39415
•
10 分で読めます
•


サイト ページのインデックス作成は、検索エンジン最適化プロセスの開始点です。エンジン ボットがコンテンツにアクセスできるようにすると、ページが訪問者を受け入れる準備ができており、技術的な問題がなく、SERP に表示されるようになるため、包括的なインデックス作成は一見すると大きなメリットのように思えます。
ただし、ランキングを確保するには、特定の種類のページを SERP から遠ざけた方がよいでしょう。つまり、それらのページをインデックスから隠す必要があります。この記事では、検索エンジンから隠すコンテンツの種類とその方法を説明します。
では、さっそく本題に入りましょう。SERP に表示されないように、検索エンジンから非表示にしたほうがよいページのリストを以下に示します。
ページに個人情報が含まれている場合、直接の検索トラフィックからコンテンツを保護することは必須です。これらのページには、会社の機密情報、アルファ製品に関する情報、ユーザー プロファイル情報、プライベートな通信、支払いデータなどが含まれます。プライベートなコンテンツはデータ所有者以外の誰にも表示されないようにする必要があるため、Google (または任意の検索エンジン) はこれらのページを幅広いユーザーに公開すべきではありません。
ログイン フォームがホームページではなく別のページに配置されている場合、このページを SERP に表示する必要はほとんどありません。このようなページはユーザーにとって追加の価値がなく、 薄いコンテンツと見なされる可能性があります。
これらは、購入、登録など、Web サイトでのアクションが成功した後にユーザーが目にするページです。これらのページもコンテンツが薄く、検索者にとって追加の価値がほとんどないかまったくない可能性があります。
このタイプのページのコンテンツは、Web サイトのメイン ページのコンテンツと重複しているため、クロールおよびインデックス作成時にこれらのページは完全に重複したコンテンツとして扱われます。
これは、サイズや色のみが異なる製品を多数扱う大規模な電子商取引 Web サイトによくある問題です。Google はこれらの違いを判別できず、重複コンテンツとして扱う可能性があります。
ユーザーが SERP からあなたのウェブサイトに来るとき、彼らはあなたのリンクをクリックして、自分のクエリに対する答えを見つけることを期待しています。たくさんのリンクがある別の内部 SERP ではありません。そのため、内部 SERP がインデックスに登録されても、ページ滞在時間は短くなり、直帰率は高くなる可能性があります。
ブログの投稿がすべて 1 人の著者によって書かれたものである場合、著者のプロフィールページはブログのホームページの完全な複製になります。
ログイン ページと同様に、サブスクリプション フォームには通常、サブスクリプションに必要なデータを入力するためのフォームしかありません。そのため、ページは a) 空で、b) ユーザーに価値を提供しません。そのため、検索エンジンがユーザーを SERP に誘導しないように制限する必要があります。
経験則: 開発中のページは、訪問者に完全に公開できる状態になるまで、検索エンジンのクローラーから遠ざけておく必要があります。
ミラー ページは、別のサーバー/場所にあるページの同一コピーです。クロールおよびインデックス化されると、技術的に重複しているとみなされます。
特別オファーや広告ページは、ユーザーが特別なアクションを完了した後、または特定の期間(特別オファー、イベントなど)にのみユーザーに表示されるようにするものです。イベント終了後は、検索エンジンを含め、誰にもこれらのページが表示される必要はありません。
ここで問題となるのは、上記のページをすべて厄介なスパイダーから隠し、Web サイトの残りの部分を本来あるべき状態で表示し続けるにはどうすればよいかということです。
検索エンジンの指示を設定する際には、2 つのオプションがあります。クロールを制限するか、ページのインデックス作成を制限することができます。
おそらく、検索エンジンのクローラーによるページへのアクセスを制限する最も簡単で直接的な方法は、robots.txt ファイルを作成することです。robots.txt ファイルを使用すると、不要なコンテンツをすべて積極的に検索結果から除外できます。このファイルを使用すると、1 つのページ、ディレクトリ全体、または 1 つの画像やファイルへのアクセスを制限できます。


手順は非常に簡単です。次のフィールドを含む.txt ファイルを作成するだけです。
一部のクローラー (Google など) は、 Allow: という追加フィールドもサポートしていることに注意してください。名前が示すように、 Allow:を使用すると、クロールできるファイル/フォルダーを明示的にリストできます。
ここでは、robots.txt ファイルの基本的な例をいくつか説明します。


User-agent行の*は、すべての検索エンジン ボットが、 /で示されるサイトのページをクロールしないように指示されていることを意味します。おそらく、これは避けたいことだと思いますが、これで意味は理解できたと思います。


上記の例では、選択したディレクトリ内の画像を Google の画像ボットがクロールすることを制限します。
このようなファイルを手動で作成する方法の詳細については、Google デベロッパー ガイドをご覧ください。
しかし、robots.txt の作成プロセスは完全に自動化できます。このようなファイルを作成できるツールは多岐にわたります。たとえば、 WebSite Auditor を使用すると、Web サイトの robots.txt ファイルを簡単にコンパイルできます。
ツールを起動して Web サイトのプロジェクトを作成するときに、 「サイト構造」 > 「ページ」に移動し、レンチ アイコンをクリックして、 「Robots.txt」を選択します。
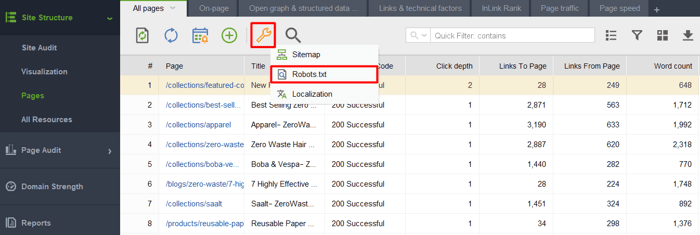
次に、 「ルールの追加」をクリックして指示を指定します。検索ボットと、クロールを制限するディレクトリまたはページを選択します。

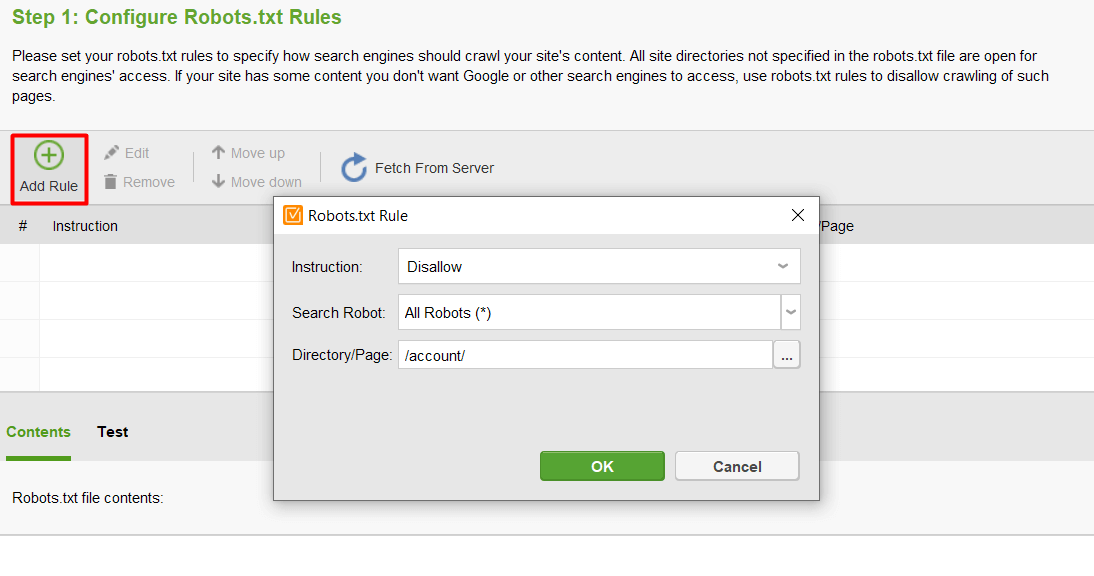
すべての設定が完了したら、 「次へ」をクリックして、ツールによって robots.txt ファイルが生成され、Web サイトにアップロードできるようにします。
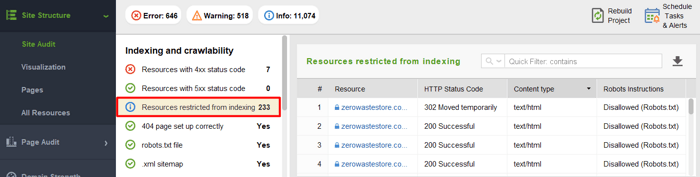
クロールがブロックされているリソースを確認し、クロールされるべきものを禁止していないことを確認するには、 [サイト構造] > [サイト監査]に移動し、 [インデックス作成が制限されているリソース]セクションを確認します。

また、robots.txt プロトコルはあくまでも助言的なものであることに注意してください。これは、サイト ページをロックするのではなく、「プライベート - 立ち入り禁止」のようなものです。robots.txt は、「法を遵守する」ボット (Google、Yahoo!、Bing ボットなど) がコンテンツにアクセスするのを防ぐことができます。ただし、悪意のあるボットはこれを無視して、とにかくコンテンツにアクセスします。そのため、公正使用を装って、プライベート データがスクレイピングされ、コンパイルされ、再利用されるリスクがあります。コンテンツを 100% 安全に保ちたい場合は、より安全な対策 (サイトへの登録の追加、パスワードでコンテンツを非表示にするなど) を導入する必要があります。
robots.txt ファイルを作成するときによくある間違いを以下に示します。この部分を注意深くお読みください。
1)ファイル名に大文字を使用する。ファイル名は robots.txt です。Robots.txt でも ROBOTS.txt でもありません。
2) robots.txtファイルをメインディレクトリに配置しない
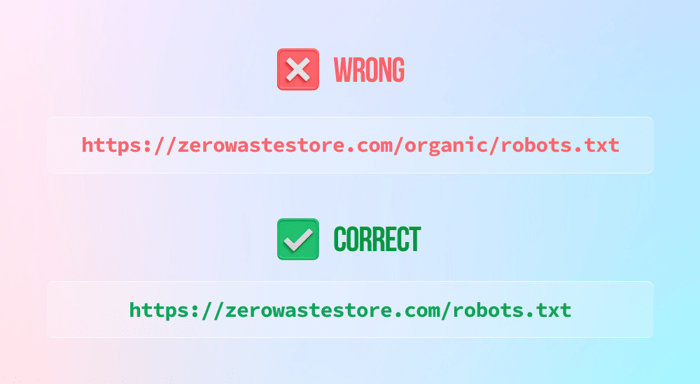

3)以下のように禁止命令を残して、ウェブサイト全体をブロックする(希望しない限り)


4)ユーザーエージェントの指定が間違っている


5) 1行に複数のカタログを記載することは禁止されています。各ページまたはディレクトリには別の行が必要です。


6)ユーザーエージェント行を空のままにする
7)ディレクトリ内のすべてのファイルをリストします。ディレクトリ全体を隠している場合は、すべてのファイルをリストする必要はありません。


8)禁止命令の行に全く触れていない


9) robots.txtファイルの下部にサイトマップを記載していない
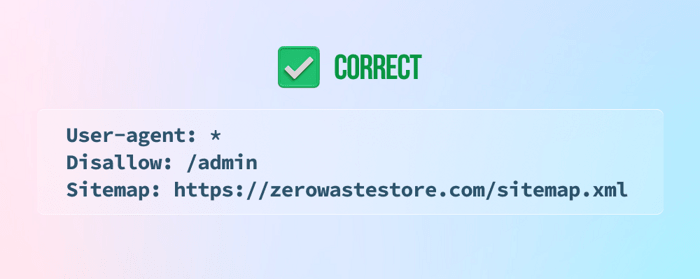

10)ファイルにnoindex命令を追加する
robots noindex メタ タグまたは X-Robots タグを使用すると、検索エンジン ボットがページをクロールしてアクセスできるようになりますが、ページがインデックスに登録されなくなり、検索結果に表示されなくなります。
それでは、それぞれのオプションを詳しく見ていきましょう。
robots noindex メタ タグは、ページの HTML ソース (<head> セクション) に配置されます。これらのタグを作成するプロセスには、ほんの少しの技術的知識しか必要ありません。初心者の SEO でも簡単に実行できます。
Google ボットがページを取得すると、noindex メタ タグが見つかり、このページはウェブ インデックスに含まれません。ページは引き続きクロールされ、指定された URL に存在しますが、他のページからリンクされる頻度に関係なく、検索結果には表示されません。
<meta name="ロボット" content="インデックス、フォロー">
このメタ タグをページの HTML ソースに追加すると、検索エンジン ボットにこのページとそのページからのすべてのリンクをインデックスするように指示します。
<meta name="ロボット" content="インデックス、nofollow">
「follow」を「nofollow」に変更すると、検索エンジン ボットの動作に影響を与えます。上記のタグ構成は、検索エンジンにページをインデックスするように指示しますが、ページに配置されたリンクをたどらないようにします。
<meta name="robots" content="noindex, follow">
このメタタグは、検索エンジンボットに、そのタグが配置されているページを無視し、そのページに配置されたすべてのリンクをたどるように指示します。
<meta name="ロボット" content="noindex, nofollow">
このタグをページに配置すると、そのページもそのページに含まれるリンクもフォローされず、インデックスも作成されないことを意味します。
robots noindex メタ タグの他に、 noindexまたはnone値を持つ X-Robots-Tag を使用して HTTP ヘッダー応答を設定することで、ページを非表示にすることができます。
X-Robots-Tag を使用すると、ページや HTML 要素に加えて、ロボット メタ タグを使用できない PDF ファイル、ビデオ、画像、その他の HTML 以外のファイルを個別に noindex 化できます。
このメカニズムは、noindex タグとほぼ同じです。検索ボットがページにアクセスすると、HTTP 応答は noindex 指示を含む X-Robots-Tag ヘッダーを返します。ページまたはファイルは引き続きクロールされますが、検索結果には表示されません。
これは、ページをインデックスしないように指示する HTTP 応答の最も一般的な例です。
HTTP/1.1 200 OK
(…)
X-Robots-タグ: noindex
(…)
特定のボットからページを非表示にする必要がある場合は、検索ボットの種類を指定できます。以下の例は、Google 以外の検索エンジンからページを非表示にし、すべてのボットがそのページ上のリンクをたどることを制限する方法を示しています。
X-Robots-タグ: googlebot: nofollow
X-Robots-タグ: otherbot: noindex、nofollow
ロボットの種類を指定しない場合は、すべての種類のクローラーに対して手順が有効になります。
ウェブサイト全体で特定の種類のファイルのインデックス作成を制限するには、サイトのウェブ サーバー ソフトウェアの構成ファイルに X-Robots-Tag 応答命令を追加します。
Apache ベースのサーバー上のすべての PDF ファイルを制限する方法は次のとおりです。
<ファイル ~ "\.pdf$">
ヘッダーに X-Robots-Tag を「noindex, nofollow」に設定
</ファイル>
NGINX の場合も同様の手順になります:
場所 ~* \.pdf$ {
add_header X-Robots-Tag "noindex, nofollow";
}
1 つの要素のインデックス作成を制限するには、Apache のパターンは次のようになります。
# htaccess ファイルは、一致したファイルのディレクトリに配置する必要があります。
<ファイル "unicorn.pdf">
ヘッダーに X-Robots-Tag を「noindex, nofollow」に設定
</ファイル>
これは、NGINX の 1 つの要素のインデックス作成を制限する方法です。
場所 = /secrets/unicorn.pdf {
add_header X-Robots-Tag "noindex, nofollow";
}
robots noindex タグはページのインデックスを制限するためのより簡単な解決策のように思えますが、ページに X-Robots-Tag を使用する方がよい場合もあります。
ただし、X-Robots-Tag の指示に確実に従うのは Google だけであることを覚えておいてください。他の検索エンジンについては、タグを正しく解釈する保証はありません。たとえば、Seznam は x-robots-tags をまったくサポートしていません。したがって、Web サイトをさまざまな検索エンジンに表示することを計画している場合は、HTML スニペットでrobots noindex タグを使用する必要があります。
noindex タグを使用する際にユーザーが犯す最も一般的な間違いは次のとおりです。
1) robots.txt ファイルに noindex されたページまたは要素を追加します。robots.txtはクロールを制限するため、検索ボットはページにアクセスできず、 noindex ディレクティブも表示されません。つまり、コンテンツがなくてもページがインデックスされ、検索結果に表示される可能性があります。
noindex タグが付いたページが robots.txt ファイルに含まれているかどうかを確認するには、 WebSite Auditorの [サイト構造] > [ページ]セクションにある[Robots 指示]列を確認します。
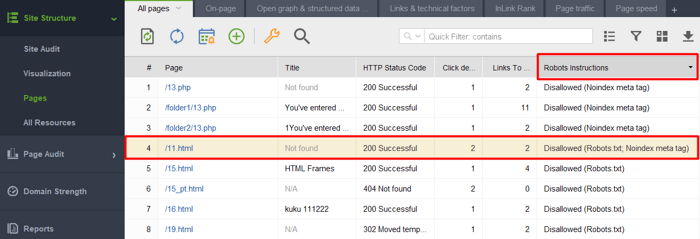
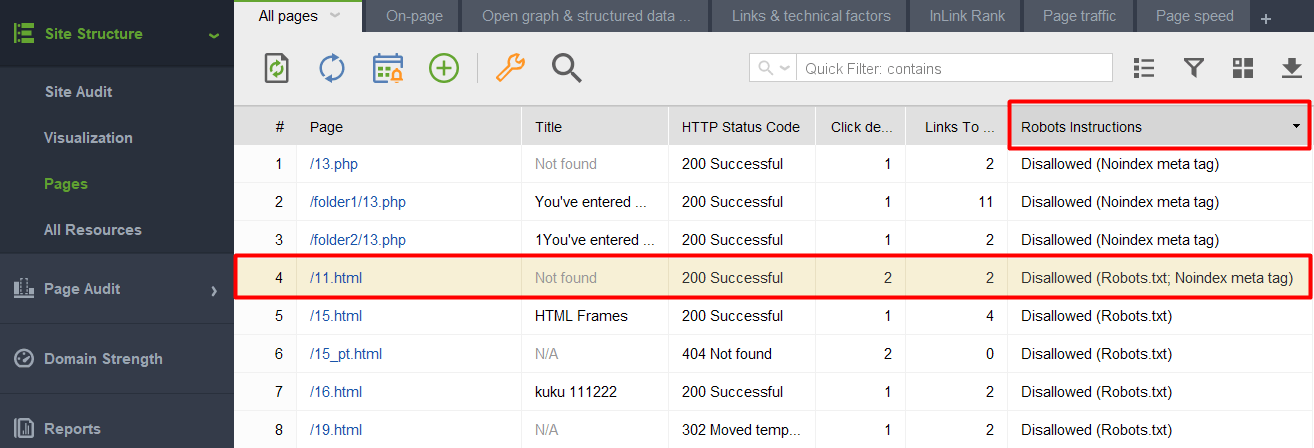
注:プロジェクトを組み立てるときに、エキスパート オプションを有効にして、「robots.txt の指示に従う」オプションのチェックを外し、ツールが指示を認識してもそれに従わないようにすることを忘れないでください。
2) タグディレクティブで大文字を使用する。Google によると、すべてのディレクティブは大文字と小文字を区別するので注意してください。
主要なコンテンツのインデックス作成の問題についてはすべてほぼ明らかになったので、次に、特に言及する価値のあるいくつかの非標準のケースに移りましょう。
1)インデックスに登録したくないページがサイトマップに含まれていないことを確認します。サイトマップは、実際には検索エンジンに Web サイトをクロールするときに最初にどこに行くべきかを伝える方法です。検索ボットに表示させたくないページにアクセスするように要求する理由はありません。
2)それでも、サイトマップにすでに存在するページのインデックスを解除する必要がある場合は、検索ロボットによって再クロールされインデックスが解除されるまで、サイトマップからページを削除しないでください。そうしないと、インデックス解除に予想よりも時間がかかる可能性があります。
3) プライベートデータを含むページをパスワードで保護します。パスワード保護は、robots.txt の指示に従わないボットからでも機密コンテンツを隠す最も確実な方法です。検索エンジンはパスワードを知らないため、ページにアクセスできず、機密コンテンツも表示されず、ページが SERP に表示されることもありません。
4)検索ボットがページ自体をインデックスしないようにし、ページにあるすべてのリンクをたどり、それらのURLのコンテンツをインデックスするには、次のディレクティブを設定します。
<meta name="robots" content="noindex, follow">
これは、多くの有用なリンクが含まれているものの、それ自体に価値がない内部検索結果ページでは一般的な方法です。
5) 特定のロボットに対してインデックス作成の制限を指定できます。たとえば、ニュース ボットや画像ボットなどからページをロックできます。ボットの名前は、robots.txt ファイル、robots メタ タグ、X-Robots-Tag など、あらゆるタイプの指示に対して指定できます。
たとえば、robots.txt を使用して、ChatGPT ボットからページを非表示にすることができます。ChatGPT プラグインと GPT-4 (OpenAI が Web から情報を取得できるようになった) の発表以来、Web サイトの所有者はコンテンツの使用について懸念しています。多くのサイトで、引用、盗用、著作権の問題が深刻化しました。
現在、 SEO の世界は分裂しています。GPTBot がサイトにアクセスできないようにブロックすべきだと主張する人もいれば、その逆を主張する人もおり、さらに、何かが明らかになるまで待つ必要があると主張する人もいます。いずれにせよ、選択肢はあります。
GPTBot をブロックする必要があると確信している場合は、次の手順に従ってください。
サイト全体を閉じたい場合。
ユーザーエージェント: GPTBot
許可しない: /
サイトの特定の部分だけを閉じたい場合。
ユーザーエージェント: GPTBot
許可: /directory-1/
許可しない: /directory-2/
6) ユーザーの一部がページ A からページ B にリダイレクトされる場合、A/B テストで noindex タグを使用しないでください。noindexが 301 (永続的) リダイレクトと組み合わされている場合、検索エンジンは次のシグナルを受け取ります。
その結果、ページ A と B の両方がインデックスから消えます。
A/B テストを正しく設定するには、301 ではなく 302 リダイレクト (一時的) を使用します。これにより、検索エンジンは古いページをインデックスに保持し、テストの終了時にそのページを戻します。ページの複数のバージョン (A/B/C/D など) をテストしている場合は、rel=canonical タグを使用して、SERP に表示されるページの正規バージョンをマークします。
7) 一時的なランディング ページを非表示にするには、noindex タグを使用します。特別オファー、広告ページ、割引、または漏洩してはならないあらゆる種類のコンテンツを含むページを非表示にする場合、robots.txt ファイルでこれらのコンテンツを禁止するのは最適なアイデアではありません。好奇心旺盛なユーザーは、robots.txt ファイル内でこれらのページを引き続き表示できるためです。この場合は、誤って「秘密の」URL を公開しないように、 noindexを使用することをお勧めします。
これで、ウェブサイトの特定のページを見つけて、検索エンジンのボットの注意から隠す方法の基本がわかりました。そして、ご覧のとおり、プロセスは実際には簡単です。1 つのページに複数の種類の指示を混在させないようにし、検索に表示される必要があるページを隠さないように注意してください。
何か見逃していることはありませんか? コメント欄で質問を共有してください。


