110399
•
20 minutes de lecture
•


Cette liste de contrôle décrit tous les rouages d'un audit technique de site, de la théorie à la pratique.
Vous apprendrez quels fichiers techniques existent, pourquoi les problèmes de référencement se produisent et comment les résoudre et les prévenir à l'avenir afin que vous soyez toujours à l'abri des baisses soudaines de classement .
En cours de route, je montrerai quelques outils d'audit SEO, à la fois populaires et peu connus, pour effectuer un audit technique de site Web sans tracas.
Le nombre d'étapes de votre liste de contrôle technique SEO dépendra des objectifs et du type de sites que vous allez examiner. Notre objectif était de rendre cette liste de contrôle universelle, couvrant toutes les étapes importantes des audits SEO techniques.
1. Accédez aux outils d'analyse de site et aux webmasters
Pour effectuer un audit technique de votre site, vous aurez besoin d'outils d'analyse et de webmaster, et c'est très bien si vous les avez déjà configurés sur votre site Web. Avec Google Analytics , Google Search Console , Bing Webmaster Tools , etc., vous disposez déjà d'une grande quantité de données nécessaires pour une vérification de base du site .
2. Vérifiez la sécurité du domaine
Si vous auditez un site Web existant qui a chuté du classement, excluez d'abord et avant tout la possibilité que le domaine soit soumis à des sanctions des moteurs de recherche.
Pour cela, consultez Google Search Console. Si votre site a été pénalisé pour la création de liens black-hat, ou s'il a été piraté, vous verrez un avis correspondant dans l'onglet Sécurité et actions manuelles de la console. Assurez-vous de répondre à l'avertissement que vous voyez dans cet onglet avant de poursuivre l'audit technique de votre site. Si vous avez besoin d'aide, consultez notre guide sur la façon de gérer les pénalités manuelles et algo .
Si vous auditez un tout nouveau site qui doit être lancé, assurez-vous de vérifier que votre domaine n'est pas compromis. Pour plus de détails, consultez nos guides sur la façon de choisir les domaines expirés et sur la façon de ne pas se retrouver piégé dans le bac à sable de Google lors du lancement d'un site Web.
Maintenant que nous en avons terminé avec les travaux préparatoires, passons à l'audit SEO technique de votre site web, étape par étape.
D'une manière générale, il existe deux types de problèmes d'indexation. La première est lorsqu'une URL n'est pas indexée alors qu'elle est censée l'être. L'autre est lorsqu'une URL est indexée alors qu'elle n'est pas censée l'être. Alors comment vérifier le nombre d'URL indexées de votre site ?
Pour voir quelle part de votre site Web est réellement parvenue dans l'index de recherche, consultez le rapport de couverture dans Google Search Console . Le rapport indique combien de vos pages sont actuellement indexées, combien sont exclues et quels sont certains des problèmes d'indexation sur votre site Web.
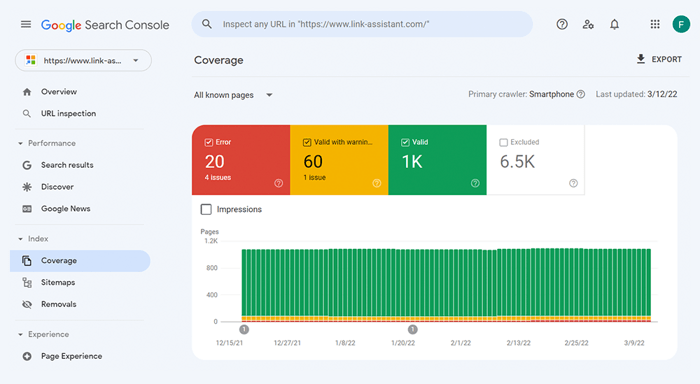

Le premier type de problèmes d'indexation est généralement marqué comme une erreur. Les erreurs d'indexation se produisent lorsque vous avez demandé à Google d'indexer une page, mais qu'elle est bloquée. Par exemple, une page a été ajoutée à un sitemap, mais est marquée avec la balise noindex ou est bloquée avec robots.txt.
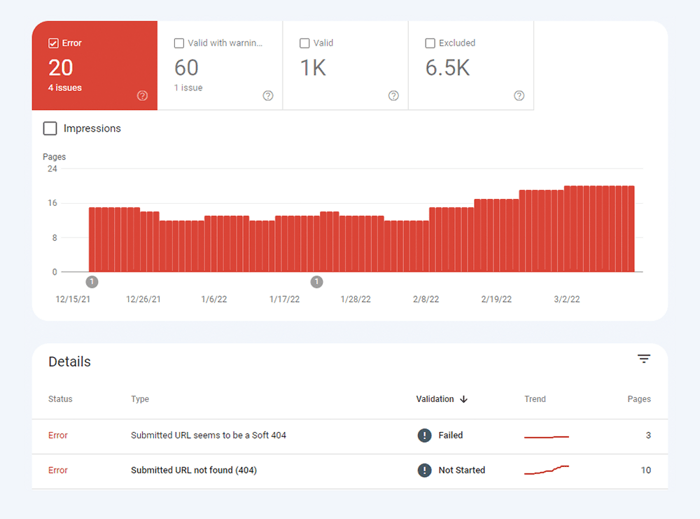
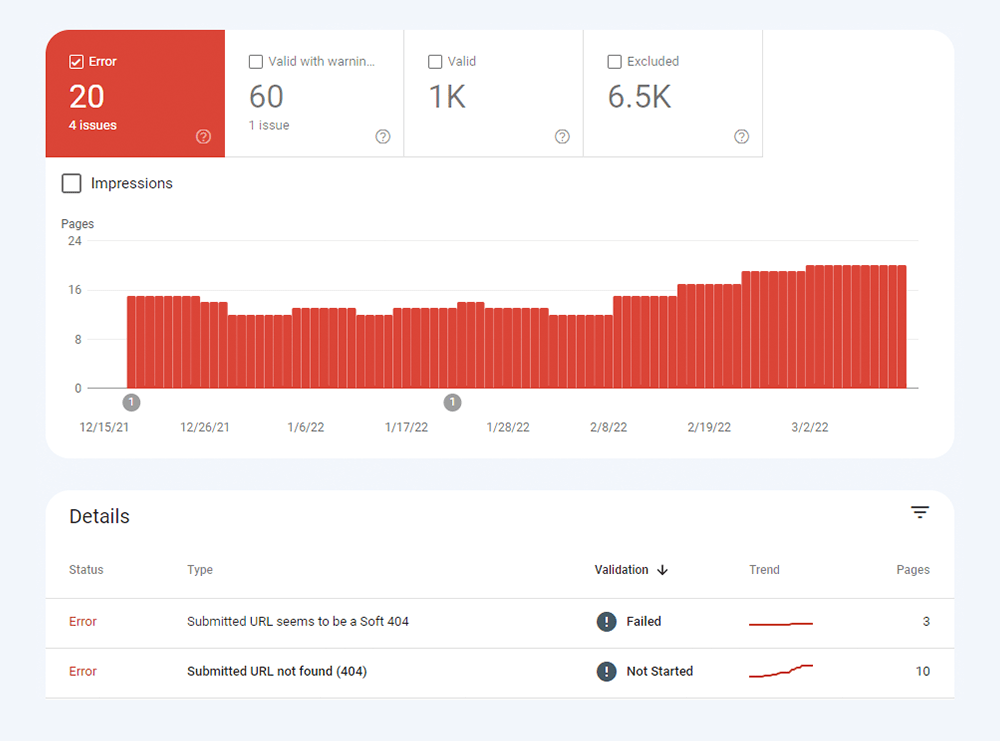
L'autre type de problèmes d'indexation est lorsque la page est indexée, mais Google n'est pas certain qu'elle était censée être indexée. Dans Google Search Console, ces pages sont généralement marquées comme valides avec des avertissements .
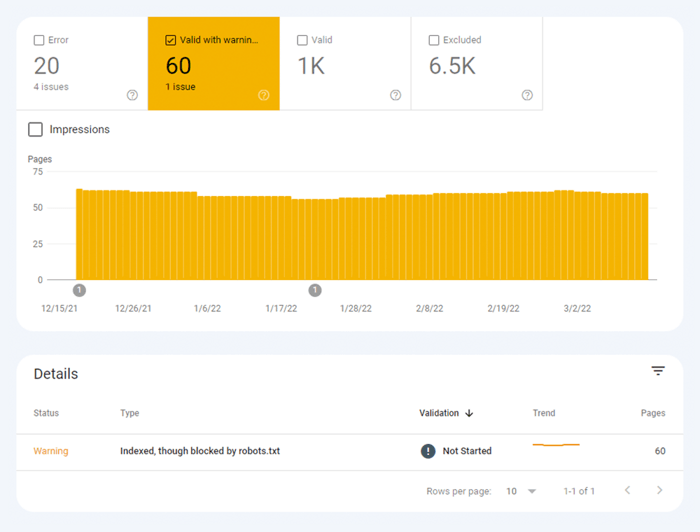

Pour une page individuelle, exécutez l' outil d'inspection d'URL dans la Search Console pour examiner comment le robot de recherche de Google la voit. Appuyez sur l'onglet correspondant ou collez l'URL complète dans la barre de recherche en haut, et il récupérera toutes les informations sur l'URL, la façon dont elle a été analysée la dernière fois par le robot de recherche.
Ensuite, vous pouvez cliquer sur Test Live URL et voir encore plus de détails sur la page : le code de réponse, les balises HTML, la capture d'écran du premier écran, etc.
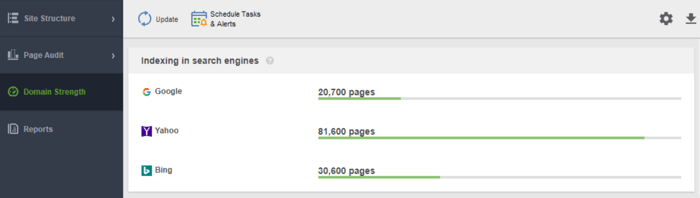
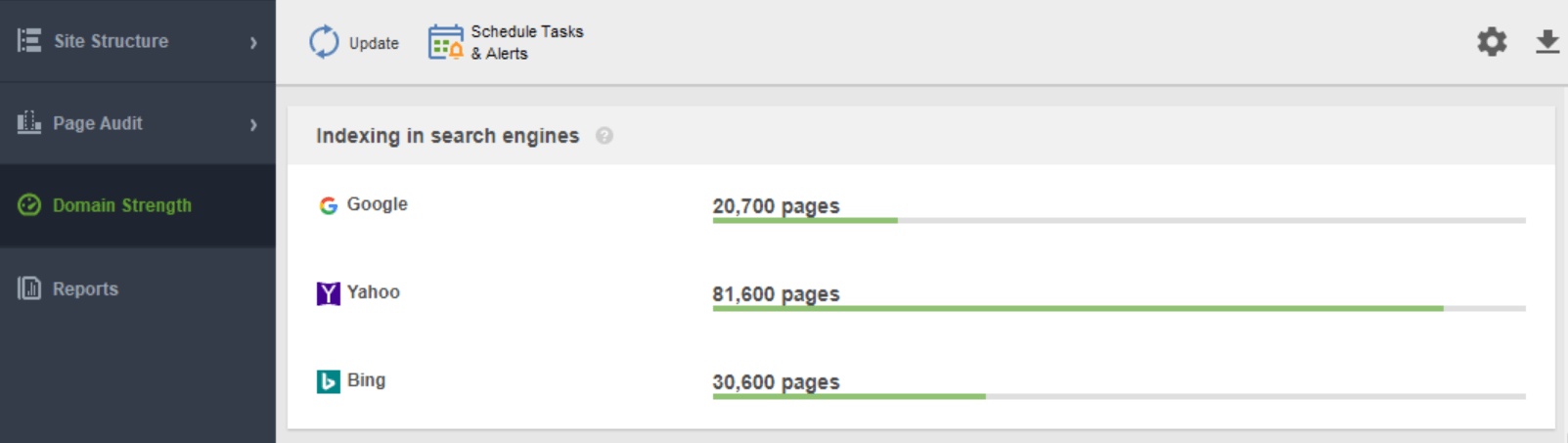
Un autre outil pour surveiller votre indexation est WebSite Auditor . Lancez le logiciel et collez l'URL de votre site Web pour créer un nouveau projet et procéder à l'audit de votre site. Une fois l'exploration terminée, vous verrez tous les problèmes et avertissements dans le module Structure du site de WebSite Auditor. Dans le rapport Domain Strength , vérifiez le nombre de pages indexées, non seulement dans Google, mais également dans d'autres moteurs de recherche.
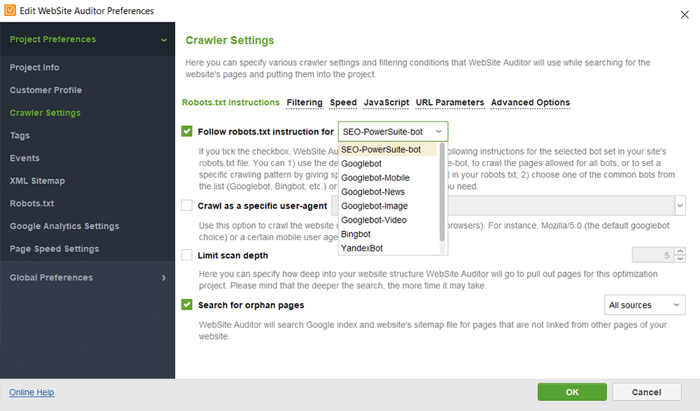
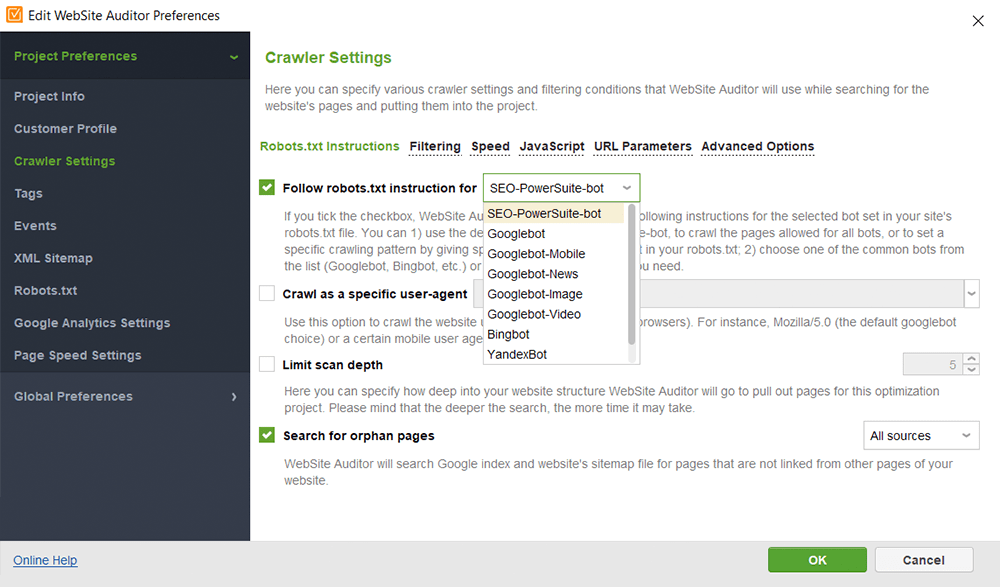
Dans WebSite Auditor, vous pouvez personnaliser l'analyse de votre site, en choisissant un robot de recherche différent et en spécifiant les paramètres d'analyse. Dans les Préférences du projet de l'araignée SEO, définissez le bot du moteur de recherche et un agent utilisateur spécifique. Choisissez les types de ressources que vous souhaitez examiner lors de l'analyse (ou inversement, ignorez l'analyse). Vous pouvez également demander au robot d'audit d'auditer les sous-domaines et les sites protégés par mot de passe, d'ignorer les paramètres d'URL spéciaux, etc.
Regardez cette vidéo détaillée pour savoir comment configurer votre projet et analyser les sites Web.
Chaque fois qu'un utilisateur ou un robot de recherche envoie une requête au serveur contenant les données du site Web, le fichier journal enregistre une entrée à ce sujet. Il s'agit des informations les plus correctes et les plus valides sur les robots d'exploration et les visiteurs de votre site, les erreurs d'indexation, les gaspillages de budget d'exploration, les redirections temporaires, etc. Comme il peut être difficile d'analyser manuellement les fichiers journaux, vous aurez besoin d'un programme d'analyse de fichiers journaux.
Quel que soit l'outil que vous décidez d'utiliser, le nombre de pages indexées doit être proche du nombre réel de pages sur votre site Web.
Et maintenant, passons à la façon dont vous pouvez contrôler l'exploration et l'indexation de votre site Web.
Par défaut, si vous n'avez pas de fichiers SEO techniques avec des contrôles d'exploration, les robots de recherche visiteront toujours votre site et l'exploreront tel quel. Cependant, les fichiers techniques vous permettent de contrôler la manière dont les robots des moteurs de recherche explorent et indexent vos pages. Ils sont donc fortement recommandés si votre site est volumineux. Voici quelques façons de modifier les règles d'indexation/d'exploration :
Alors, comment faire en sorte que Google indexe votre site plus rapidement en utilisant chacun d'eux ?
Un sitemap est un fichier SEO technique qui répertorie toutes les pages, vidéos et autres ressources de votre site, ainsi que les relations entre elles. Le fichier indique aux moteurs de recherche comment explorer votre site plus efficacement et joue un rôle crucial dans l'accessibilité de votre site Web.
Un site Web a besoin d'un sitemap lorsque :
Il existe différents types de plans de site que vous pouvez ajouter à votre site, en fonction principalement du type de site Web que vous gérez.
Un sitemap HTML est destiné aux lecteurs humains et se trouve au bas du site Web. Il a cependant peu de valeur SEO. Un sitemap HTML montre la navigation principale aux utilisateurs et reproduit généralement les liens dans les en-têtes de site. En attendant, les sitemaps HTML peuvent être utilisés pour améliorer l'accessibilité des pages qui ne sont pas incluses dans le menu principal.
Contrairement aux sitemaps HTML, les sitemaps XML sont lisibles par machine grâce à une syntaxe spéciale. Le sitemap XML se trouve dans le domaine racine, par exemple, https://www.link-assistant.com/sitemap.xml. Plus loin, nous discuterons des exigences et des balises de balisage pour créer un sitemap XML correct.
Il s'agit d'un autre type de sitemap disponible pour les robots des moteurs de recherche. Le plan du site TXT répertorie simplement toutes les URL des sites Web, sans fournir aucune autre information sur le contenu.
Ce type de sitemaps est utile pour les vastes bibliothèques d'images et les images de grande taille pour les aider à se classer dans Google Image Search. Dans Image Sitemap, vous pouvez fournir des informations supplémentaires sur l'image, telles que la géolocalisation, le titre et la licence. Vous pouvez répertorier jusqu'à 1 000 images pour chaque page.
Les sitemaps vidéo sont nécessaires pour le contenu vidéo hébergé sur vos pages afin de l'aider à mieux se classer dans la recherche de vidéos Google. Bien que Google recommande d'utiliser des données structurées pour les vidéos, un sitemap peut également être bénéfique, en particulier lorsque vous avez beaucoup de contenu vidéo sur une page. Dans le plan du site vidéo, vous pouvez ajouter des informations supplémentaires sur la vidéo, telles que les titres, la description, la durée, les vignettes et même si elle est adaptée aux familles pour la recherche sécurisée.
Pour les sites Web multilingues et multirégionaux, les moteurs de recherche disposent de plusieurs moyens pour déterminer la version linguistique à diffuser à un endroit donné. Les hreflangs sont l'une des nombreuses façons de servir des pages localisées, et vous pouvez utiliser un sitemap hreflang spécial pour cela. Le sitemap hreflang répertorie l'URL elle-même avec son élément enfant indiquant le code de langue/région de la page.
Si vous gérez un blog d'actualités, l'ajout d'un sitemap News-XML peut avoir un impact positif sur votre classement sur Google Actualités. Ici, vous ajoutez des informations sur le titre, la langue et la date de publication. Vous pouvez ajouter jusqu'à 1 000 URL dans le sitemap Google Actualités. Les URL ne doivent pas dater de plus de deux jours, après quoi vous pouvez les supprimer, mais elles resteront dans l'index pendant 30 jours.
Si votre site Web dispose d'un flux RSS, vous pouvez soumettre l'URL du flux sous forme de sitemap. La plupart des logiciels de blog sont capables de créer un flux, mais ces informations ne sont utiles que pour la découverte rapide des URL récentes.
De nos jours, les plus fréquemment utilisés sont les sitemaps XML, alors révisons brièvement les principales exigences pour la génération de sitemaps XML :
Le sitemap XML est encodé en UTF-8 et contient des balises obligatoires pour un élément XML :
Un exemple simple de plan de site XML à une entrée ressemblera à
Il existe des balises facultatives pour indiquer la priorité et la fréquence des explorations de pages - <priority>, <changefreq> (Google les ignore actuellement) et la valeur <lastmod> lorsqu'elle est exacte (par exemple, par rapport à la dernière modification sur une page) .
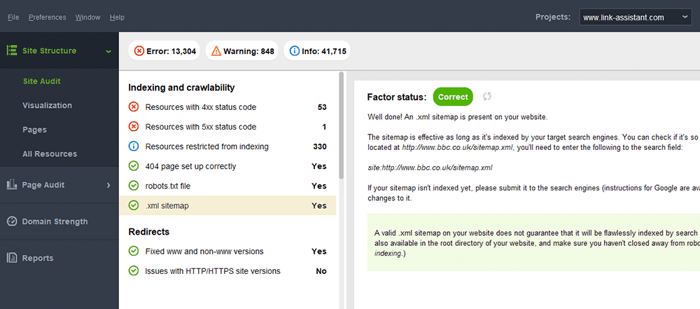
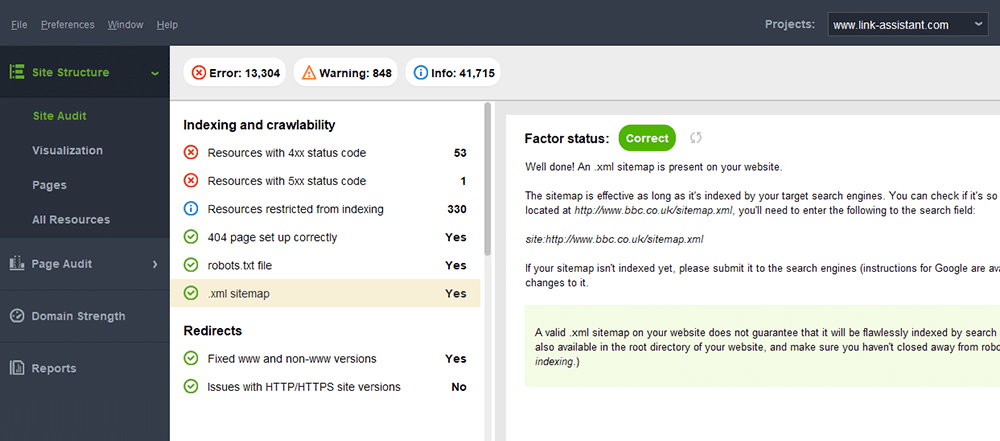
Une erreur typique avec les sitemaps est de ne pas avoir de sitemap XML valide sur un grand domaine. Vous pouvez vérifier la présence d'un sitemap sur le vôtre avec WebSite Auditor . Retrouvez les résultats dans la section Audit du site > Indexation et crawlabilité .
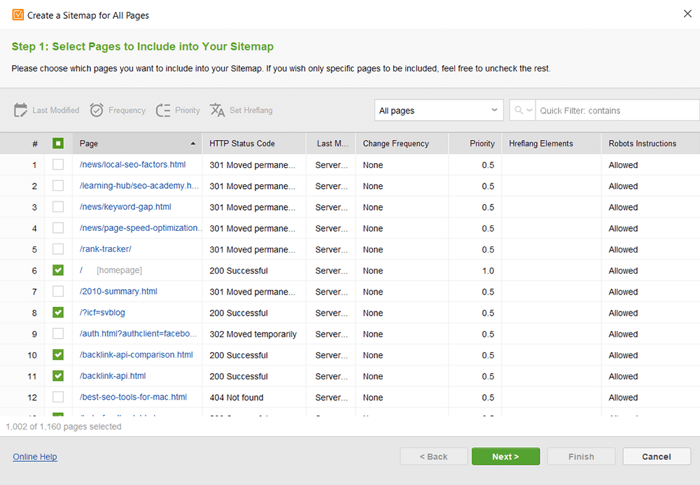
Si vous n'avez pas de sitemap, vous devriez vraiment en créer un dès maintenant. Vous pouvez générer rapidement le plan du site à l'aide des outils de site Web de WebSite Auditor lorsque vous passez à la section Pages .
Et informez Google de votre sitemap. Pour ce faire, vous pouvez
Le fait est que le fait d'avoir un sitemap sur votre site Web ne garantit pas que toutes vos pages seront indexées ou même explorées . Il existe d'autres ressources SEO techniques, visant à améliorer l'indexation du site. Nous les examinerons dans les prochaines étapes.
Un fichier robots.txt indique aux moteurs de recherche à quelles URL le robot peut accéder sur votre site. Ce fichier sert à éviter de surcharger votre serveur de requêtes, en gérant le trafic de crawl . Le fichier est généralement utilisé pour :
Robots.txt est placé à la racine du domaine et chaque sous-domaine doit avoir son propre fichier distinct. N'oubliez pas qu'il ne doit pas dépasser 500 Ko et qu'il doit répondre avec un code 200.
Le fichier robots.txt a également sa syntaxe avec les règles Autoriser et Disallow :
Différents moteurs de recherche peuvent suivre les directives différemment. Par exemple, Google a abandonné l'utilisation des directives noindex, crawl-delay et nofollow de robots.txt. En outre, il existe des robots d'exploration spéciaux tels que Googlebot-Image, Bingbot, Baiduspider-image, DuckDuckBot, AhrefsBot, etc. Ainsi, vous pouvez définir les règles pour tous les robots de recherche ou des règles distinctes pour seulement certains d'entre eux.
Écrire des instructions pour robots.txt peut devenir assez délicat, donc la règle ici est d'avoir moins d'instructions et plus de bon sens. Vous trouverez ci-dessous quelques exemples de définition des instructions robots.txt.
Accès complet au domaine. Dans ce cas, la règle d'interdiction n'est pas renseignée.
Blocage complet d'un hôte.
L'instruction interdit l'exploration de toutes les URL commençant par upload après le nom de domaine.
L'instruction interdit à Googlebot-News d'explorer tous les fichiers gif du dossier d'actualités.
Gardez à l'esprit que si vous définissez une instruction générale A pour tous les moteurs de recherche et une instruction étroite B pour un bot spécifique, alors le bot spécifique peut suivre l'instruction étroite et exécuter toutes les autres règles générales définies par défaut pour le bot, car il ne sera pas limité par la règle A. Par exemple, comme dans la règle ci-dessous :
Ici, AdsBot-Google-Mobile peut explorer des fichiers dans le dossier tmp malgré l'instruction avec la marque générique *.
L'une des utilisations typiques des fichiers robots.txt consiste à indiquer où se trouve le sitemap. Dans ce cas, vous n'avez pas besoin de mentionner les agents utilisateurs, car la règle s'applique à tous les robots. Le plan du site doit commencer par le S majuscule (rappelez-vous que le fichier robots.txt est sensible à la casse) et l'URL doit être absolue (c'est-à-dire qu'elle doit commencer par le nom de domaine complet).
Gardez à l'esprit que si vous définissez des instructions contradictoires, les robots d'exploration donneront la priorité à l'instruction la plus longue. Par exemple:
Ici, le script /admin/js/global.js sera toujours autorisé pour les crawlers malgré la première instruction. Tous les autres fichiers du dossier admin seront toujours interdits.
Vous pouvez vérifier la disponibilité du fichier robots.txt dans WebSite Auditor. Il vous permet également de générer le fichier à l'aide de l'outil de génération de robots.txt , puis de le sauvegarder ou de le télécharger directement sur le site Web via FTP.
Sachez que le fichier robots.txt est accessible au public et qu'il peut exposer certaines pages au lieu de les masquer. Si vous souhaitez masquer certains dossiers privés, protégez-les par mot de passe.
Enfin, le fichier robots.txt ne garantit pas que la page non autorisée ne sera pas explorée ou indexée . Empêcher Google d'explorer une page est susceptible de la supprimer de l'index de Google, cependant, le robot de recherche peut toujours explorer la page en suivant certains backlinks pointant vers elle. Voici donc un autre moyen d'empêcher une page d'explorer et d'indexer - les méta-robots.
Les balises Meta robots sont un excellent moyen d'indiquer aux crawlers comment traiter les pages individuelles. Les balises Meta robots sont ajoutées à la section <head> de votre page HTML, ainsi les instructions sont applicables à toute la page. Vous pouvez créer plusieurs instructions en combinant les directives de balises méta des robots avec des virgules ou en utilisant plusieurs balises méta. Cela peut ressembler à ceci :
Vous pouvez spécifier des balises meta robots pour différents robots, par exemple
Google comprend des balises telles que :
Les balises opposées index / follow / archive remplacent les directives d'interdiction correspondantes. Il existe d'autres balises indiquant comment la page peut apparaître dans les résultats de recherche, telles que snippet / nosnippet / notranslate / nopagereadaloud / noimageindex .
Si vous utilisez d'autres tags valables pour d'autres moteurs de recherche mais inconnus de Google, Googlebot les ignorera tout simplement.
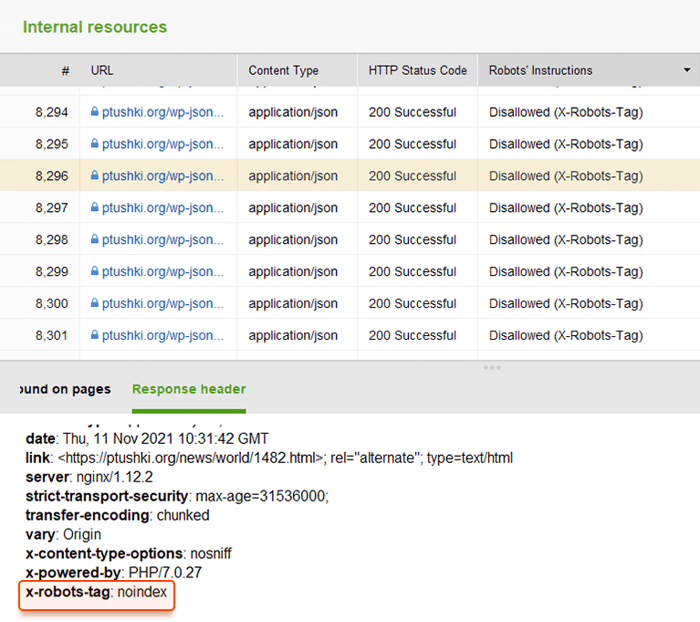
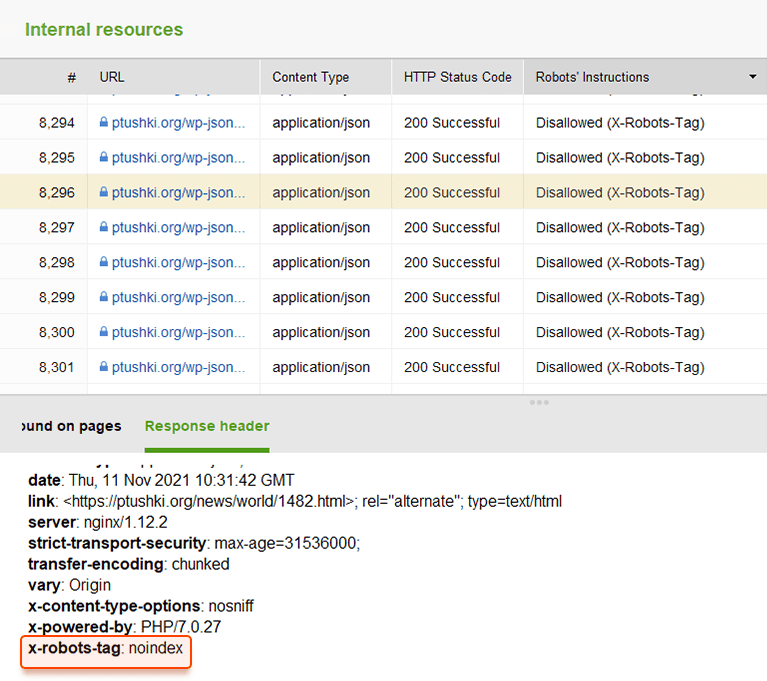
Au lieu de balises META, vous pouvez utiliser un en-tête de réponse pour les ressources non HTML , telles que les fichiers PDF, vidéo et image. Défini pour renvoyer un en-tête X-Robots-Tag avec une valeur de noindex ou none dans votre réponse.
Vous pouvez également utiliser une combinaison de directives pour définir à quoi ressemblera l'extrait de code dans les résultats de recherche, par exemple, max-image-preview: [setting] ou nosnippet ou max-snippet: [number] , etc.
Vous pouvez ajouter le X-Robots-Tag aux réponses HTTP d'un site Web via les fichiers de configuration du logiciel de serveur Web de votre site. Vos directives d'exploration peuvent être appliquées globalement sur l'ensemble du site pour tous les fichiers, ainsi que pour des fichiers individuels si vous définissez leurs noms exacts.
Vous pouvez consulter rapidement toutes les instructions des robots avec WebSite Auditor . Accédez à Structure du site > Toutes les ressources > Ressources internes et vérifiez la colonne Instructions des robots . Vous trouverez ici les pages interdites et la méthode appliquée, robots.txt, balises méta ou balise X-Robots.
Le serveur hébergeant un site génère un code d'état HTTP lorsqu'il répond à une requête faite par un client, un navigateur ou un robot d'exploration. Si le serveur répond avec un code d'état 2xx, le contenu reçu peut être pris en compte pour l'indexation. D'autres réponses de 3xx à 5xx indiquent qu'il y a un problème avec le rendu du contenu. Voici quelques significations des réponses de code d'état HTTP :
Les redirections 301 sont utilisées lorsque :
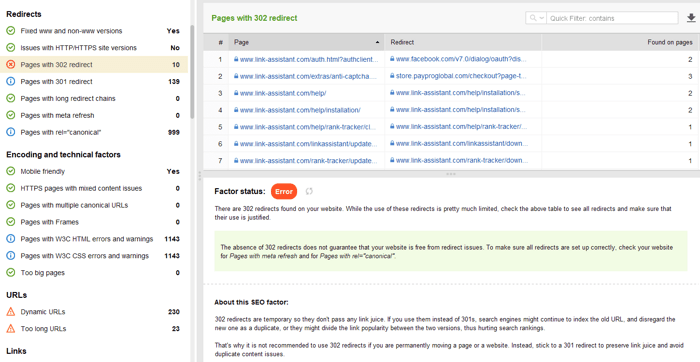
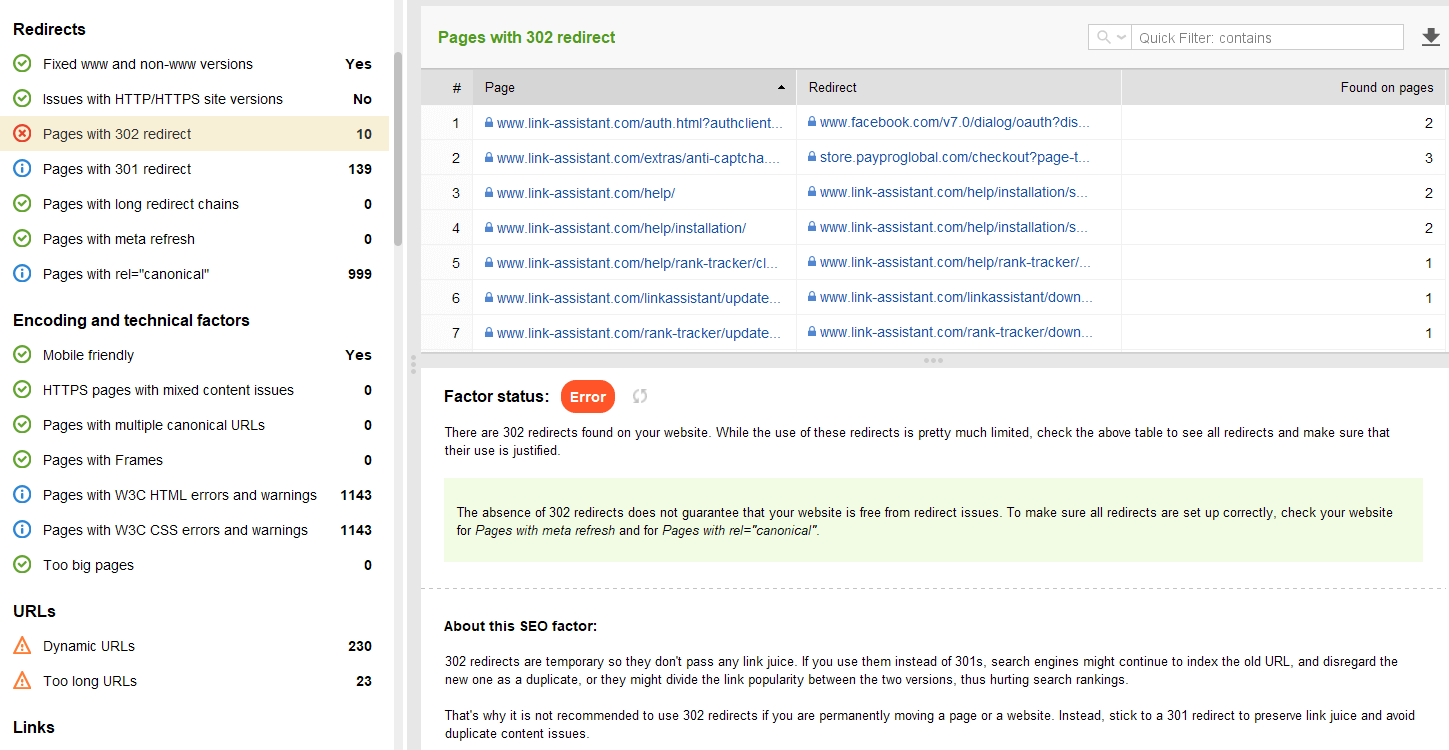
302 redirection temporaire
La redirection 302 temporaire ne doit être utilisée que sur les pages temporaires. Par exemple, lorsque vous reconcevez une page ou testez une nouvelle page et recueillez des commentaires, mais que vous ne voulez pas que l'URL sorte des classements.
304 pour vérifier le cache
Le code de réponse 304 est pris en charge dans tous les moteurs de recherche les plus populaires, comme Google, Bing, Baidu, Yandex, etc. La configuration correcte du code de réponse 304 aide le bot à comprendre ce qui a changé sur la page depuis sa dernière exploration. Le bot envoie une requête HTTP If-Modified-Since. Si aucun changement n'est détecté depuis la dernière date d'exploration, le robot de recherche n'a pas besoin d'explorer à nouveau la page. Pour un utilisateur, cela signifie que la page ne sera pas entièrement rechargée et que son contenu sera extrait du cache du navigateur.
Le code 304 permet également de :
Il est important de vérifier la mise en cache non seulement du contenu de la page, mais aussi des fichiers statiques, comme les images ou les styles CSS. Il existe des outils spéciaux, comme celui-ci , pour vérifier le code de réponse 304.


Le plus souvent, les problèmes de code de réponse du serveur apparaissent lorsque les robots d'exploration continuent de suivre les liens internes et externes vers les pages supprimées ou déplacées, obtenant des réponses 3xx et 4xx.
Une erreur 404 indique qu'une page n'est pas disponible et le serveur envoie le code d'état HTTP correct au navigateur — un 404 Not Found.
Cependant, il y a des erreurs logicielles 404 lorsque le serveur envoie le code de réponse 200 OK, mais Google considère qu'il devrait s'agir de 404. Cela peut se produire parce que :
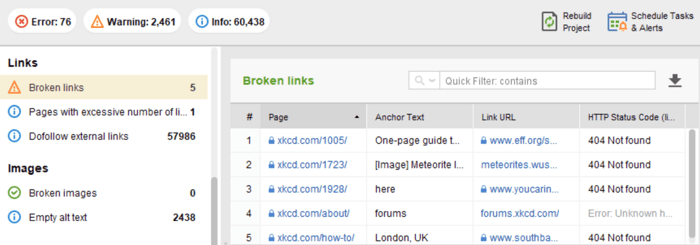
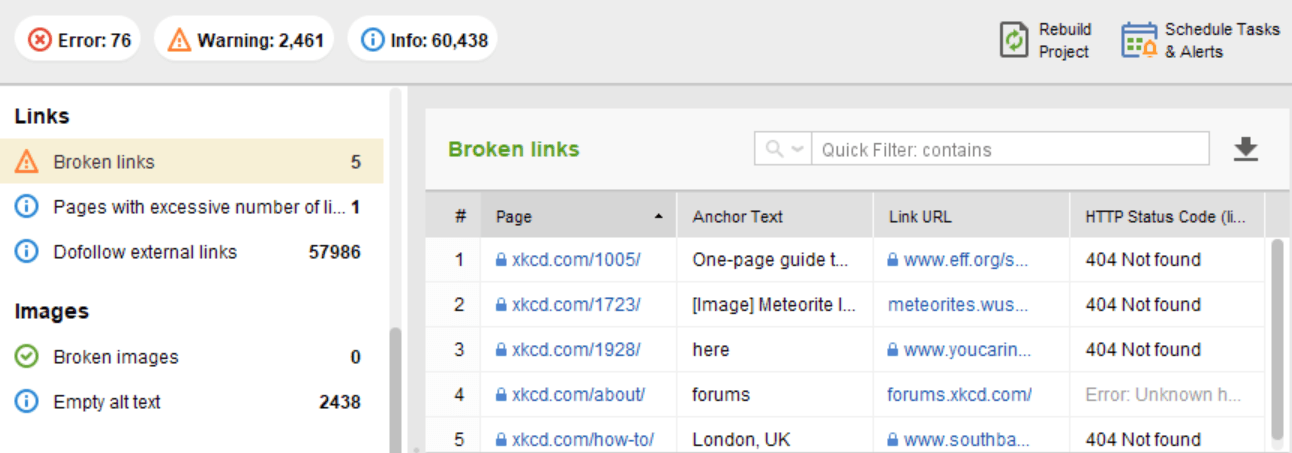
Dans le module Audit de site de WebSite Auditor, passez en revue les ressources avec le code de réponse 4xx, 5xx sous l'onglet Indexation et capacité d'exploration , et une section distincte pour les liens rompus dans l'onglet Liens .
Quelques autres problèmes de redirection courants impliquant des réponses 301/302 :
Vous pouvez examiner toutes les pages avec des redirections 301 et 302 dans la section Audit du site > Redirections de WebSite Auditor.
La duplication peut devenir un problème grave pour l'exploration de sites Web. Si Google trouve des URL en double , il décidera laquelle d'entre elles est une page principale et l'explorera plus fréquemment, tandis que les doublons seront explorés moins souvent et pourront même disparaître de l'index de recherche. Une solution infaillible consiste à indiquer une des pages dupliquées comme canonique, la principale. Cela peut être fait à l'aide de l'attribut rel="canonical" , placé dans le code HTML des pages ou dans les réponses d'en-tête HTTP d'un site.
Google utilise des pages canoniques pour évaluer votre contenu et sa qualité, et le plus souvent, les résultats de recherche renvoient vers des pages canoniques, à moins que les moteurs de recherche n'identifient distinctement qu'une page non canonique convient mieux à l'utilisateur (par exemple, il s'agit d'un utilisateur mobile ou un chercheur dans un endroit précis).
Ainsi, la canonisation des pages pertinentes permet de :
Les problèmes de duplication signifient qu'un contenu identique ou similaire apparaît sur plusieurs URL. Assez souvent, les doublons apparaissent automatiquement en raison du traitement des données techniques sur un site Web.
Certains CMS peuvent générer automatiquement des problèmes de doublons en raison de paramètres incorrects. Par exemple, plusieurs URL peuvent être générées dans divers répertoires de sites Web, et ce sont des doublons :
La pagination peut également entraîner des problèmes de duplication si elle est mal implémentée. Par exemple, l'URL de la page de catégorie et la page 1 affichent le même contenu et sont donc traitées comme des doublons. Une telle combinaison ne devrait pas exister, ou la page de catégorie devrait être marquée comme canonique.
Les résultats de tri et de filtrage peuvent être représentés comme des doublons. Cela se produit lorsque votre site crée des URL dynamiques pour les requêtes de recherche ou de filtrage. Vous obtiendrez des paramètres d'URL qui représentent des alias de chaînes de requête ou des variables d'URL, ce sont la partie d'une URL qui suit un point d'interrogation.
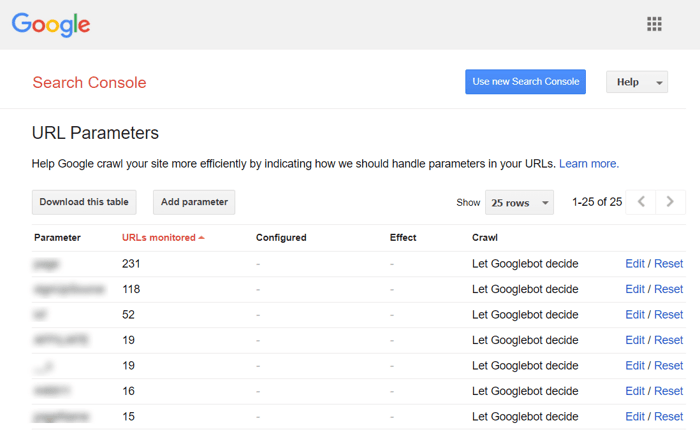
Pour empêcher Google d'explorer un tas de pages presque identiques, configurez pour ignorer certains paramètres d'URL. Pour ce faire, lancez Google Search Console et accédez à Outils et rapports hérités > Paramètres d'URL . Cliquez sur Modifier à droite et indiquez à Google les paramètres à ignorer — la règle s'appliquera à l'ensemble du site. N'oubliez pas que l' outil de paramétrage est destiné aux utilisateurs avancés, il doit donc être manipulé avec précision.
Le problème de duplication se produit souvent sur les sites Web de commerce électronique qui permettent une navigation par filtre à facettes , réduisant la recherche à trois, quatre critères et plus. Voici un exemple de configuration de règles d'exploration pour un site de commerce électronique : stocker les URL avec des résultats de recherche plus longs et plus étroits dans un dossier spécifique et les interdire par une règle robots.txt.
Des problèmes logiques dans la structure du site Web peuvent entraîner une duplication. Cela peut être le cas lorsque vous vendez des produits et qu'un produit appartient à différentes catégories.
Dans ce cas, les produits doivent être accessibles via une seule URL. Les URL sont considérées comme des doublons complets et nuiront au référencement. L'URL doit être attribuée via les paramètres corrects du CMS, générant une URL unique unique pour une page.
La duplication partielle se produit souvent avec WordPress CMS, par exemple, lorsque des balises sont utilisées. Alors que les balises améliorent la recherche sur le site et la navigation des utilisateurs, les sites Web WP génèrent des pages de balises qui peuvent coïncider avec les noms de catégorie et représenter un contenu similaire à partir de l'aperçu de l'extrait d'article. La solution consiste à utiliser les balises à bon escient, en n'en ajoutant qu'un nombre limité. Ou vous pouvez ajouter un meta robots noindex dofollow sur les pages de balises.
Si vous choisissez de diffuser une version mobile distincte de votre site Web et, en particulier, de générer des pages AMP pour la recherche mobile, vous pouvez avoir des doublons de ce type.
Pour indiquer qu'une page est un doublon, vous pouvez utiliser une balise <link> dans la section d'en-tête de votre code HTML. Pour les versions mobiles, ce sera la balise de lien avec la valeur rel="alternate", comme ceci :
Il en va de même pour les pages AMP, (qui ne sont pas à la mode, mais peuvent tout de même être utilisées pour afficher des résultats mobiles.), Consultez notre guide sur la mise en œuvre des pages AMP .
Il existe différentes manières de présenter un contenu localisé . Lorsque vous présentez du contenu dans différentes variantes linguistiques/locales et que vous n'avez traduit que l'en-tête/le pied de page/la navigation du site, mais que le contenu reste dans la même langue, les URL seront traitées comme des doublons.
Configurez l'affichage de sites multilingues et multirégionaux à l'aide de balises hreflang , en ajoutant les codes de langue/région pris en charge dans les codes de réponse HTML, HTTP ou dans le plan du site.
Les sites Web sont généralement disponibles avec et sans "www" dans le nom de domaine. Ce problème est assez courant et les utilisateurs renvoient à la fois aux versions www et non www. La résolution de ce problème vous aidera à empêcher les moteurs de recherche d'indexer deux versions d'un site Web. Bien qu'une telle indexation n'entraîne pas de pénalité, définir une version comme priorité est une bonne pratique.

Google préfère HTTPS à HTTP, car le cryptage sécurisé est fortement recommandé pour la plupart des sites Web (en particulier lors des transactions et de la collecte d'informations sensibles sur les utilisateurs). Parfois, les webmasters sont confrontés à des problèmes techniques lors de l'installation de certificats SSL et de la configuration des versions HTTP/HTTPS du site Web. Si un site a un certificat SSL invalide (non fiable ou expiré), la plupart des navigateurs Web empêcheront les utilisateurs de visiter votre site en les informant d'une "connexion non sécurisée".
Si les versions HTTP et HTTPS de votre site Web ne sont pas correctement définies, les deux peuvent être indexées par les moteurs de recherche et causer des problèmes de contenu en double qui peuvent nuire au classement de votre site Web.
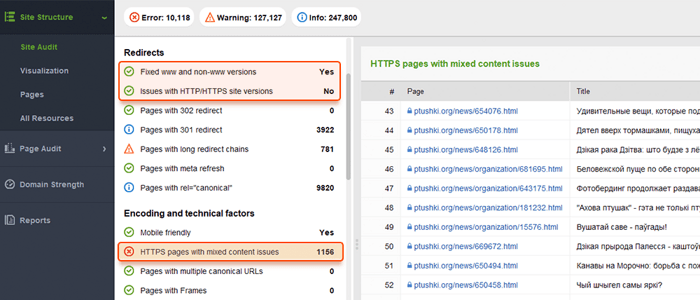
Si votre site utilise déjà HTTPS (partiellement ou entièrement), il est important d'éliminer les problèmes HTTPS courants dans le cadre de l'audit de votre site SEO. Pensez notamment à vérifier les contenus mixtes dans la rubrique Audit du site > Encodage et facteurs techniques .
Des problèmes de contenu mixte surviennent lorsqu'une page autrement sécurisée charge une partie de son contenu (images, vidéos, scripts, fichiers CSS) via une connexion HTTP non sécurisée. Cela affaiblit la sécurité et peut empêcher les navigateurs de charger le contenu non sécurisé ou même la page entière.
Pour éviter ces problèmes, vous pouvez configurer et afficher la version primaire www ou non www de votre site dans le fichier .htaccess . Définissez également le domaine préféré dans Google Search Console et indiquez que les pages HTTPS sont canoniques.
Une fois que vous contrôlez totalement le contenu de votre propre site Web, assurez - vous qu'il n'y a pas de doublons de titres, Website Auditor en -têtes, de descriptions, d'images, etc. tableau de bord. Les pages avec des titres en double et des balises de description méta sont susceptibles d'avoir également un contenu presque identique.
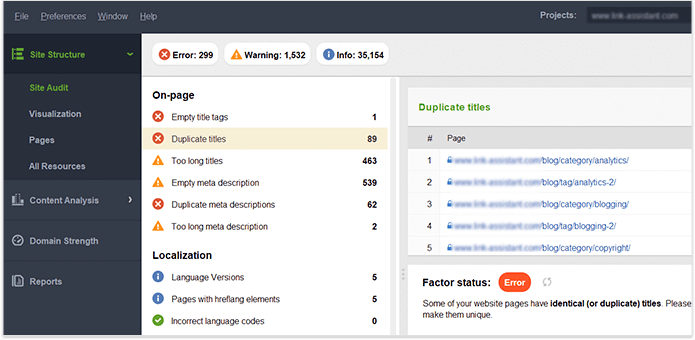
Résumons comment nous découvrons et corrigeons les problèmes d'indexation. Si vous avez suivi tous les conseils ci-dessus, mais que certaines de vos pages ne figurent toujours pas dans l'index, voici un récapitulatif des raisons pour lesquelles cela a pu se produire :
Pourquoi une page est indexée alors qu'elle ne devrait pas l'être ?
N'oubliez pas que le blocage d'une page dans le fichier robots.txt et sa suppression du sitemap ne garantissent pas qu'elle ne sera pas indexée. Vous pouvez consulter notre guide détaillé sur la façon d'empêcher l'indexation correcte des pages .
Une architecture de site peu profonde et logique est importante pour les utilisateurs et les robots des moteurs de recherche. Une structure de site bien planifiée joue également un grand rôle dans son classement car :
Lors de l'examen de la structure et des liens internes de vos sites, faites attention aux éléments suivants.
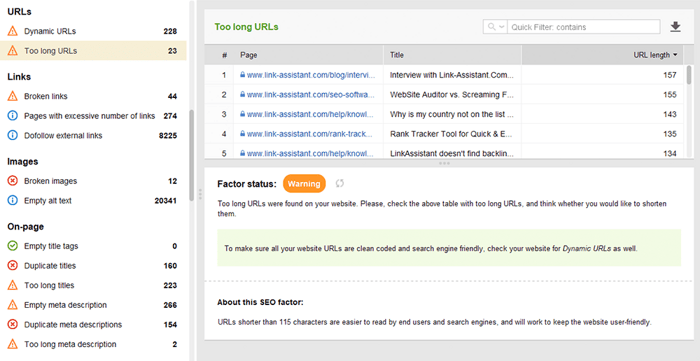
Les URL optimisées sont cruciales pour deux raisons. Premièrement, c'est un facteur de classement mineur pour Google. Deuxièmement, les utilisateurs peuvent être déconcertés par des URL trop longues ou maladroites. En pensant à la structure de votre URL, respectez les bonnes pratiques suivantes :
Vous pouvez vérifier vos URL dans la section Audit de site > URL de WebSite Auditor.
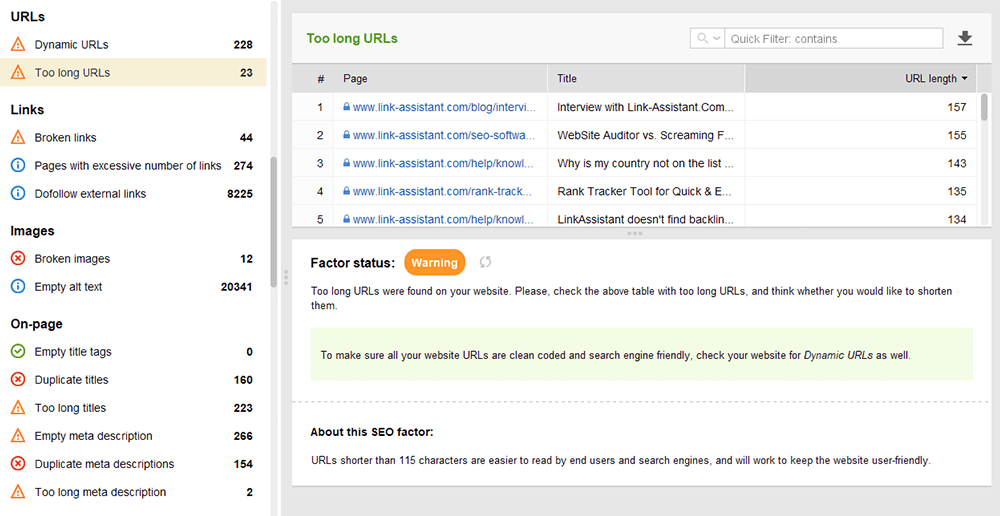
Il existe de nombreux types de liens, certains d'entre eux sont plus ou moins bénéfiques pour le référencement de votre site Web. Par exemple, les liens contextuels dofollow transmettent le jus de lien et servent d'indicateur supplémentaire aux moteurs de recherche sur le sujet du lien. Les liens sont considérés comme étant de haute qualité lorsque (et cela concerne à la fois les liens internes et externes) :
Les liens de navigation dans les en-têtes et les barres latérales sont également importants pour le référencement du site Web, car ils aident les utilisateurs et les moteurs de recherche à naviguer dans les pages.
D'autres liens peuvent n'avoir aucune valeur de classement ou même nuire à une autorité de site. Par exemple, des liens sortants massifs sur tout le site dans les modèles (que les modèles WP gratuits avaient beaucoup). Ce guide sur les types de liens dans le référencement explique comment créer des liens précieux de la bonne manière.
Vous pouvez utiliser l'outil WebSite Auditor pour examiner en profondeur les liens internes et leur qualité.
Les pages orphelines sont des pages non liées qui passent inaperçues et peuvent finalement disparaître de l'index de recherche. Pour rechercher des pages orphelines, accédez à Audit du site > Visualisation et examinez le plan du site visuel . Ici, vous verrez facilement toutes les pages non liées et les longues chaînes de redirection (les redirections 301 et 302 sont marquées en bleu).
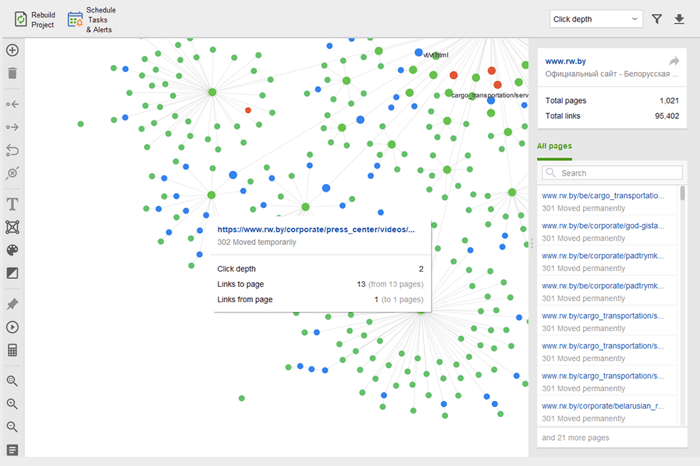
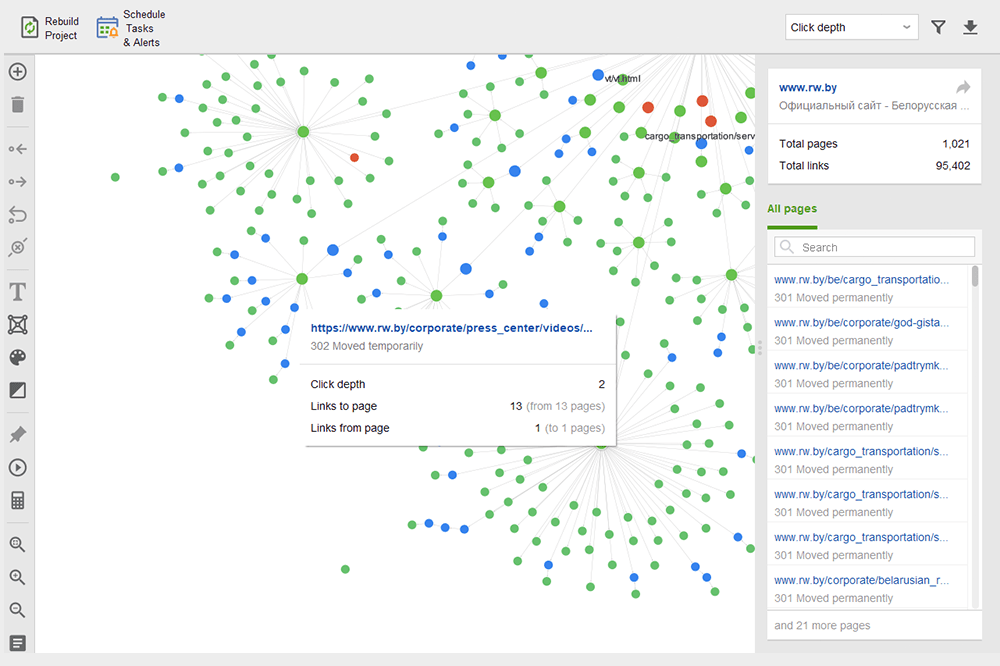
Vous pouvez avoir un aperçu de l'ensemble de la structure du site, examiner le poids de ses pages principales - en vérifiant les pages vues (intégrées à partir de Google Analytics), le PageRank et le jus de lien qu'ils obtiennent des liens entrants et sortants. Vous pouvez ajouter et supprimer des liens et reconstruire le projet, en recalculant la proéminence de chaque page.
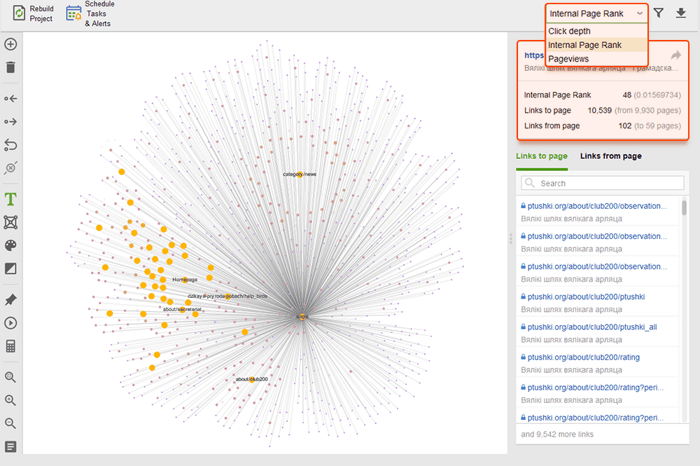
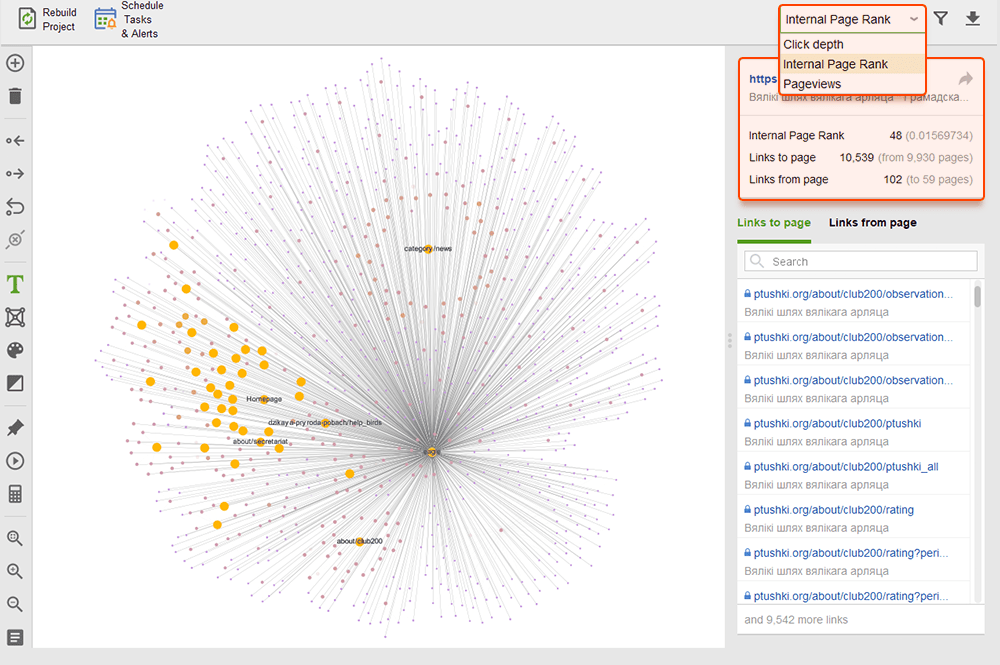
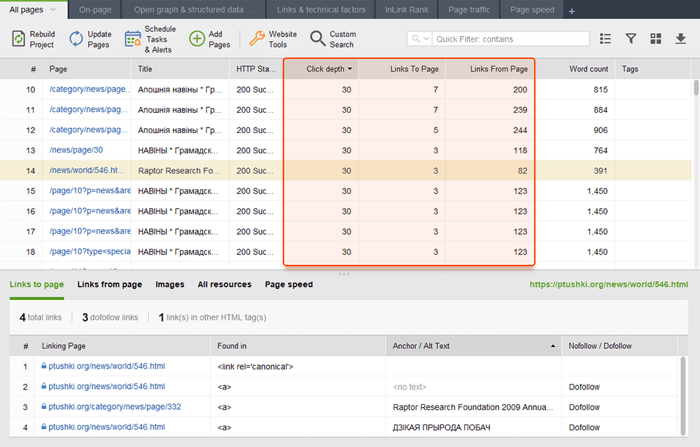
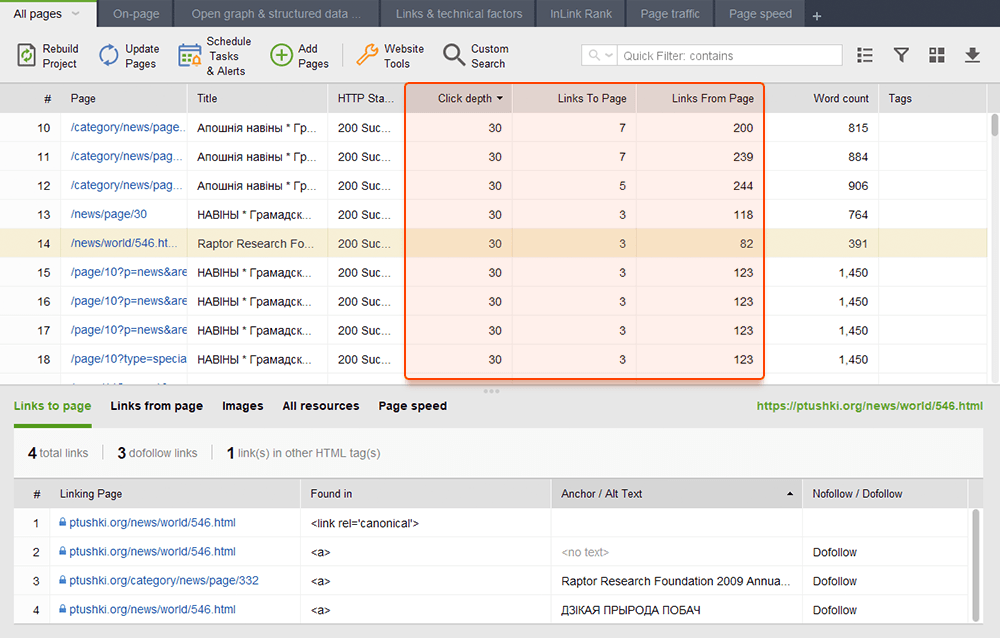
Lorsque vous auditez vos liens internes, vérifiez la profondeur des clics. Assurez-vous que les pages importantes de votre site ne sont pas à plus de trois clics de la page d'accueil. Un autre endroit pour examiner la profondeur des clics dans WebSite Auditor consiste à accéder à Structure du site > Pages . Triez ensuite les URL par profondeur de clic dans l'ordre décroissant en cliquant deux fois sur l'en-tête de la colonne.
La pagination des pages de blog est nécessaire pour la découvrabilité par les moteurs de recherche, bien qu'elle augmente la profondeur des clics. Utilisez une structure simple avec une recherche de site exploitable pour permettre aux utilisateurs de trouver plus facilement n'importe quelle ressource.
Pour plus de détails, veuillez consulter notre guide détaillé sur la pagination optimisée pour le référencement .
Le fil d'Ariane est un type de balisage qui permet de créer des résultats de recherche riches, en affichant le chemin d'accès à la page dans la structure de votre site. Les fils d'Ariane apparaissent grâce à un bon maillage, avec des ancres optimisées sur les liens internes, et des données structurées correctement implémentées (nous nous attarderons sur ces dernières quelques paragraphes plus bas).

En fait, les liens internes peuvent affecter le classement de votre site et la façon dont chaque page est présentée dans la recherche. Pour en savoir plus, consultez notre guide SEO des stratégies de liens internes .
La vitesse du site et l'expérience de la page ont un impact direct sur les positions organiques. La réponse du serveur peut devenir un problème pour les performances du site lorsque trop d'utilisateurs le visitent à la fois. En ce qui concerne la vitesse de la page, Google s'attend à ce que le contenu de la plus grande page se charge dans la fenêtre d'affichage en 2,5 secondes ou moins, et récompense éventuellement les pages offrant de meilleurs résultats. C'est pourquoi la vitesse doit être testée et améliorée à la fois côté serveur et côté client.
Les tests de vitesse de chargement découvrent des problèmes côté serveur lorsque trop d'utilisateurs visitent un site Web simultanément. Bien que le problème soit lié aux paramètres du serveur, les référenceurs doivent en tenir compte avant de planifier des campagnes de référencement et de publicité à grande échelle. Testez la capacité maximale de chargement de votre serveur si vous vous attendez à une augmentation du nombre de visiteurs. Faites attention à la corrélation entre l'augmentation du nombre de visiteurs et le temps de réponse du serveur. Il existe des outils de test de charge qui vous permettent de simuler de nombreuses visites distribuées et de tester la capacité de votre serveur.
Côté serveur, l'une des métriques les plus importantes est la mesure TTFB , ou time to first byte . TTFB mesure la durée entre l'utilisateur effectuant une requête HTTP et le premier octet de la page reçu par le navigateur du client. Le temps de réponse du serveur affecte les performances de vos pages Web. L'audit TTFB échoue si le navigateur attend plus de 600 ms pour que le serveur réponde. Notez que le moyen le plus simple d'améliorer le TTFB est de passer de l'hébergement mutualisé à l'hébergement géré , car dans ce cas, vous aurez un serveur dédié pour votre site uniquement.
Par exemple, voici un test de page réalisé avec Geekflare — un outil gratuit pour vérifier les performances du site . Comme vous pouvez le constater, l'outil montre que le TTFB pour cette page dépasse 600 ms et doit donc être amélioré.

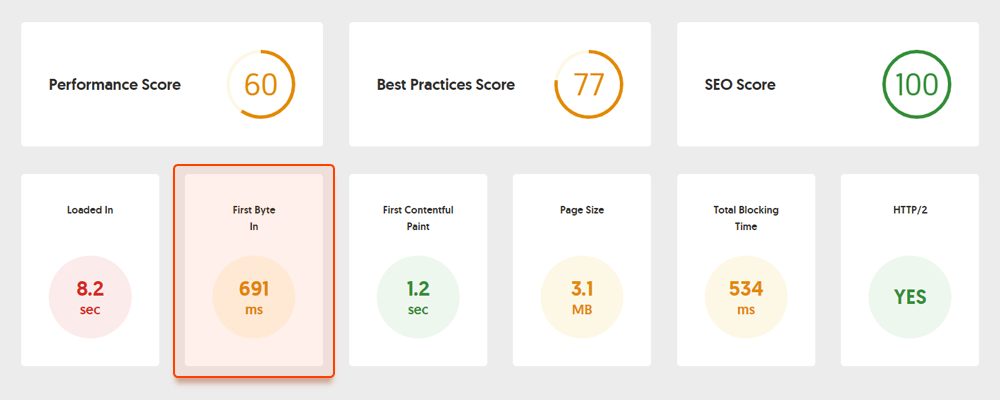
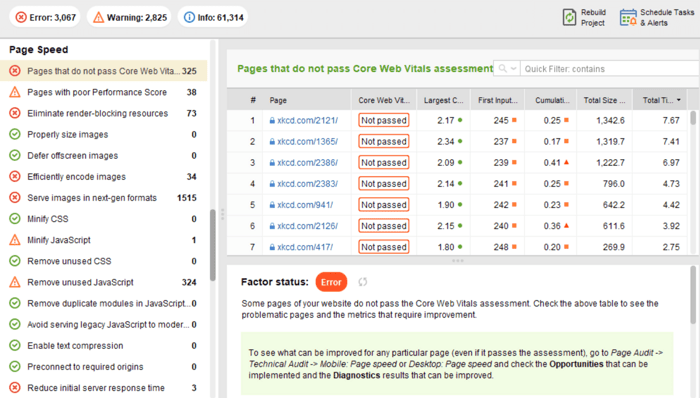
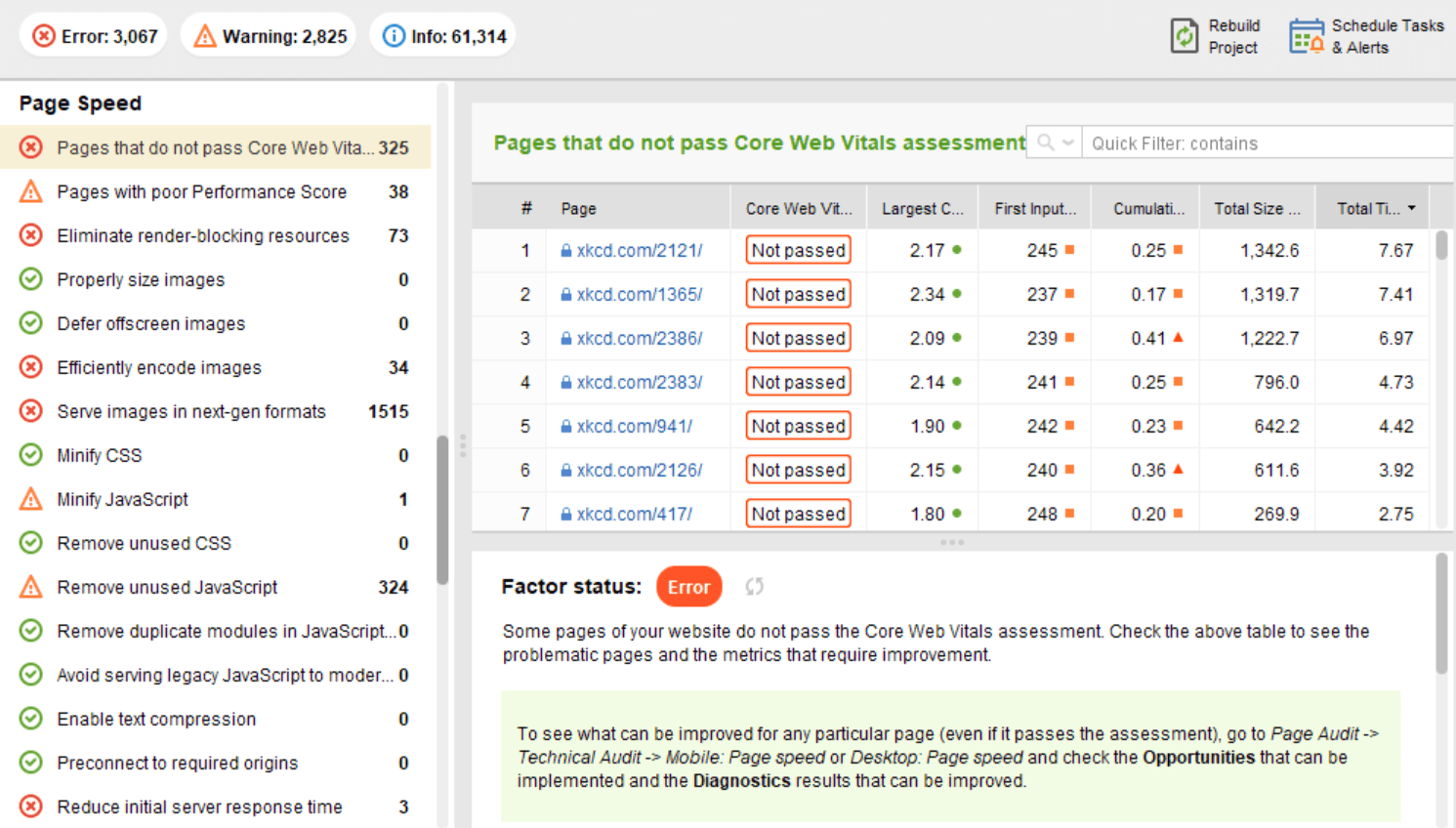
Du côté client, la vitesse de la page n'est pas une chose facile à mesurer, cependant, et Google a longtemps lutté avec cette métrique. Enfin, il est arrivé à Core Web Vitals - trois mesures conçues pour mesurer la vitesse perçue d'une page donnée. Ces métriques sont le LCP (Largest Contentful Pain), le First Input Delay (FID) et le Cumulative Layout Shift (CLS). Ils montrent les performances d'un site Web en termes de vitesse de chargement, d'interactivité et de stabilité visuelle de ses pages Web. Si vous avez besoin de plus de détails sur chaque métrique CWV, consultez notre guide sur Core Web Vitals .
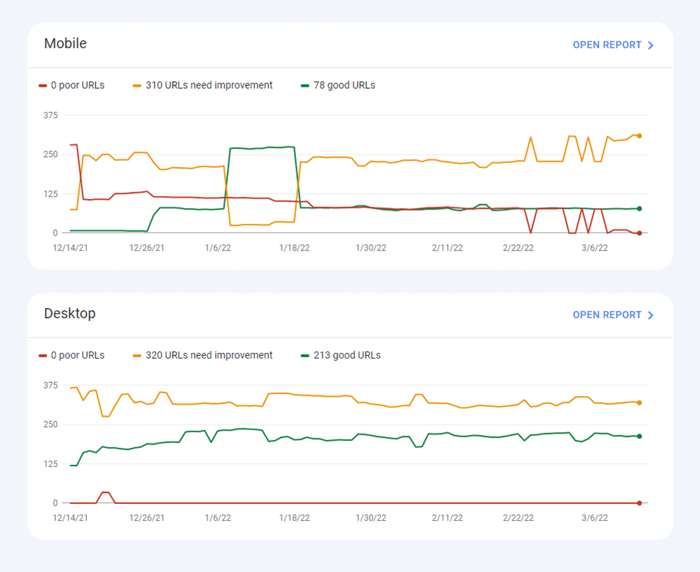
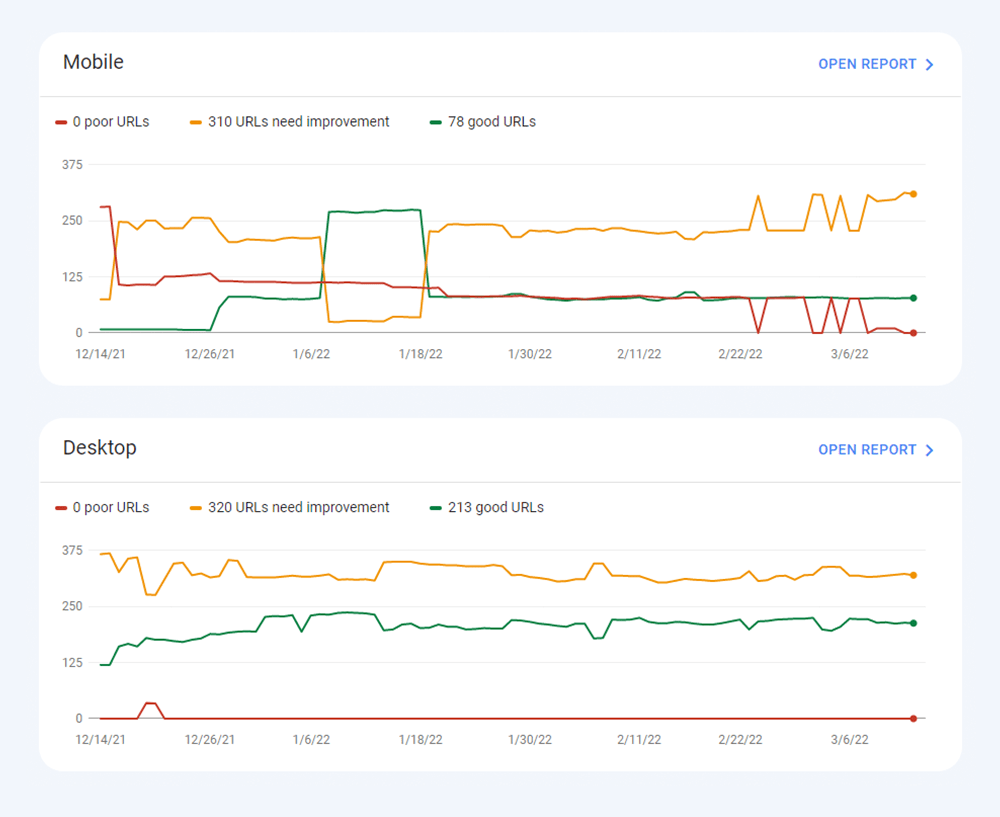
Récemment, les trois métriques Core Web Vitals ont été ajoutées à WebSite Auditor . Ainsi, si vous utilisez cet outil, vous pouvez voir chaque score de métrique, une liste des problèmes de vitesse de page sur votre site Web et une liste des pages ou des ressources affectées. Les données sont analysées via la clé API PageSpeed qui peut être générée gratuitement.
L'avantage d'utiliser WebSite Auditor pour auditer CWV est que vous effectuez une vérification en bloc pour toutes les pages à la fois. Si vous voyez de nombreuses pages affectées par le même problème, il est probable que le problème concerne tout le site et puisse être résolu avec un seul correctif. Ce n'est donc pas autant de travail qu'il n'y paraît. Tout ce que vous avez à faire est de suivre les recommandations sur la droite, et la vitesse de votre page augmentera en un rien de temps.
De nos jours, le nombre de chercheurs mobiles dépasse celui des ordinateurs de bureau. En 2019, Google a mis en place l'indexation mobile d'abord , l'agent de smartphone explorant les sites Web avant le bureau de Googlebot. Ainsi, la convivialité mobile revêt une importance primordiale pour les classements organiques.
Remarquablement, il existe différentes approches pour créer des sites Web adaptés aux mobiles :
Les avantages et les inconvénients de chaque solution sont expliqués dans notre guide détaillé sur la façon de rendre votre site Web adapté aux mobiles . De plus, vous pouvez rafraîchir les pages AMP - bien que ce ne soit pas une technologie de pointe, cela fonctionne toujours bien pour certains types de pages, par exemple pour les actualités.
La convivialité mobile reste un facteur essentiel pour les sites Web servant une URL pour les ordinateurs de bureau et les mobiles. En outre, certains signaux d'utilisabilité, tels que l'absence d'interstitiels intrusifs, restent un facteur pertinent pour les classements sur ordinateur et sur mobile. C'est pourquoi les développeurs Web doivent garantir la meilleure expérience utilisateur sur tous les types d'appareils.
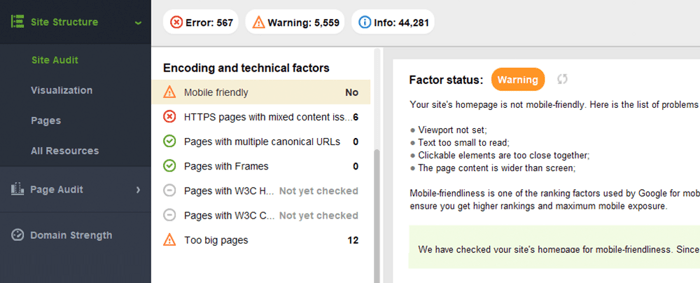
Le test adapté aux mobiles de Google comprend une sélection de critères d'utilisabilité, tels que la configuration de la fenêtre d'affichage, l'utilisation de plug-ins et la taille du texte et des éléments cliquables. Il est également important de se rappeler que la compatibilité mobile est évaluée sur une base de page, vous devez donc vérifier chacune de vos pages de destination pour la compatibilité mobile séparément, une à la fois.
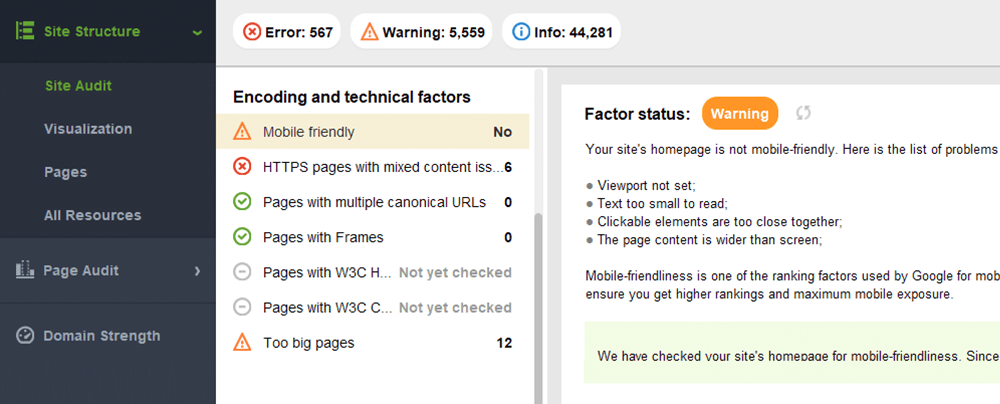
Pour évaluer l'ensemble de votre site Web, passez à Google Search Console. Accédez à l'onglet Expérience et cliquez sur le rapport d'utilisabilité mobile pour afficher les statistiques de toutes vos pages. Sous le graphique, vous pouvez voir un tableau avec les problèmes les plus courants affectant vos pages mobiles. En cliquant sur n'importe quel problème sous le tableau de bord, vous obtiendrez une liste de toutes les URL concernées.
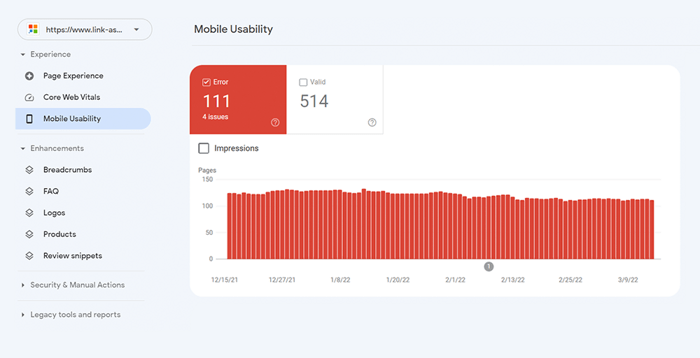

Les problèmes typiques de convivialité mobile sont :
WebSite Auditor examine également la compatibilité mobile de la page d'accueil et signale les problèmes d'expérience utilisateur mobile. Accédez à Audit du site > Codage et facteurs techniques . L'outil indiquera si le site est adapté aux mobiles et répertoriera les problèmes, le cas échéant :
Les signaux sur la page sont des facteurs de classement directs et, quelle que soit la qualité technique de votre site Web, vos pages n'apparaîtront jamais dans la recherche sans une optimisation appropriée des balises HTML . Votre objectif est donc de vérifier et de ranger les titres, les méta-descriptions et les en-têtes H1 à H3 de votre contenu sur votre site Web.
Le titre et la méta description sont utilisés par les moteurs de recherche pour former un extrait de résultat de recherche. Cet extrait est ce que les utilisateurs verront en premier, il affecte donc considérablement le taux de clics organiques .
Les titres, ainsi que les paragraphes, les listes à puces et d'autres éléments de structure de page Web, aident à créer des résultats de recherche riches dans Google. De plus, ils améliorent naturellement la lisibilité et l'interaction de l'utilisateur avec la page, ce qui peut servir de signal positif aux moteurs de recherche. Garder un œil sur:
Dupliquez les titres, les en-têtes et les descriptions sur tout le site — corrigez-les en écrivant des titres uniques pour chaque page.
Optimisation des titres, des en-têtes et des descriptions pour les moteurs de recherche (c'est-à-dire la longueur, les mots-clés, etc.)
Contenu mince - les pages avec peu de contenu ne seront presque jamais classées et peuvent même gâcher l'autorité du site (à cause de l'algorithme Panda), alors assurez-vous que vos pages couvrent le sujet en profondeur.
Optimisation des images et des fichiers multimédias — utilisez des formats optimisés pour le référencement, appliquez le lazy-loading, redimensionnez les fichiers pour les rendre plus légers, etc. Pour plus de détails, lisez notre guide sur l'optimisation des images .
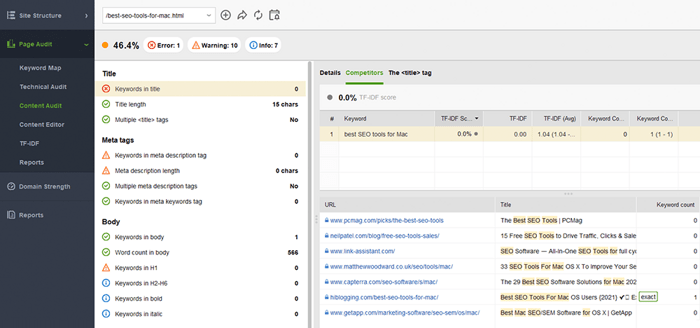
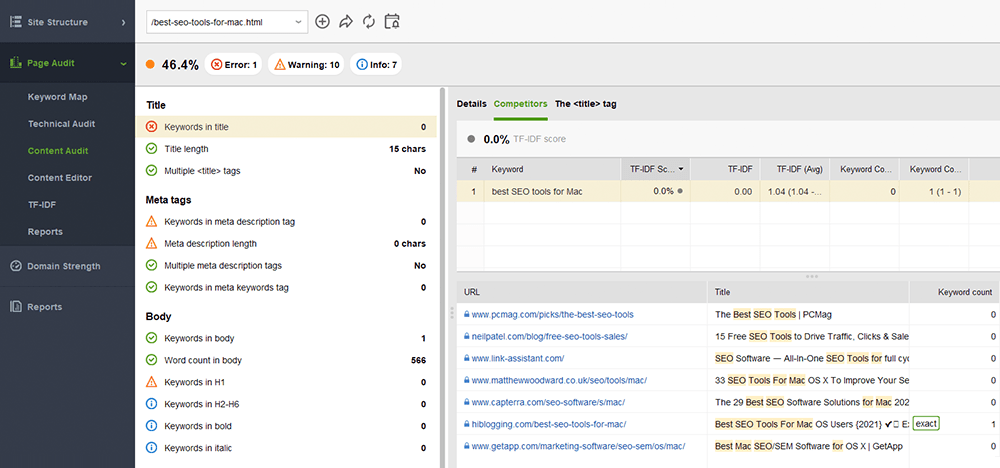
WebSite Auditor peut vous aider beaucoup dans cette tâche. La section Structure du site > Audit du site vous permet de vérifier en bloc les problèmes de balises méta sur le site Web. Si vous avez besoin d'auditer le contenu d'une page individuelle plus en détail, accédez à la section Audit de page . L'application dispose également d'un outil d'écriture intégré Content Editor qui vous propose des suggestions sur la façon de réécrire des pages en fonction de vos principaux concurrents SERP. Vous pouvez modifier les pages en déplacement ou télécharger les recommandations en tant que tâche pour les rédacteurs.
Pour plus d'informations, lisez notre guide d'optimisation SEO sur la page .
Les données structurées sont un balisage sémantique qui permet aux robots de recherche de mieux comprendre le contenu d'une page. Par exemple, si votre page contient une recette de tarte aux pommes, vous pouvez utiliser des données structurées pour indiquer à Google quel texte correspond aux ingrédients, quel est le temps de cuisson, le nombre de calories, etc. Google utilise le balisage pour créer des extraits enrichis pour vos pages dans les SERP.
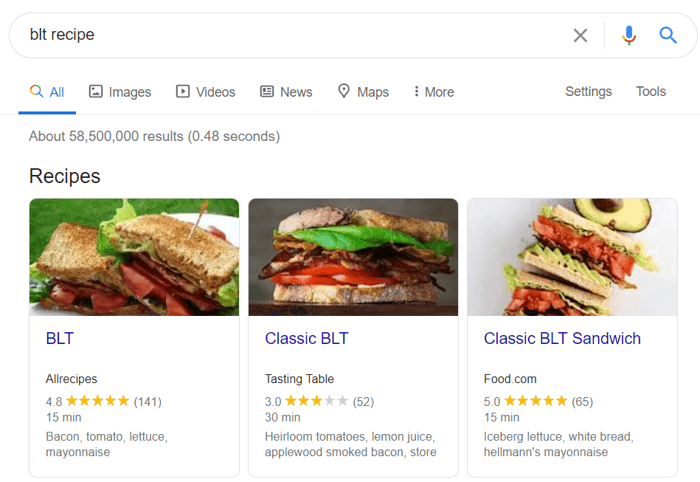
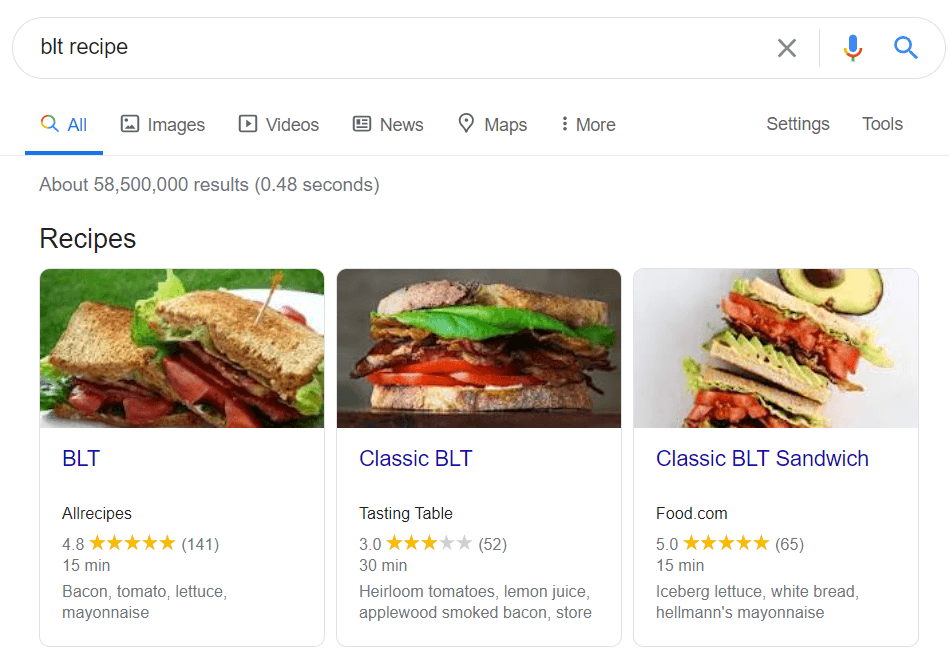
Il existe deux normes populaires de données structurées, OpenGraph pour un beau partage sur les réseaux sociaux et Schema pour les moteurs de recherche. Les variantes de l'implémentation du balisage sont les suivantes : Microdata, RDFa et JSON-LD . Les microdonnées et RDFa sont ajoutés au code HTML de la page, tandis que JSON-LD est un code JavaScript. Ce dernier est recommandé par Google.
Si le type de contenu de votre page est l'un des mentionnés ci-dessous, le balisage est particulièrement recommandé :
N'oubliez pas que la manipulation de données structurées peut entraîner des pénalités de la part des moteurs de recherche. Par exemple, le balisage ne doit pas décrire le contenu qui est caché aux utilisateurs (c'est-à-dire qui ne se trouve pas dans le HTML de la page). Testez votre balisage avec l' outil de test de données structurées avant la mise en œuvre.
Vous pouvez également vérifier votre balisage dans Google Search Console sous l'onglet Améliorations . GSC affichera les améliorations que vous avez essayé de mettre en œuvre sur votre site Web et vous dira si vous avez réussi.
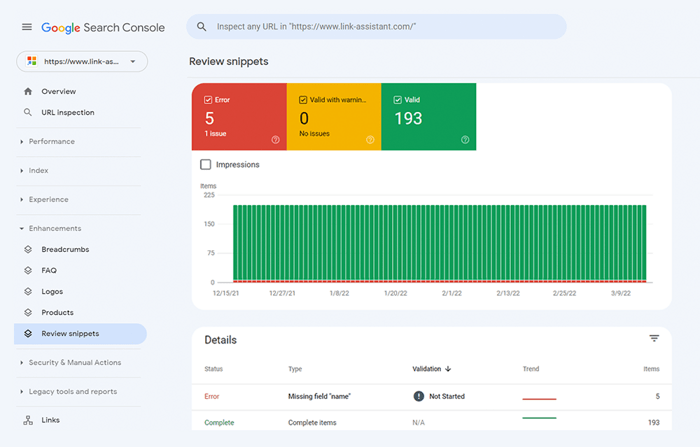
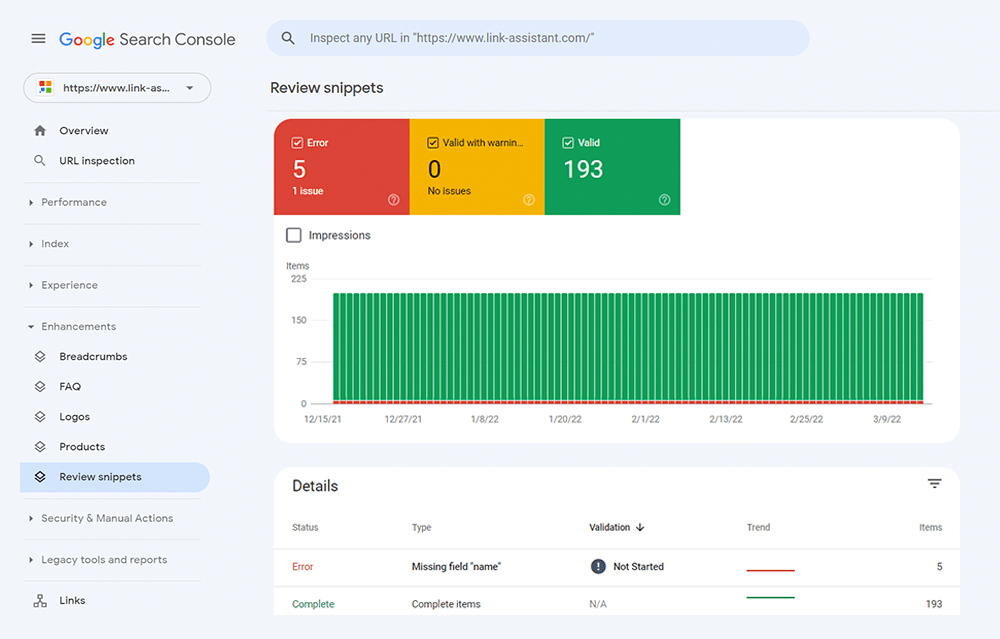
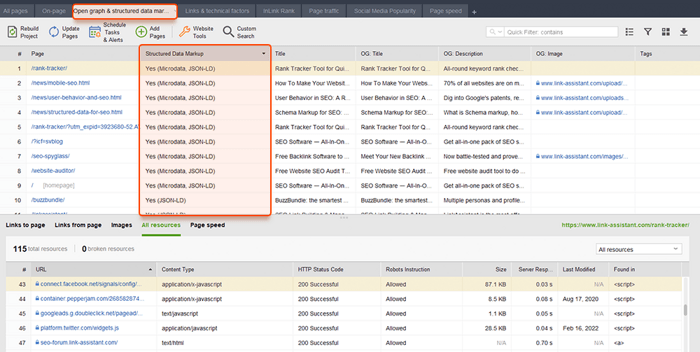
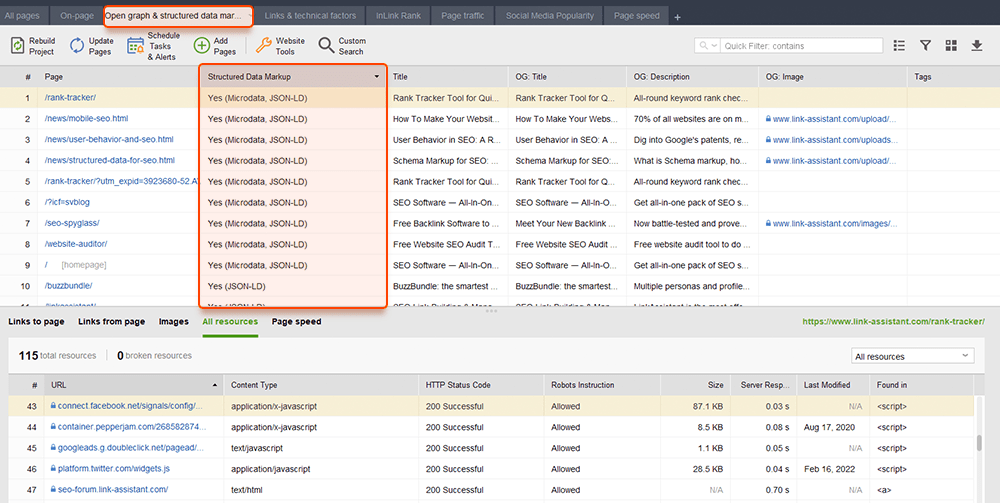
WebSite Auditor peut également vous aider ici. L'outil peut passer en revue toutes vos pages et montrer la présence de données structurées sur une page, son type, ses titres, ses descriptions et les URL des fichiers OpenGraph.
Si vous n'avez pas encore implémenté le Schema Markup, consultez ce guide SEO sur les données structurées . Notez que si votre site Web utilise un CMS, les données structurées peuvent être implémentées par défaut, ou vous pouvez les ajouter en installant un plugin (n'abusez pas des plugins de toute façon).
Une fois que vous avez audité votre site Web et corrigé tous les problèmes découverts, vous pouvez demander à Google de réexplorer vos pages pour lui permettre de voir les modifications plus rapidement.
Dans Google Search Console, soumettez l'URL mise à jour à l'outil d'inspection d'URL et cliquez sur Demander l'indexation . Vous pouvez également tirer parti de la fonctionnalité Tester l'URL en direct (anciennement connue sous le nom de fonctionnalité Explorer comme Google ) pour voir votre page dans sa forme actuelle, puis demander l'indexation.
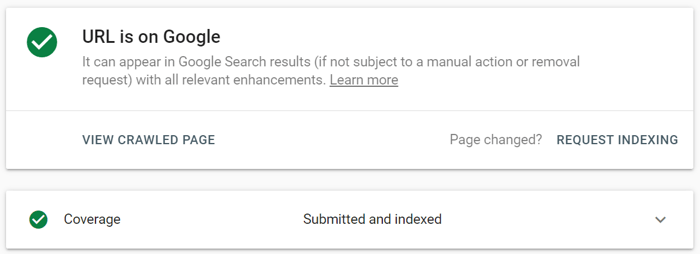
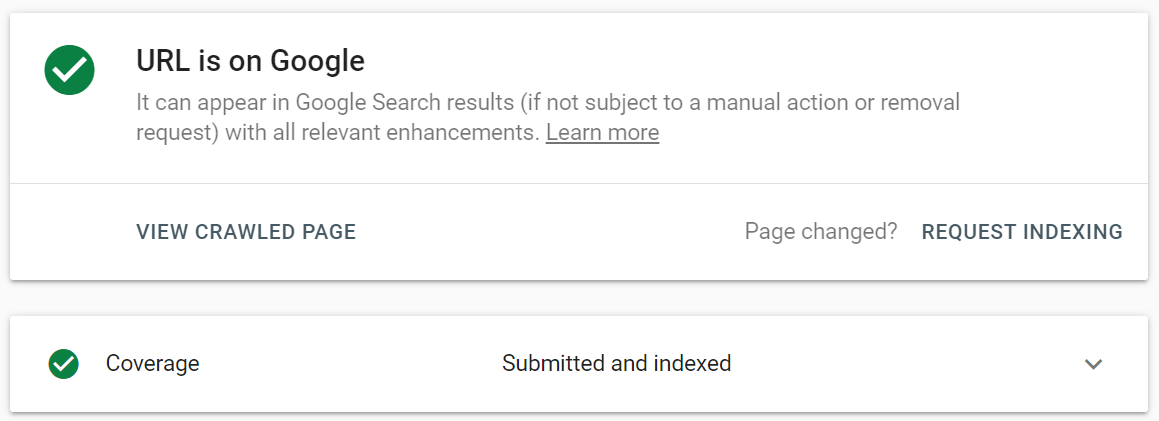
L'outil d'inspection d'URL permet d'étendre le rapport pour plus de détails, de tester les URL en direct et de demander l'indexation.
Gardez à l'esprit que vous n'avez pas besoin de forcer la nouvelle exploration chaque fois que vous modifiez quelque chose sur votre site Web. Envisagez de réexplorer si les changements sont sérieux : par exemple, vous avez déplacé votre site de http à https, ajouté des données structurées ou effectué une excellente optimisation du contenu, publié un article de blog urgent que vous souhaitez afficher plus rapidement sur Google, etc. Notez que Google a une limite sur le nombre d'actions de recrawl par mois, alors n'en abusez pas. De plus, la plupart des CMS soumettent les modifications à Google dès que vous les apportez, vous ne pouvez donc pas vous soucier de réexplorer si vous utilisez un CMS (comme Shopify ou WordPress).
Le recrawling peut prendre de quelques jours à plusieurs semaines, selon la fréquence à laquelle le crawler visite les pages. Demander une nouvelle exploration plusieurs fois n'accélérera pas le processus. Si vous devez réexplorer une quantité massive d'URL, soumettez un sitemap au lieu d'ajouter manuellement chaque URL à l'outil d'inspection d'URL.
La même option est disponible dans Bing Webmaster Tools. Choisissez simplement la section Configurer mon site dans votre tableau de bord et cliquez sur Soumettre les URL . Remplissez l'URL que vous devez réindexer et Bing l'explorera en quelques minutes. L'outil permet aux webmasters de soumettre jusqu'à 10 000 URL par jour pour la plupart des sites.
Beaucoup de choses peuvent se produire sur le Web, et la plupart d'entre elles sont susceptibles d'affecter votre classement plus ou moins bien. C'est pourquoi des audits techniques réguliers de votre site Web devraient être un élément essentiel de votre stratégie de référencement.
Par exemple, vous pouvez automatiser les audits SEO techniques dans WebSite Auditor . Il vous suffit de créer une tâche de reconstruction du projet et de définir les paramètres de planification (par exemple, une fois par mois) pour que votre site Web soit automatiquement réexaminé par l'outil et obtenir les nouvelles données.
Si vous avez besoin de partager les résultats de l'audit avec vos clients ou collègues, choisissez l'un des modèles de rapport SEO téléchargeables de WebSite Auditor ou créez-en un personnalisé.
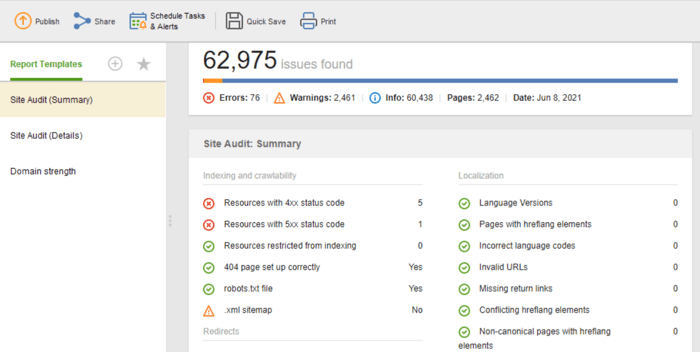
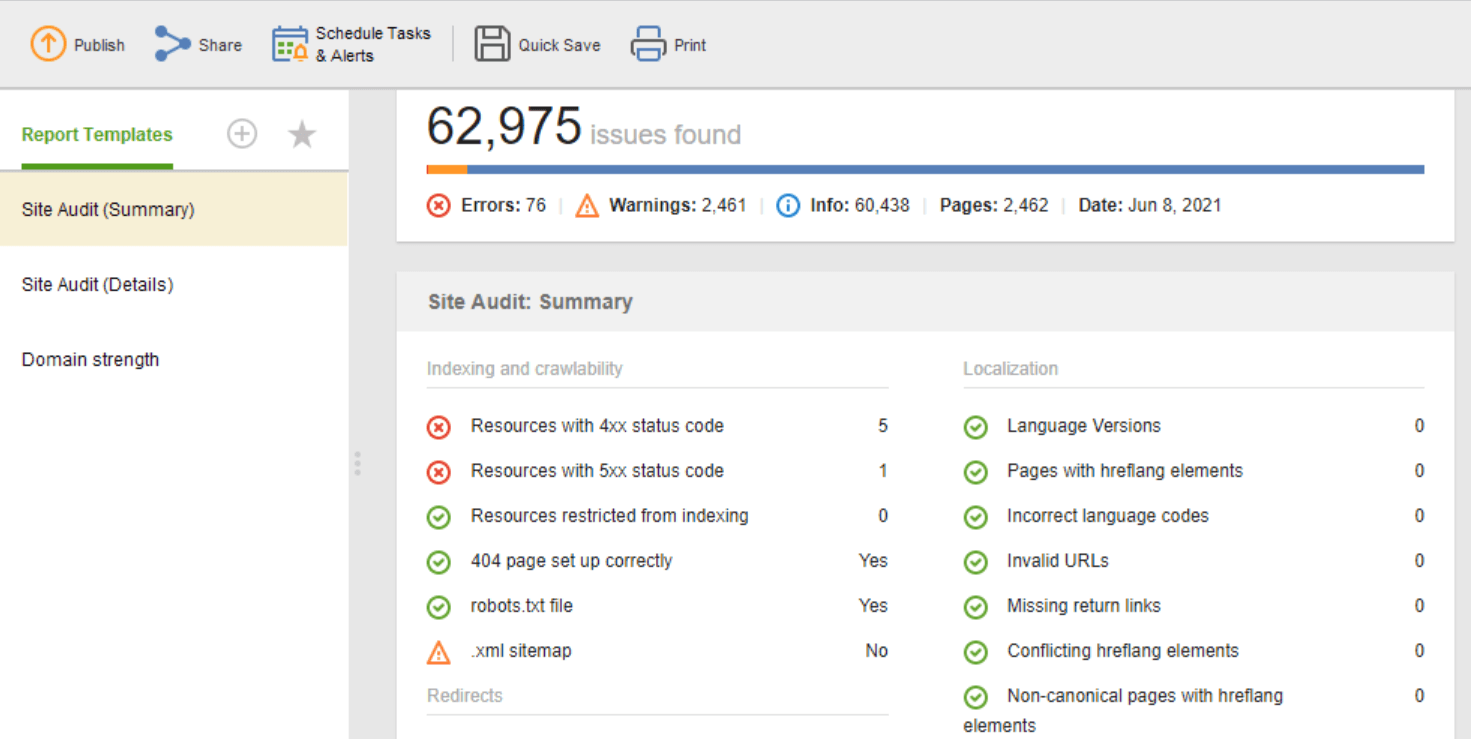
Le modèle d'audit de site (résumé) est idéal pour les éditeurs de sites Web pour voir l'étendue du travail d'optimisation à effectuer. Le modèle d'audit de site (détails) est plus explicatif, décrivant chaque problème et pourquoi il est important de le résoudre. Dans Website Auditor, vous pouvez personnaliser le rapport d'audit du site pour obtenir les données dont vous avez besoin pour surveiller régulièrement (indexation, liens brisés, sur la page, etc.). Ensuite, exportez au format CSV/PDF ou copiez-collez toutes les données dans une feuille de calcul à portée de main aux développeurs pour les correctifs.
De plus, vous pouvez obtenir une liste complète des problèmes techniques de référencement sur n'importe quel site Web rassemblés automatiquement dans un rapport d'audit de site dans notre auditeur de site Web. En plus de cela, un rapport détaillé fournira des explications sur chaque problème et comment le résoudre.
Ce sont les étapes de base d'un audit technique régulier du site. J'espère que le guide décrit au mieux les outils dont vous avez besoin pour effectuer un audit de site approfondi, les aspects SEO à prendre en compte et les mesures préventives à prendre pour maintenir une bonne santé SEO de votre site Web.
Qu'est-ce que le SEO technique ?
Le référencement technique traite de l'optimisation des aspects techniques d'un site Web qui aident les robots de recherche à accéder plus efficacement à vos pages. Le référencement technique couvre l'exploration, l'indexation, les problèmes côté serveur, l'expérience de la page, la génération de balises méta, la structure du site.
Comment mener un audit SEO technique ?
L'audit SEO technique commence par la collecte de toutes les URL et l'analyse de la structure globale de votre site Web. Ensuite, vous vérifiez l'accessibilité des pages, la vitesse de chargement, les balises, les détails sur la page, etc. Les outils techniques d'audit SEO vont des outils gratuits pour les webmasters aux araignées SEO, aux analyseurs de fichiers journaux, etc.
Quand dois-je auditer mon site ?
Les audits SEO techniques peuvent poursuivre différents objectifs. Vous voudrez peut-être auditer un site Web avant son lancement ou pendant le processus d'optimisation en cours. Dans d'autres cas, vous pouvez mettre en œuvre des migrations de sites ou vouloir lever les sanctions de Google. Pour chaque cas, l'étendue et les méthodes des audits techniques seront différentes.


| Linking websites | N/A |
| Backlinks | N/A |
| InLink Rank | N/A |