennoch eine Seite deindexieren müssen, die bereits in der Sitemap vorhanden ist, entfernen Sie die Seite nicht aus der Sitemap, bis sie erneut von Suchrobotern gecrawlt und deindexiert wurde. Andernfalls kann die Deindexierung länger dauern als erwartet.
3) Schützen Sie Seiten, die private Daten enthalten, mit Passwörtern. Passwortschutz ist die zuverlässigste Methode, um vertrauliche Inhalte sogar vor Bots zu verbergen, die die Anweisungen von robots.txt nicht befolgen. Suchmaschinen kennen Ihre Passwörter nicht und gelangen daher nicht auf die Seite, sehen die vertraulichen Inhalte nicht und bringen die Seite nicht in eine SERP.
4) Um zu erreichen, dass Suchbots die Seite selbst nicht indizieren, aber allen Links einer Seite folgen und den Inhalt unter diesen URLs indizieren, richten Sie die folgende Anweisung ein
<meta name="robots" content="noindex, folgen">
Dies ist eine gängige Vorgehensweise bei internen Suchergebnisseiten, die zwar viele nützliche Links enthalten, aber selbst keinen Wert haben.
5) Indexierungsbeschränkungen können für einen bestimmten Roboter festgelegt werden. Sie können Ihre Seite beispielsweise vor News-Bots, Bild-Bots usw. sperren. Die Namen der Bots können für jede Art von Anweisungen angegeben werden, sei es eine robots.txt-Datei, ein Robots-Meta-Tag oder ein X-Robots-Tag.
Sie können Ihre Seiten beispielsweise mit robots.txt gezielt vor dem ChatGPT-Bot verbergen. Seit der Ankündigung von ChatGPT-Plugins und GPT-4 (was bedeutet, dass OpenAI jetzt Informationen aus dem Internet abrufen kann) sind Websitebesitzer besorgt über die Verwendung ihrer Inhalte. Die Probleme von Zitaten, Plagiaten und Urheberrechten sind für viele Websites akut geworden.
Die SEO-Welt ist gespalten: Einige sagen, wir sollten GPTBot den Zugriff auf unsere Websites verweigern, andere sagen das Gegenteil und wieder andere sagen, wir müssen warten, bis etwas klarer wird. In jedem Fall haben Sie die Wahl.
Und wenn Sie der festen Überzeugung sind, dass Sie GPTBot blockieren müssen, können Sie das folgendermaßen tun:
Wenn Sie Ihre gesamte Site schließen möchten.
Benutzeragent: GPTBot
Nicht zulassen: /
Wenn Sie nur einen bestimmten Teil Ihrer Site schließen möchten.
Benutzeragent: GPTBot
Erlauben: /Verzeichnis-1/
Nicht zulassen: /Verzeichnis-2/
6) Verwenden Sie in A/B-Tests kein Noindex-Tag, wenn ein Teil Ihrer Benutzer von Seite A auf Seite B umgeleitet wird. Wenn Noindex mit einer 301-Umleitung (permanent) kombiniert wird, erhalten Suchmaschinen die folgenden Signale:
In der Folge verschwinden sowohl Seite A als auch Seite B aus dem Index.
Um Ihren A/B-Test richtig einzurichten, verwenden Sie eine 302-Weiterleitung (die temporär ist) anstelle von 301. Dadurch können Suchmaschinen die alte Seite im Index behalten und sie wiederherstellen, wenn Sie den Test abgeschlossen haben. Wenn Sie mehrere Versionen einer Seite testen (A/B/C/D usw.), verwenden Sie das Tag rel=canonical, um die kanonische Version einer Seite zu markieren, die in die SERPs aufgenommen werden soll.
7) Verwenden Sie ein Noindex-Tag, um temporäre Zielseiten zu verbergen. Wenn Sie Seiten mit Sonderangeboten, Werbeseiten, Rabatten oder Inhalten jeglicher Art verbergen, die nicht durchsickern sollten, ist es nicht die beste Idee, diese Inhalte mit einer robots.txt-Datei zu verbieten. Denn superneugierige Benutzer können diese Seiten in Ihrer robots.txt-Datei immer noch sehen. In diesem Fall ist die Verwendung von Noindex besser, um die „geheime“ URL nicht versehentlich öffentlich preiszugeben.
Jetzt kennen Sie die Grundlagen, wie Sie bestimmte Seiten Ihrer Website finden und vor den Bots der Suchmaschinen verbergen können. Und wie Sie sehen, ist der Vorgang eigentlich ganz einfach. Mischen Sie einfach nicht mehrere Arten von Anweisungen auf einer Seite und seien Sie vorsichtig, damit Sie die Seiten, die in der Suche erscheinen müssen, nicht verbergen.
Habe ich etwas vergessen? Teilen Sie Ihre Fragen in den Kommentaren.


