39372
•
10 minuten gelezen
•


Indexering van sitepagina's is waar het zoekmachineoptimalisatieproces mee begint. Door enginebots toegang te geven tot uw content, betekent dit dat uw pagina's klaar zijn voor bezoekers, dat ze geen technische problemen hebben en dat u wilt dat ze in SERP's verschijnen, dus allesomvattende indexering klinkt op het eerste gezicht als een enorm voordeel.
Bepaalde typen pagina's kunnen echter beter uit SERP's worden gehouden om uw rankings veilig te stellen. Dat betekent dat u ze moet verbergen voor indexering. In dit bericht zal ik u door de typen content leiden die u moet verbergen voor zoekmachines en u laten zien hoe u dat doet.
Laten we meteen ter zake komen. Hier is de lijst met pagina's die u beter kunt verbergen voor zoekmachines, zodat ze niet in SERP's verschijnen.
Het beschermen van content tegen direct zoekverkeer is een must wanneer een pagina persoonlijke informatie bevat. Dit zijn de pagina's met vertrouwelijke bedrijfsgegevens, informatie over alfaproducten, informatie over gebruikersprofielen, privécorrespondentie, betalingsgegevens, etc. Aangezien privécontent verborgen moet blijven voor iedereen behalve de eigenaar van de gegevens, mag Google (of een andere zoekmachine) deze pagina's niet zichtbaar maken voor een breder publiek.
Als een inlogformulier niet op een homepage maar op een aparte pagina wordt geplaatst, is er geen echte noodzaak om deze pagina in SERP's te tonen. Zulke pagina's hebben geen extra waarde voor gebruikers, wat als dunne content kan worden beschouwd.
Dit zijn de pagina's die gebruikers zien na een succesvolle actie op een website, of dat nu een aankoop, registratie of iets anders is. Deze pagina's hebben waarschijnlijk ook dunne content en hebben weinig tot geen toegevoegde waarde voor zoekers.
De inhoud van dit type pagina's is een duplicaat van de inhoud van de hoofdpagina's van uw website. Dit betekent dat deze pagina's als volledige duplicaten worden beschouwd als ze worden gecrawld en geïndexeerd.
Dit is een veelvoorkomend probleem voor grote e-commercewebsites met veel producten die alleen in grootte of kleur verschillen. Google kan het verschil tussen deze producten niet zien en ze als duplicaten van de inhoud behandelen.
Wanneer gebruikers via SERP's naar uw website komen, verwachten ze op uw link te klikken en het antwoord op hun vraag te vinden. Niet zomaar een interne SERP met een hoop links. Dus als uw interne SERP's geïndexeerd worden, leveren ze waarschijnlijk alleen maar een lage tijd op de pagina en een hoge bounce rate op.
Als alle berichten op je blog door één auteur zijn geschreven, dan is de biopagina van de auteur een exacte kopie van de startpagina van een blog.
Net als inlogpagina's bevatten inschrijfformulieren meestal niets anders dan het formulier om uw gegevens in te voeren om u te abonneren. De pagina a) is dus leeg, b) levert geen waarde op voor gebruikers. Daarom moet u voorkomen dat zoekmachines ze naar SERP's trekken.
Een vuistregel: pagina's die nog in ontwikkeling zijn, moeten uit de buurt van zoekmachinecrawlers worden gehouden totdat ze helemaal klaar zijn voor bezoekers.
Mirror pages zijn identieke kopieën van uw pagina's op een aparte server/locatie. Ze worden beschouwd als technische duplicaten als ze worden gecrawld en geïndexeerd.
Speciale aanbiedingen en advertentiepagina's zijn alleen bedoeld om zichtbaar te zijn voor gebruikers nadat ze speciale acties hebben voltooid of gedurende een bepaalde periode (speciale aanbiedingen, evenementen, enz.). Nadat het evenement is afgelopen, hoeven deze pagina's door niemand meer te worden bekeken, inclusief zoekmachines.
En nu is de vraag: hoe verberg je alle bovengenoemde pagina's voor vervelende webspiders en zorg je ervoor dat de rest van je website zichtbaar blijft zoals het hoort?
Terwijl u de instructies voor zoekmachines instelt, hebt u twee opties. U kunt het crawlen beperken, of u kunt de indexering van een pagina beperken.
De eenvoudigste en meest directe manier om crawlers van zoekmachines te beperken om toegang te krijgen tot uw pagina's is door een robots.txt-bestand te maken. Met robots.txt-bestanden kunt u proactief alle ongewenste content uit de zoekresultaten houden. Met dit bestand kunt u de toegang beperken tot een enkele pagina, een hele directory of zelfs een enkele afbeelding of bestand.


De procedure is vrij eenvoudig. U maakt gewoon een.txt-bestand met de volgende velden:
Houd er rekening mee dat sommige crawlers (bijvoorbeeld Google) ook een extra veld ondersteunen met de naam Allow:. Zoals de naam al aangeeft, kunt u met Allow: expliciet de bestanden/mappen vermelden die gecrawld kunnen worden.
Hier worden enkele basisvoorbeelden van robots.txt-bestanden uitgelegd.


* in de User-agent -regel betekent dat alle zoekmachinebots de opdracht krijgen om geen van uw sitepagina's te crawlen, wat wordt aangegeven met /. Waarschijnlijk is dat wat u liever wilt vermijden, maar nu snapt u het idee.


In het bovenstaande voorbeeld voorkomt u dat de Image-bot van Google uw afbeeldingen in de geselecteerde directory crawlt.
Meer instructies over hoe u dergelijke bestanden handmatig schrijft, vindt u in de Google Developer's Guide.
Maar het proces van het maken van robots.txt kan volledig worden geautomatiseerd – er is een breed scala aan tools die in staat zijn om dergelijke bestanden te maken. Bijvoorbeeld, WebSite Auditor kan eenvoudig een robots.txt-bestand voor uw website compileren.
Wanneer u de tool start en een project voor uw website maakt, gaat u naar Sitestructuur > Pagina's, klikt u op het moersleutelpictogram en selecteert u Robots.txt.
Klik vervolgens op Add Rule en geef de instructies op. Kies een zoekbot en een directory of pagina waarvoor u het crawlen wilt beperken.

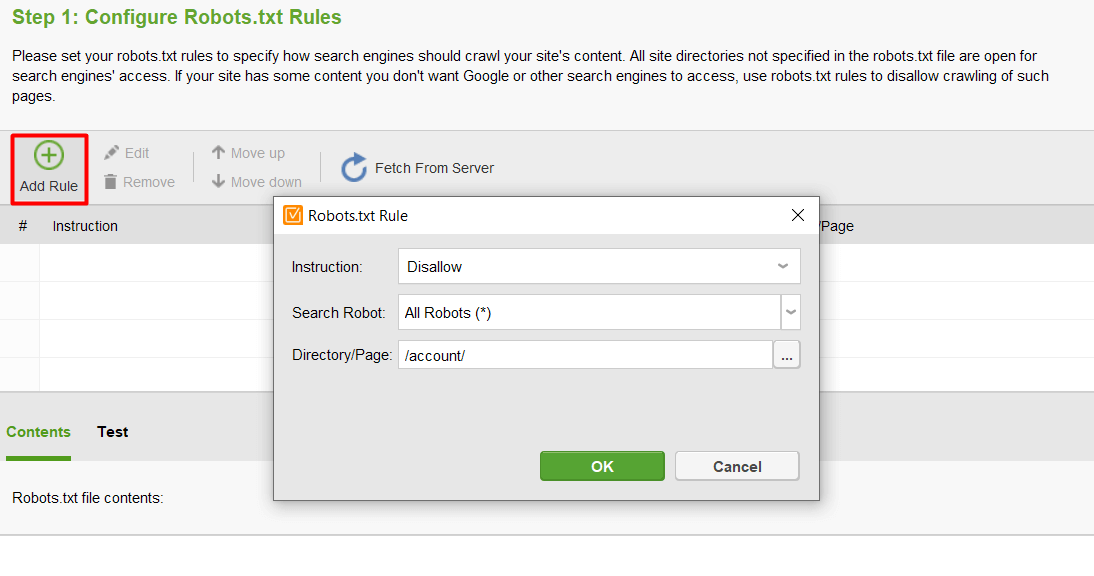
Zodra u klaar bent met alle instellingen, klikt u op Volgende. De tool genereert dan een robots.txt-bestand dat u vervolgens naar uw website kunt uploaden.
Om te zien welke bronnen geblokkeerd zijn voor crawlen en om te controleren of u niets hebt toegestaan dat wel gecrawld zou moeten worden, gaat u naar Sitestructuur > Sitecontrole en controleert u de sectie Bronnen die beperkt zijn voor indexering:
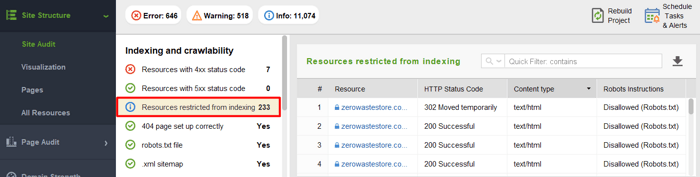

Houd er ook rekening mee dat het robots.txt-protocol puur adviserend is. Het is geen slot op uw sitepagina's, maar meer een "Privé - buiten houden". Robots.txt kan voorkomen dat "wetgetrouwe" bots (bijv. Google, Yahoo! en Bing-bots) toegang krijgen tot uw content. Kwaadaardige bots negeren het echter gewoon en gaan toch door uw content. Er is dus een risico dat uw privégegevens worden geschraapt, gecompileerd en hergebruikt onder het mom van fair use. Als u uw content 100% veilig wilt houden, moet u veiligere maatregelen invoeren (bijv. registratie toevoegen op een site, content verbergen onder een wachtwoord, enz.).
Dit zijn de meest voorkomende fouten die mensen maken bij het maken van robots.txt-bestanden. Lees dit gedeelte zorgvuldig.
1) Gebruik hoofdletters in de bestandsnaam. De bestandsnaam is robots.txt. Punt. Niet Robots.txt, en niet ROBOTS.txt
2) Het robots.txt-bestand niet in de hoofdmap plaatsen
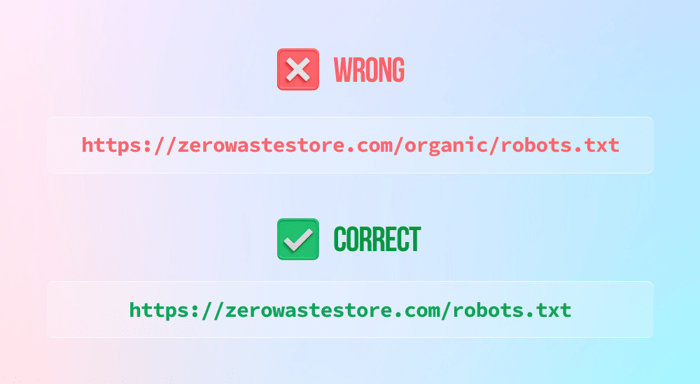

3) Blokkeer uw gehele website (tenzij u dat wilt) door de instructie 'niet toestaan' op de volgende manier te laten staan


4) Onjuist specificeren van de user-agent


5) Vermeld meerdere catalogi per disallow-regel. Elke pagina of directory heeft een aparte regel nodig


6) De user-agent-regel leeg laten
7) Alle bestanden in een directory opsommen. Als je de hele directory verbergt, hoef je niet elk afzonderlijk bestand op te sommen.


8) De regel met de instructies voor het niet toestaan helemaal niet vermelden


9) De sitemap niet vermelden onderaan het robots.txt-bestand
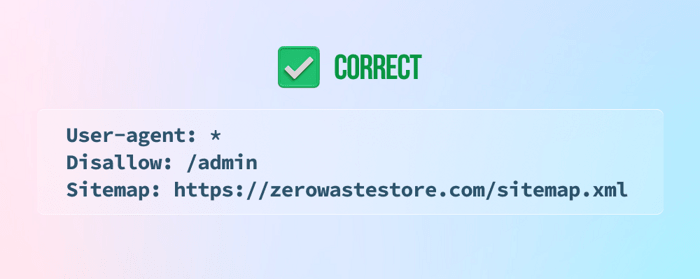

10) Noindex-instructies toevoegen aan het bestand
Door de robots noindex-metatag of de X-Robots-tag te gebruiken, kunnen zoekmachinebots uw pagina crawlen en openen, maar wordt voorkomen dat de pagina in de index terechtkomt en dus in de zoekresultaten verschijnt.
Laten we nu eens nader naar elke optie kijken.
Een robots noindex meta tag wordt in de HTML bron van uw pagina geplaatst (<head> sectie). Het proces van het maken van deze tags vereist slechts een klein beetje technische kennis en kan gemakkelijk worden gedaan door zelfs een junior SEO.
Wanneer Google bot de pagina ophaalt, ziet het een noindex metatag en neemt het deze pagina niet op in de webindex. De pagina wordt nog steeds gecrawld en bestaat op de opgegeven URL, maar zal niet verschijnen in zoekresultaten, ongeacht hoe vaak er vanaf een andere pagina naar wordt gelinkt.
<meta naam="robots" content="index, volgen">
Als u deze metatag aan de HTML-broncode van uw pagina toevoegt, geeft u de bot van een zoekmachine opdracht om deze pagina en alle links vanaf die pagina te indexeren.
<meta naam="robots" inhoud="index, nofollow">
Door 'follow' te veranderen in 'nofollow' beïnvloedt u het gedrag van een zoekmachinebot. De hierboven genoemde tagconfiguratie instrueert een zoekmachine om een pagina te indexeren, maar geen links te volgen die erop zijn geplaatst.
<meta name="robots" content="geenindex, volgen">
Deze metatag vertelt een zoekmachinebot dat hij de pagina waarop de metatag staat, moet negeren, maar alle links die erop staan, moet volgen.
<meta naam="robots" inhoud="geenindex, nofollow">
Als u deze tag op een pagina plaatst, betekent dit dat noch de pagina, noch de links op deze pagina worden gevolgd of geïndexeerd.
Naast een robots noindex-metatag kunt u een pagina verbergen door een HTTP-headerrespons in te stellen met een X-Robots-Tag met een noindex- of none- waarde.
Naast pagina's en HTML-elementen kunt u met X-Robots-Tag afzonderlijke PDF-bestanden, video's, afbeeldingen en andere niet-HTML-bestanden waarvoor het gebruik van robots-metatags niet mogelijk is, noindexen.
Het mechanisme lijkt veel op dat van een noindex-tag. Zodra een zoekbot op een pagina komt, retourneert de HTTP-respons een X-Robots-Tag-header met noindex-instructies. Een pagina of bestand wordt nog steeds gecrawld, maar verschijnt niet in de zoekresultaten.
Dit is het meest voorkomende voorbeeld van een HTTP-reactie met de instructie om een pagina niet te indexeren.
HTTP/1.1 200 OK
(…)
X-Robots-Tag: geenindex
(…)
U kunt het type zoekbot opgeven als u uw pagina voor bepaalde bots wilt verbergen. Het onderstaande voorbeeld laat zien hoe u een pagina voor elke andere zoekmachine dan Google kunt verbergen en alle bots kunt beperken om de links op die pagina te volgen:
X-Robots-Tag: googlebot: nofollow
X-Robots-Tag: anderebot: noindex, nofollow
Als u het type robot niet opgeeft, zijn de instructies geldig voor alle typen crawlers.
Als u de indexering van bepaalde bestandstypen op uw hele website wilt beperken, kunt u de X-Robots-Tag-responsinstructies toevoegen aan de configuratiebestanden van de webserversoftware van uw site.
Zo beperkt u alle PDF-bestanden op een Apache-server:
<Bestanden ~ "\.pdf$">
Koptekstset X-Robots-Tag "noindex, nofollow"
</Bestanden>
En dit zijn dezelfde instructies voor NGINX:
locatie ~* \.pdf$ {
add_header X-Robots-Tag "geen index, nofollow";
}
Om de indexering van één enkel element te beperken, is het patroon voor Apache als volgt:
# Het htaccess-bestand moet in de directory van het overeenkomende bestand worden geplaatst.
<Bestanden "unicorn.pdf">
Koptekstset X-Robots-Tag "noindex, nofollow"
</Bestanden>
En dit is hoe je de indexering van één element voor NGINX beperkt:
locatie = /secrets/unicorn.pdf {
add_header X-Robots-Tag "geen index, nofollow";
}
Hoewel een robots noindex-tag een eenvoudigere oplossing lijkt om te voorkomen dat uw pagina's worden geïndexeerd, zijn er enkele gevallen waarin het gebruik van een X-Robots-Tag voor pagina's een betere optie is:
Vergeet echter niet dat alleen Google de X-Robots-Tag-instructies volgt. Wat de rest van de zoekmachines betreft, is er geen garantie dat zij de tag correct zullen interpreteren. Seznam ondersteunt bijvoorbeeld helemaal geen x-robots-tags. Dus als u van plan bent dat uw website op verschillende zoekmachines wordt weergegeven, moet u een robots noindex-tag gebruiken in de HTML-fragmenten.
De meest voorkomende fouten die gebruikers maken bij het werken met de noindex-tags zijn de volgende:
1) Een noindexed pagina of element toevoegen aan het robots.txt bestand. Robots.txt beperkt crawlen, dus zullen zoekrobots niet naar de pagina komen en de noindex richtlijnen zien. Dit betekent dat uw pagina geïndexeerd kan worden zonder inhoud en toch in de zoekresultaten kan verschijnen.
Om te controleren of een van uw documenten met een noindex-tag in het robots.txt-bestand terecht is gekomen, controleert u de kolom Robots-instructies in de sectie Sitestructuur > Pagina's van WebSite Auditor.
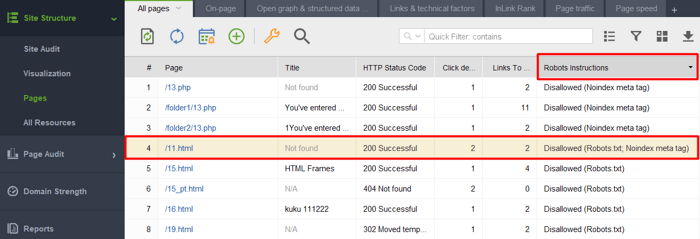
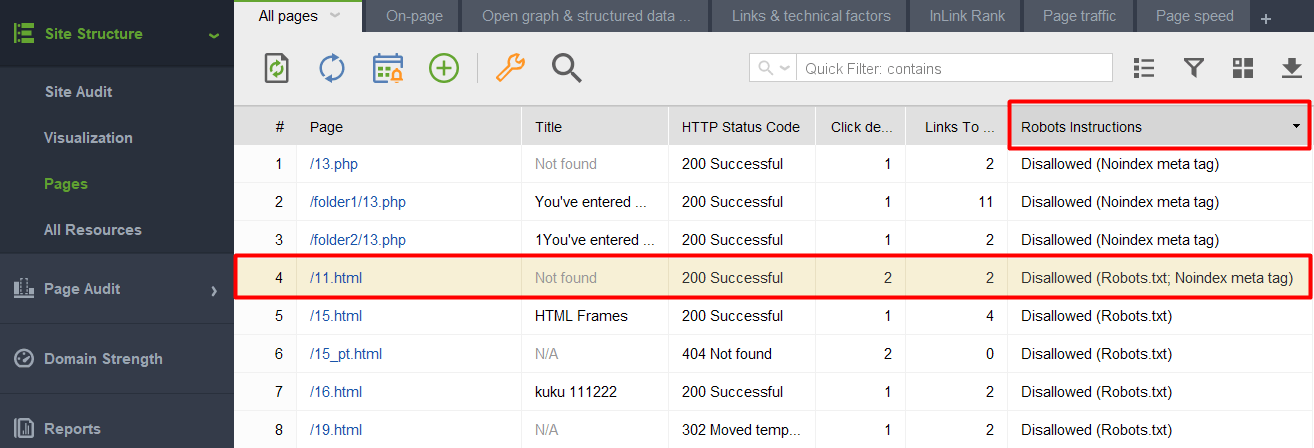
Let op: Vergeet niet om de expertopties in te schakelen en de optie Volg robots.txt-instructies uit te schakelen wanneer u uw project samenstelt. Zo ziet de tool de instructies wel, maar hoeft deze niet te worden gevolgd.
2) Hoofdletters gebruiken in tag-richtlijnen. Volgens Google zijn alle richtlijnen hoofdlettergevoelig, dus wees voorzichtig.
Nu we de belangrijkste problemen met de indexering van inhoud min of meer duidelijk hebben gemaakt, gaan we verder met een aantal niet-standaardgevallen die speciale aandacht verdienen.
1) Zorg ervoor dat de pagina's die u niet wilt laten indexeren niet in uw sitemap zijn opgenomen. Een sitemap is eigenlijk de manier om zoekmachines te vertellen waar ze eerst naartoe moeten gaan bij het crawlen van uw website. En er is geen reden om zoekrobots te vragen de pagina's te bezoeken die u niet wilt dat ze zien.
2) Als u toch een pagina wilt de-indexeren die al in de sitemap staat, verwijder de pagina dan niet uit de sitemap totdat deze opnieuw is gecrawld en gede-indexeerd door zoekrobots. Anders kan de de-indexering langer duren dan verwacht.
3) Bescherm de pagina's die privégegevens bevatten met wachtwoorden. Wachtwoordbeveiliging is de meest betrouwbare manier om gevoelige content te verbergen, zelfs voor bots die de robots.txt-instructies niet volgen. Zoekmachines kennen uw wachtwoorden niet, dus ze komen niet op de pagina, zien de gevoelige content niet en brengen de pagina niet naar een SERP.
4) Om ervoor te zorgen dat zoekrobots de pagina zelf niet indexeren, maar wel alle links van een pagina volgen en de inhoud op die URL's indexeren, stelt u de volgende richtlijn in
<meta name="robots" content="geenindex, volgen">
Dit is een gangbare praktijk voor interne zoekresultatenpagina's, die weliswaar veel nuttige links bevatten, maar zelf geen enkele waarde hebben.
5) Indexeringsbeperkingen kunnen worden gespecificeerd voor een specifieke robot. U kunt bijvoorbeeld uw pagina vergrendelen voor nieuwsbots, afbeeldingsbots, enz. De namen van de bots kunnen worden gespecificeerd voor elk type instructie, of dat nu een robots.txt-bestand, robots-metatag of X-Robots-Tag is.
U kunt bijvoorbeeld uw pagina's specifiek verbergen voor de ChatGPT-bot met robots.txt. Sinds de aankondiging van ChatGPT-plugins en GPT-4 (wat betekent dat OpenAI nu informatie van het web kan halen), maken website-eigenaren zich zorgen over het gebruik van hun content. De kwesties van citaten, plagiaat en auteursrecht werden acuut voor veel sites.
Nu is de SEO-wereld verdeeld: sommigen zeggen dat we GPTBot moeten blokkeren om toegang te krijgen tot onze sites, anderen zeggen het tegenovergestelde, en de derde zegt dat we moeten wachten tot er iets duidelijker wordt. Hoe dan ook, je hebt een keuze.
En als u er stellig van overtuigd bent dat u GPTBot moet blokkeren, kunt u dat als volgt doen:
Als u uw hele site wilt sluiten.
Gebruikersagent: GPTBot
Niet toestaan: /
Als u slechts een bepaald deel van uw site wilt sluiten.
Gebruikersagent: GPTBot
Toestaan: /directory-1/
Niet toestaan: /directory-2/
6) Gebruik geen noindex-tag in A/B-tests wanneer een deel van uw gebruikers wordt doorgestuurd van pagina A naar pagina B. Als noindex wordt gecombineerd met een 301 (permanente) doorverwijzing, krijgen zoekmachines de volgende signalen:
Hierdoor verdwijnen zowel pagina A als pagina B uit de index.
Om uw A/B-test correct in te stellen, gebruikt u een 302-redirect (die tijdelijk is) in plaats van 301. Hierdoor kunnen zoekmachines de oude pagina in de index houden en deze terughalen als u de test hebt voltooid. Als u meerdere versies van een pagina test (A/B/C/D etc.), gebruik dan de tag rel=canonical om de canonieke versie van een pagina te markeren die in SERP's moet komen.
7) Gebruik een noindex-tag om tijdelijke landingspagina's te verbergen. Als u pagina's met speciale aanbiedingen, advertentiepagina's, kortingen of een ander type content verbergt dat niet mag lekken, is het niet het beste idee om deze content te verbieden met een robots.txt-bestand. Supernieuwsgierige gebruikers kunnen deze pagina's nog steeds bekijken in uw robots.txt-bestand. In dit geval is het beter om noindex te gebruiken, om de 'geheime' URL niet per ongeluk openbaar te maken.
Nu weet u de basis van hoe u bepaalde pagina's van uw website kunt vinden en verbergen voor de aandacht van de bots van zoekmachines. En zoals u ziet, is het proces eigenlijk eenvoudig. Meng alleen niet meerdere soorten instructies op één pagina en wees voorzichtig om de pagina's die wel in de zoekresultaten moeten verschijnen, niet te verbergen.
Heb ik iets gemist? Deel je vragen in de comments.
| Linking websites | N/A |
| Backlinks | N/A |
| InLink Rank | N/A |








