107804
•
20-minutę czytania
•


Algorytm PageRank (w skrócie PR) to system rankingu stron internetowych opracowany przez Larry Page i Sergey Brin na Uniwersytecie Stanforda pod koniec lat 90-tych. PageRank był właściwie podstawą, na której Page i Brin stworzyli wyszukiwarkę Google.
Od tego czasu minęło wiele lat i oczywiście algorytmy rankingowe Google stały się znacznie bardziej skomplikowane. Czy nadal opierają się na PageRank? Jak dokładnie PageRank wpływa na ranking, czy może być jedną z przyczyn spadku Twoich rankingów i na co SEO powinni przygotować się w przyszłości? Teraz znajdziemy i podsumujemy wszystkie fakty i tajemnice związane z PageRank, aby obraz był jasny. No cóż, na tyle, na ile możemy.
Jak wspomniano powyżej, w ramach swojego uniwersyteckiego projektu badawczego Brin i Page próbowali opracować system szacowania autorytetu stron internetowych. Postanowili zbudować ten system na linkach, które służyły jako wotum zaufania danej stronie. Zgodnie z logiką tego mechanizmu, im więcej zewnętrznych zasobów odsyła do strony, tym cenniejsze informacje niesie ona dla użytkowników. Natomiast PageRank (wynik od 0 do 10 obliczany na podstawie ilości i jakości linków przychodzących) pokazał względny autorytet strony w Internecie.
Przyjrzyjmy się, jak działa PageRank. Każdy link z jednej strony (A) do drugiej (B) oddaje tzw. głos, którego waga zależy od łącznej wagi wszystkich stron odsyłających do strony A. A nie możemy poznać ich wagi, dopóki nie obliczymy to, więc proces przebiega cyklicznie.
Wzór matematyczny oryginalnego PageRank jest następujący:
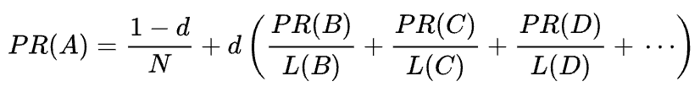
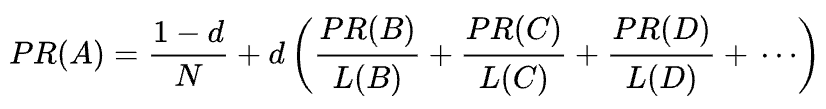
Gdzie A, B, C i D to kilka stron, L to liczba linków wychodzących z każdej z nich, a N to całkowita liczba stron w zbiorze (tj. w Internecie).
Jeśli chodzi o d, d jest tak zwanym współczynnikiem tłumienia. Biorąc pod uwagę, że PageRank jest obliczany symulując zachowanie użytkownika, który przypadkowo wchodzi na stronę i klika linki, stosujemy ten współczynnik tłumienia d jako prawdopodobieństwo, że użytkownik się znudzi i opuści stronę.
Jak widać ze wzoru, jeśli nie ma stron wskazujących na stronę, jej PR nie będzie wynosić zero, ale
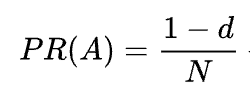
Ponieważ istnieje prawdopodobieństwo, że użytkownik może dostać się na tę stronę nie z innych stron, ale, powiedzmy, z zakładek.
Początkowo wynik PageRank był publicznie widoczny w pasku narzędzi Google Toolbar, a każda strona miała swój wynik od 0 do 10, najprawdopodobniej w skali logarytmicznej.
Algorytmy rankingowe Google w tamtych czasach były naprawdę proste — wysoki PR i gęstość słów kluczowych to jedyne dwie rzeczy, których strona potrzebowała, aby uzyskać wysoką pozycję w SERP. W rezultacie strony internetowe zostały przepełnione słowami kluczowymi, a właściciele witryn zaczęli manipulować PageRank poprzez sztuczne zwiększanie spamerskich linków zwrotnych. Było to łatwe do zrobienia — farmy linków i sprzedaż linków miały na celu zapewnienie właścicielom witryn „pomocnej dłoni”.
Google postanowiło walczyć ze spamem linkowym. W 2003 roku Google ukarał witrynę sieci reklamowej SearchKing za manipulacje linkami. SearchKing pozwał Google, ale Google wygrał. W ten sposób Google próbował uniemożliwić wszystkim manipulowanie linkami, jednak nie przyniosło to żadnego skutku. Farmy Link właśnie zeszły do podziemia, a ich ilość znacznie wzrosła.
Poza tym wzrosła także liczba spamerskich komentarzy na blogach. Boty zaatakowały komentarze na przykład dowolnego bloga WordPress i pozostawiły ogromną liczbę komentarzy typu „kliknij tutaj, aby kupić-magiczne-pigułki”. Aby zapobiec spamowi i manipulacji PR w komentarzach, Google wprowadził tag nofollow w 2005 roku. I po raz kolejny to, co Google zamierzało stać się skutecznym krokiem w wojnie o manipulację linkami, zostało wdrożone w pokrętny sposób. Ludzie zaczęli używać tagów nofollow, aby sztucznie kierować PageRank do potrzebnych im stron. Taktyka ta stała się znana jako rzeźbienie PageRank.
Aby zapobiec kształtowaniu PR, Google zmienił sposób przepływu PageRank. Poprzednio, jeśli strona zawierała zarówno linki nofollow, jak i dofollow, cały wolumen PR tej strony był przekazywany do innych stron, do których prowadziły linki dofollow. W 2009 roku Google zaczął równo dzielić PR strony pomiędzy wszystkie linki znajdujące się na stronie, przekazując tylko te udziały, które zostały przydzielone linkom dofollow.


Skończywszy z kształtowaniem PageRank, Google nie zaprzestał wojny ze spamem linkowym i zaczął konsekwentnie usuwać wynik PageRank z oczu opinii publicznej. Najpierw Google uruchomiło nową przeglądarkę Chrome bez paska narzędzi Google Toolbar, na którym pokazywany był wynik PR. Potem przestali raportować wynik PR w Google Search Console. Następnie przeglądarka Firefox przestała obsługiwać pasek narzędzi Google Toolbar. W 2013 r. po raz ostatni zaktualizowano PageRank dla przeglądarki Internet Explorer, a w 2016 r. Google oficjalnie zamknęło pasek narzędzi Toolbar dla publiczności.


Kolejnym sposobem, w jaki Google walczył ze schematami linków, była aktualizacja Penguin, która obniżała ranking witryn z podejrzanymi profilami linków zwrotnych. Wprowadzony w 2012 roku Penguin nie stał się częścią algorytmu Google czasu rzeczywistego, ale był raczej „filtrem” aktualizowanym i co jakiś czas ponownie stosowanym w wynikach wyszukiwania. Jeśli witryna została ukarana przez Penguina, SEO musiały dokładnie sprawdzić jej profile linków i usunąć toksyczne linki lub dodać je do listy, której się wypierają (funkcja wprowadzona wówczas, aby poinformować Google, które linki przychodzące mają ignorować przy obliczaniu PageRank). Po przeprowadzeniu w ten sposób audytu profili linków SEO musiały poczekać około pół roku, aż algorytm Penguin przeliczy dane.
W 2016 roku Google uczynił Penguina częścią swojego podstawowego algorytmu rankingowego. Od tego czasu działa w czasie rzeczywistym, algorytmicznie radząc sobie ze spamem znacznie skuteczniej.
Jednocześnie Google pracował nad poprawą jakości, a nie liczby linków, ugruntowując to w swoich wytycznych dotyczących jakości przeciwko schematom linków.
Cóż, mamy już dość przeszłości PageRank. Co się teraz dzieje?
W 2019 roku były pracownik Google powiedział, że oryginalny algorytm PageRank nie był używany od 2006 roku i został zastąpiony innym algorytmem, wymagającym mniej zasobów, w miarę rozwoju Internetu. Co może być prawdą, ponieważ w 2006 roku Google zgłosił nowy patent na tworzenie rankingu stron wykorzystujących odległości w grafie linków internetowych.
Tak to jest. To nie jest ten sam PageRank, co na początku XXI wieku, ale Google w dalszym ciągu w dużym stopniu polega na autorytecie linków. Na przykład były pracownik Google, Andrey Lipattsev, wspomniał o tym w 2016 r. Podczas spotkania z pytaniami i odpowiedziami w Google użytkownik zapytał go, jakie są główne sygnały rankingowe wykorzystywane przez Google. Odpowiedź Andrey była dość prosta.

Mogę ci powiedzieć, jakie one są. To treść i linki prowadzące do Twojej witryny.
W 2020 roku John Mueller po raz kolejny potwierdził, że:

Tak, używamy PageRank wewnętrznie i wielu, wielu innych sygnałów. To nie jest dokładnie to samo, co oryginalna publikacja, jest w niej wiele dziwactw (np. linki, których się wypierasz, linki ignorowane itp.) i znowu używamy wielu innych sygnałów, które mogą być znacznie silniejsze.
Jak widać PageRank wciąż żyje i jest aktywnie wykorzystywany przez Google do rankingu stron w sieci.
Co ciekawe, pracownicy Google stale nam przypominają, że istnieje wiele, wiele, WIELE innych czynników rankingowych Google. Ale patrzymy na to z przymrużeniem oka. Biorąc pod uwagę, ile wysiłku Google włożył w walkę ze spamem linkowym, w interesie Google może leżeć odwrócenie uwagi SEO od czynników podatnych na manipulację (takich jak linki zwrotne) i skierowanie tej uwagi na coś niewinnego i miłego. Ponieważ jednak SEO są dobrzy w czytaniu między wierszami, nadal uważają PageRank za silny sygnał rankingowy i zdobywają linki zwrotne na wszystkie możliwe sposoby. Nadal korzystają z PBN, ćwiczą budowanie linków metodą szarego kapelusza, kupują linki i tak dalej, tak jak to było dawno temu. Wraz z życiem PageRank, spam linkowy również będzie żywy. Nie zalecamy żadnego z tych rozwiązań, ale taka jest rzeczywistość SEO i musimy to zrozumieć.
Cóż, masz pomysł, że PageRank obecnie nie jest tym samym PageRank, co 20 lat temu.
Jedną z kluczowych modernizacji PR było przejście od wspomnianego pokrótce modelu Random Surfer do modelu Reasonable Surfer w 2012 roku. Reasonable Surfer zakłada, że użytkownicy nie zachowują się chaotycznie na stronie, a klikają tylko te linki, które ich interesują. za chwilę. Załóżmy, że czytając artykuł na blogu, z większym prawdopodobieństwem klikniesz łącze w treści artykułu niż łącze Warunki korzystania w stopce.
Ponadto rozsądny surfer może potencjalnie wykorzystać wiele innych czynników przy ocenie atrakcyjności łącza. Wszystkie te czynniki zostały szczegółowo omówione przez Billa Sławskiego w jego artykule, ja jednak chciałbym skupić się na dwóch czynnikach, o których SEO najczęściej dyskutuje. Są to pozycja linku i ruch na stronie. Co możemy powiedzieć o tych czynnikach?
Link może znajdować się w dowolnym miejscu strony – w jej treści, menu nawigacyjnym, biografii autora, stopce, a właściwie dowolnym elemencie strukturalnym strony. Różne lokalizacje linków wpływają na wartość linku. Potwierdził to John Mueller, mówiąc, że linki umieszczone w treści głównej ważą więcej niż wszystkie pozostałe:
To jest obszar strony, na którym znajduje się podstawowa treść, treść, której właściwie dotyczy ta strona, a nie menu, pasek boczny, stopka, nagłówek… Zatem bierzemy to pod uwagę i staramy się korzystać z tych linków.
Dlatego mówi się, że linki w stopce i linki nawigacyjne mają mniejszą wagę. I fakt ten od czasu do czasu potwierdzają nie tylko rzecznicy Google, ale także przypadki z życia wzięte.
W niedawnym przypadku przedstawionym przez Martina Haymana z BrightonSEO Martin dodał link, który miał już w swoim menu nawigacyjnym do głównej zawartości stron. W rezultacie te strony kategorii i strony, do których prowadzą linki, odnotowały wzrost ruchu o 25%.
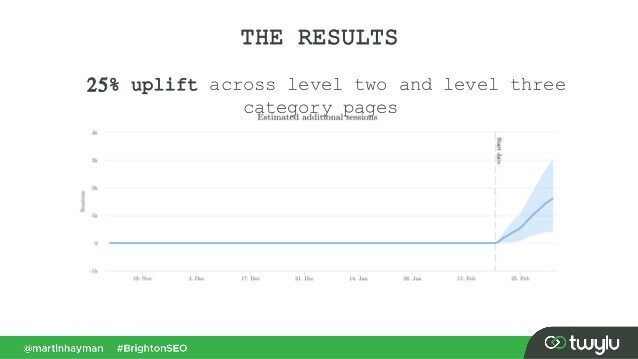
Ten eksperyment dowodzi, że linki do treści mają większą wagę niż jakiekolwiek inne.
Jeśli chodzi o linki w biografii autora, SEO zakładają, że biolinki coś ważą, ale są mniej wartościowe niż, powiedzmy, linki do treści. Chociaż nie mamy tutaj zbyt wielu dowodów poza tym, co powiedział Matt Cutts, gdy Google aktywnie walczył z nadmiernym blogowaniem gości w celu uzyskania linków zwrotnych.
John Mueller wyjaśnił, w jaki sposób Google traktuje ruch i zachowanie użytkowników w kontekście przekazywania linków w jednym z hangoutów w Search Console Central. Użytkownik zapytał Muellera, czy Google oceniając jakość linku, bierze pod uwagę prawdopodobieństwo kliknięcia i liczbę kliknięć linku. Najważniejsze wnioski z odpowiedzi Muellera brzmiały:
Google nie bierze pod uwagę kliknięć linków ani prawdopodobieństwa kliknięcia przy ocenie jakości linku.
Google zdaje sobie sprawę, że do treści często dodawane są linki, takie jak odniesienia, i nie oczekuje się, że użytkownicy będą klikać każdy napotkany link.
Mimo to, jak zawsze, SEO wątpią, czy warto ślepo wierzyć we wszystko, co mówi Google, i dalej eksperymentować. Dlatego też ludzie z Ahrefs przeprowadzili badanie, aby sprawdzić, czy pozycja strony w SERP jest powiązana z liczbą linków zwrotnych ze stron o dużym ruchu. Badanie wykazało, że nie ma prawie żadnej korelacji. Co więcej, okazało się, że niektóre najwyżej notowane strony w ogóle nie miały linków zwrotnych ze stron generujących duży ruch.
To badanie wskazuje nam podobny kierunek, jak słowa Johna Muellera – nie musisz tworzyć generujących ruch linków zwrotnych do swojej strony, aby uzyskać wysokie pozycje w SERP. Z drugiej strony, dodatkowy ruch nigdy nie wyrządził szkody żadnej witrynie internetowej. Jedynym przesłaniem jest to, że linki zwrotne generujące duży ruch nie wydają się mieć wpływu na rankingi Google.
Jak pamiętacie, Google wprowadził tag nofollow w 2005 roku jako sposób na walkę ze spamem linkowym. Czy coś się dzisiaj zmieniło? Aktualnie tak.
Po pierwsze, Google wprowadziło ostatnio dwa kolejne typy atrybutu nofollow. Wcześniej Google sugerował oznaczenie wszystkich linków zwrotnych, których nie chcesz brać pod uwagę w obliczaniu PageRank, jako nofollow, czy to komentarzy na blogu, czy płatnych reklam. Obecnie Google zaleca używanie atrybutu rel="sponsored" w przypadku linków płatnych i partnerskich oraz rel="ugc" w przypadku treści generowanych przez użytkowników.

Co ciekawe, te nowe tagi nie są obowiązkowe (przynajmniej jeszcze nie), a Google zwraca uwagę, że nie trzeba ręcznie zmieniać wszystkich rel=”nofollow” na rel="sponsored" i rel="ugc". Te dwa nowe atrybuty działają teraz tak samo jak zwykły tag nofollow.
Po drugie, Google twierdzi, że tagi nofollow, a także nowe, sponsorowane i ugc, są traktowane jako wskazówki, a nie wytyczne podczas indeksowania stron.
Oprócz linków przychodzących istnieją również linki wychodzące, czyli linki prowadzące do innych stron z Twojej witryny.
Wielu SEO uważa, że linki wychodzące mogą mieć wpływ na rankingi, jednak założenie to zostało potraktowane jako mit SEO. Ale jest jedno interesujące badanie, któremu warto się przyjrzeć w tym zakresie.
Reboot Online przeprowadził eksperyment w 2015 r. i przeprowadził go ponownie w 2020 r. Chcieli sprawdzić, czy obecność linków wychodzących do stron o wysokim autorytecie wpływa na pozycję strony w SERP. Stworzyli 10 stron internetowych z artykułami zawierającymi 300 słów, wszystkie zoptymalizowane pod nieistniejące słowo kluczowe - Phylandocic. W 5 witrynach w ogóle nie było linków wychodzących, a w 5 witrynach znajdowały się linki wychodzące do zasobów o wysokim autorytecie. W rezultacie witryny z wiarygodnymi linkami wychodzącymi zaczęły zajmować najwyższe pozycje w rankingach, a te, które w ogóle nie zawierały linków, zajęły najniższe pozycje.

Z jednej strony wyniki tego badania mogą nam powiedzieć, że linki wychodzące rzeczywiście wpływają na pozycje stron. Z drugiej strony wyszukiwane hasło użyte w badaniu jest zupełnie nowe, a treść stron internetowych poświęcona jest medycynie i narkotykom. Istnieje więc duże prawdopodobieństwo, że zapytanie zostało sklasyfikowane jako YMYL. Google wielokrotnie podkreślał znaczenie EAT dla witryn YMYL. Zatem linki wychodzące mogły zostać potraktowane jako sygnał EAT, potwierdzający, że strony zawierają treść zgodną z faktami.
Jeśli chodzi o zwykłe zapytania (nie YMYL), John Mueller wielokrotnie mówił, że nie musisz bać się linkowania do zewnętrznych źródeł w swoich treściach, ponieważ linki wychodzące są dobre dla Twoich użytkowników.
Poza tym linki wychodzące mogą być również korzystne dla SEO, ponieważ mogą zostać uwzględnione przez Google AI podczas filtrowania sieci przed spamem. Ponieważ strony zawierające spam mają zwykle niewiele linków wychodzących, jeśli w ogóle je mają. Albo prowadzą do stron w tej samej domenie (jeśli kiedykolwiek myślą o SEO), albo zawierają tylko linki płatne. Jeśli więc zamieścisz link do wiarygodnych zasobów, w pewnym sensie pokażesz Google, że Twoja strona nie zawiera spamu.
Kiedyś pojawiła się opinia, że Google może nałożyć ręczną karę za posiadanie zbyt dużej liczby linków wychodzących, ale John Mueller stwierdził, że jest to możliwe tylko wtedy, gdy linki wychodzące są w sposób oczywisty częścią jakiegoś schematu wymiany linków, a witryna w ogóle jest słaba jakość. To, co Google ma na myśli pod pojęciem oczywistym, jest w rzeczywistości tajemnicą, dlatego należy pamiętać o zdrowym rozsądku, wysokiej jakości treści i podstawowym SEO.
Dopóki PageRank istnieje, SEO będą szukać nowych sposobów manipulowania nim.
W 2012 roku Google częściej podejmował ręczne działania w przypadku manipulacji linkami i spamu. Jednak teraz, dzięki dobrze wyszkolonym algorytmom antyspamowym, Google może po prostu zignorować niektóre spamerskie linki podczas obliczania PageRank, zamiast ogólnie obniżać ranking całej witryny. Jak powiedział John Mueller:
Losowe linki zbierane przez lata niekoniecznie są szkodliwe, widujemy je już od dłuższego czasu i możemy zignorować wszystkie te dziwne fragmenty internetowych graffiti sprzed dawna.
Dotyczy to również negatywnego SEO, gdy Twój profil linków zwrotnych zostanie naruszony przez konkurencję:
Ogólnie rzecz biorąc, automatycznie bierzemy je pod uwagę i staramy się… automatycznie je ignorować, gdy widzimy, że mają miejsce. W większości przypadków podejrzewam, że działa to całkiem nieźle. Widzę bardzo niewiele osób, które mają w tej kwestii rzeczywiste problemy. Więc myślę, że to w większości działa dobrze. Jeśli chodzi o wyrzekanie się tych linków, podejrzewam, że jeśli są to zwykłe linki spamowe, które właśnie pojawiają się w Twojej witrynie, to nie przejmowałbym się nimi zbytnio. Prawdopodobnie sami do tego doszliśmy.
Nie oznacza to jednak, że nie masz się czym martwić. Jeśli linki zwrotne Twojej witryny będą zbyt często i zbyt często ignorowane, nadal istnieje duże prawdopodobieństwo, że zostaną podjęte ręczne działania. Jak mówi Marie Haynes w swoich poradach dotyczących zarządzania linkami w 2021 roku:

Ręczne działania są zarezerwowane dla przypadków, gdy skądinąd przyzwoita witryna zawiera nienaturalne linki prowadzące do niej na skalę tak dużą, że algorytmy Google nie czują się komfortowo, je ignorując.
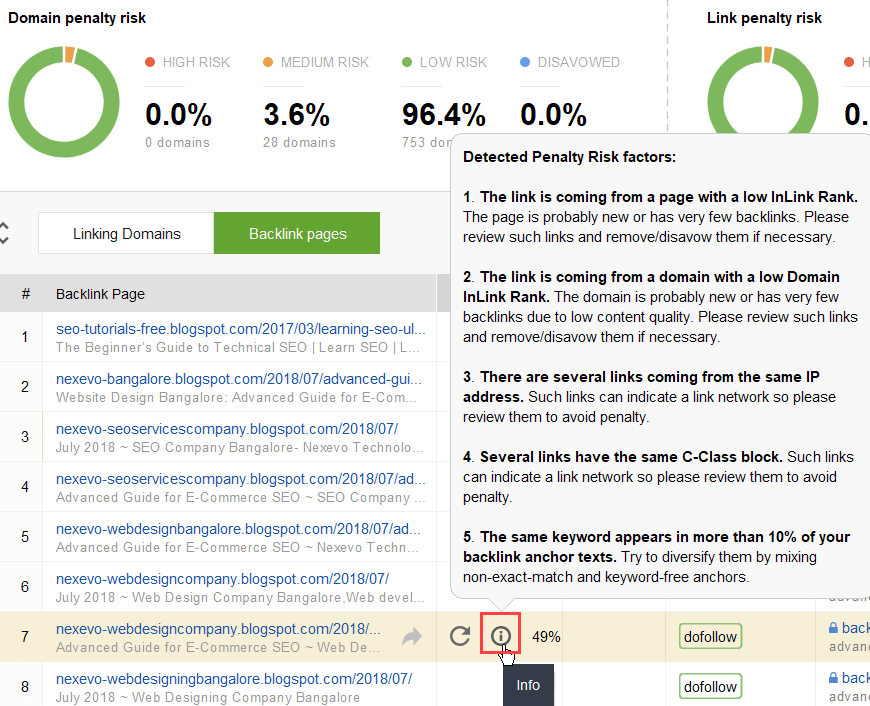
Aby spróbować dowiedzieć się, które linki powodują problem, przeczytaj ten przewodnik dotyczący sprawdzania jakości linków zwrotnych. Krótko mówiąc, możesz użyć narzędzia do sprawdzania linków zwrotnych, takiego jak SEO SpyGlass. W narzędziu przejdź do sekcji Profil linku zwrotnego > Ryzyko kar. Zwróć uwagę na linki zwrotne wysokiego i średniego ryzyka.
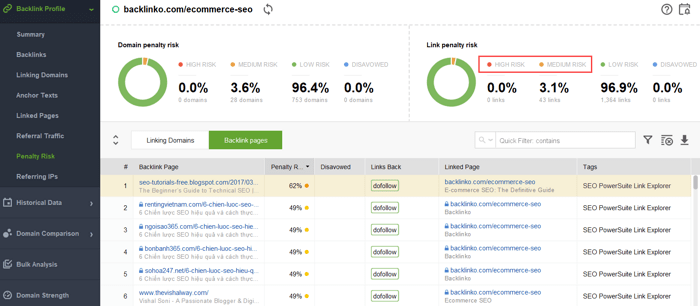
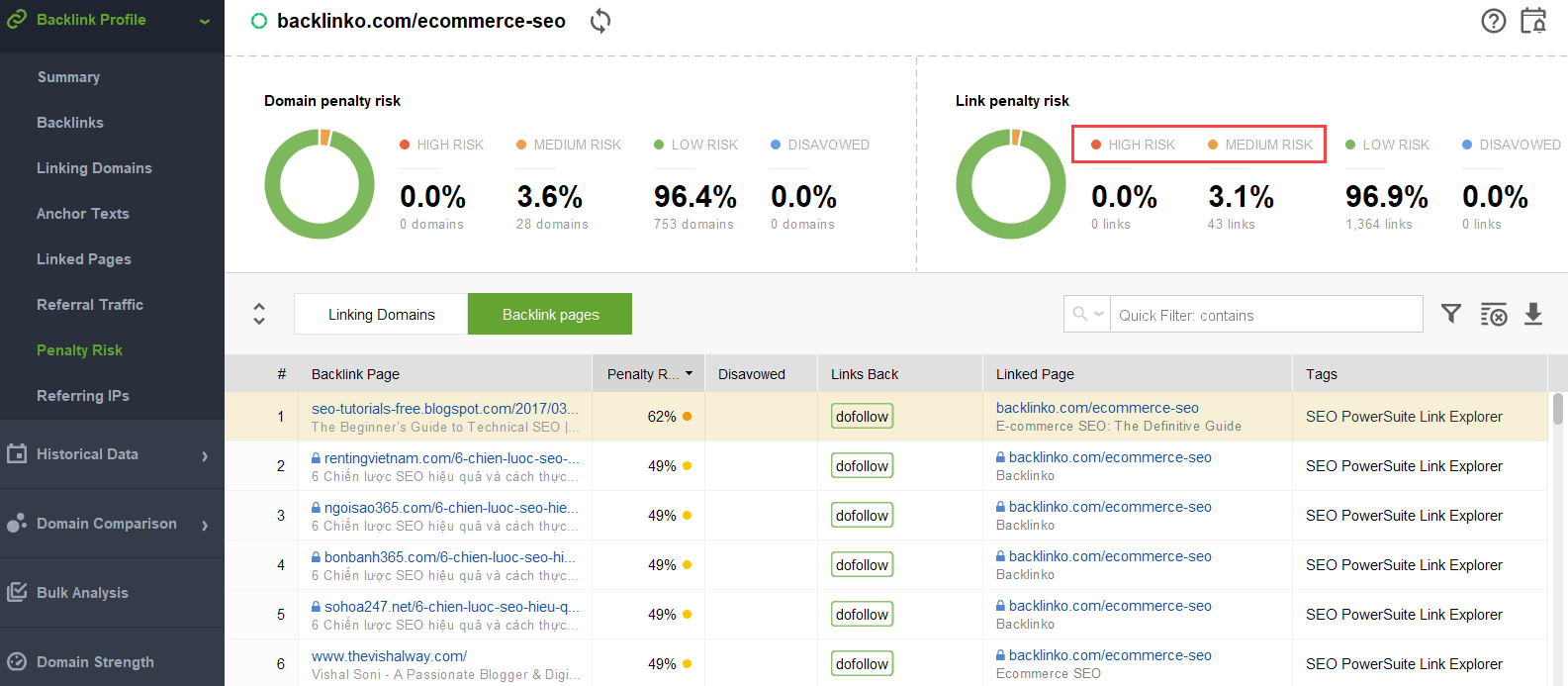
Aby dokładniej sprawdzić, dlaczego ten lub inny link został zgłoszony jako szkodliwy, kliknij znak „i” w kolumnie Ryzyko kary. Tutaj zobaczysz, dlaczego narzędzie uznało link za zły i podejmiesz decyzję, czy wyprzeć się linku, czy nie.
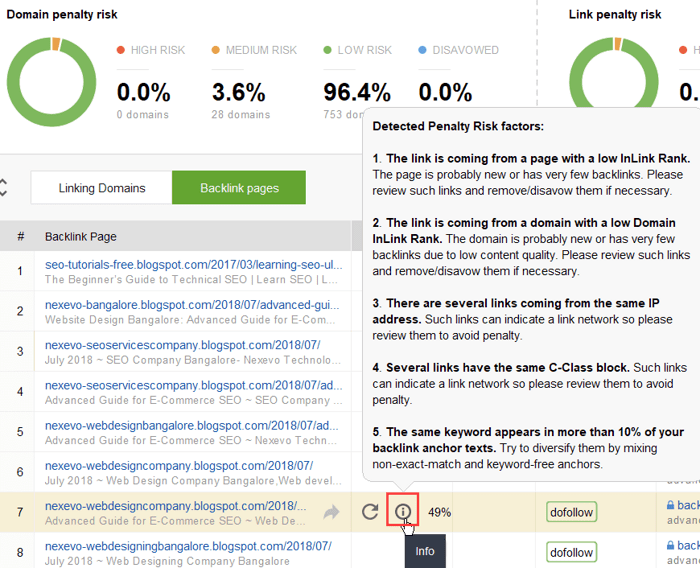
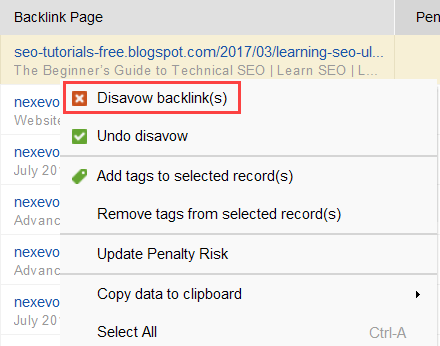
Jeśli zdecydujesz się odrzucić link z grupy linków, kliknij je prawym przyciskiem myszy i wybierz opcję Wyrzeknij się linków zwrotnych:
Po utworzeniu listy linków do wykluczenia możesz wyeksportować plik wyparcia się z SEO SpyGlass i przesłać go do Google za pośrednictwem GSC.
Mówiąc o PageRank, nie możemy nie wspomnieć o linkowaniu wewnętrznym. Nadchodzący PageRank to rzecz, na którą nie mamy wpływu, ale możemy całkowicie kontrolować sposób, w jaki PR rozprzestrzenia się na stronach naszej witryny.
Google również wielokrotnie podkreślał znaczenie linkowania wewnętrznego. John Mueller podkreślił to jeszcze raz podczas jednego z ostatnich spotkań w Search Console Central. Użytkownik zapytał, jak zwiększyć wydajność niektórych stron internetowych. A John Mueller powiedział, co następuje:
...Możesz pomóc w linkowaniu wewnętrznym. Tak więc w swojej witrynie możesz naprawdę wyróżnić strony, które chcesz bardziej wyróżnić i upewnić się, że są one naprawdę dobrze połączone wewnętrznie. A może strony, które nie wydają Ci się aż tak ważne, upewnij się, że są nieco mniej powiązane wewnętrznie.
Linkowanie wewnętrzne naprawdę wiele znaczy. Pomaga udostępniać przychodzący PageRank pomiędzy różnymi stronami w Twojej witrynie, wzmacniając w ten sposób strony o słabszych wynikach i ogólnie czyniąc Twoją witrynę silniejszą.
Jeśli chodzi o podejście do linkowania wewnętrznego, SEO mają wiele różnych teorii. Jedno z popularnych podejść wiąże się z głębokością kliknięcia w witrynie. Pomysł ten mówi, że wszystkie strony w Twojej witrynie muszą znajdować się w odległości maksymalnie 3 kliknięć od strony głównej. Chociaż Google również wielokrotnie podkreślał znaczenie płytkiej struktury witryny, w rzeczywistości wydaje się ona nieosiągalna dla wszystkich większych niż małe witryn internetowych.
Jeszcze jedno podejście opiera się na koncepcji scentralizowanego i zdecentralizowanego łączenia wewnętrznego. Jak opisuje to Kevin Indig:

Scentralizowane witryny mają pojedynczy przepływ użytkownika i ścieżkę prowadzącą do jednej kluczowej strony. Witryny ze zdecentralizowanymi linkami wewnętrznymi mają wiele punktów styku z konwersją lub różne formaty rejestracji.
W przypadku scentralizowanego linkowania wewnętrznego mamy małą grupę stron konwersji lub jedną stronę, która ma być potężna. Jeśli zastosujemy zdecentralizowane linkowanie wewnętrzne, chcemy, aby wszystkie strony witryny były równie mocne i miały równy PageRank, aby wszystkie uzyskały ranking pod kątem Twoich zapytań.
Która opcja jest lepsza? Wszystko zależy od specyfiki Twojej witryny i niszy biznesowej oraz od słów kluczowych, na które zamierzasz kierować reklamy. Na przykład scentralizowane linkowanie wewnętrzne lepiej pasuje do słów kluczowych o dużej i średniej liczbie wyszukiwań, ponieważ skutkuje wąskim zestawem super wydajnych stron.
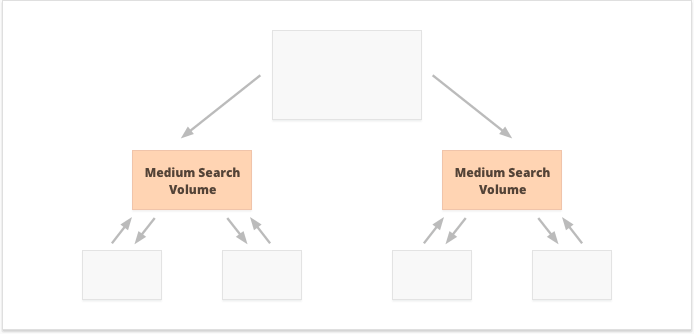
Wręcz przeciwnie, słowa kluczowe z długim ogonem i małą liczbą wyszukiwań są lepsze w przypadku zdecentralizowanych linków wewnętrznych, ponieważ równomiernie rozkładają PR na wiele stron internetowych.
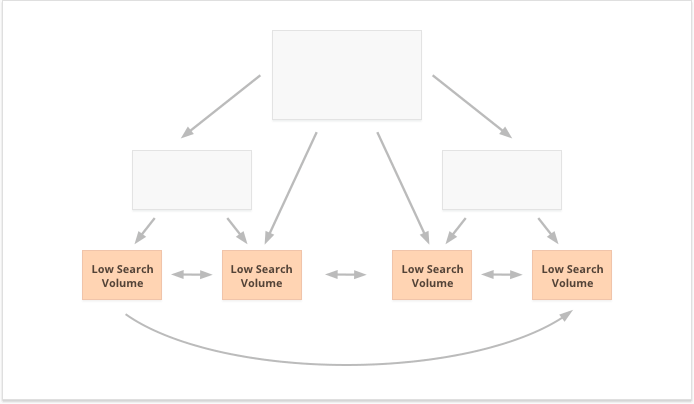
Jeszcze jednym aspektem udanego linkowania wewnętrznego jest równowaga linków przychodzących i wychodzących na stronie. W związku z tym wielu SEO korzysta z CheiRank (CR), który w rzeczywistości jest odwrotnością PageRank. Ale chociaż PageRank to otrzymana moc, CheiRank to moc oddana przez łącze. Po obliczeniu PR i CR dla swoich stron możesz zobaczyć, które strony mają anomalie w linkach, tj. przypadki, gdy strona otrzymuje dużo PageRank, ale nieznacznie przechodzi dalej i odwrotnie.
Ciekawym eksperymentem jest spłaszczenie anomalii łączy Kevina Indiga. Samo upewnienie się, że przychodzący i wychodzący PageRank jest zrównoważony na każdej stronie witryny, przyniosło imponujące rezultaty. Czerwona strzałka wskazuje tutaj czas, w którym anomalie zostały naprawione:
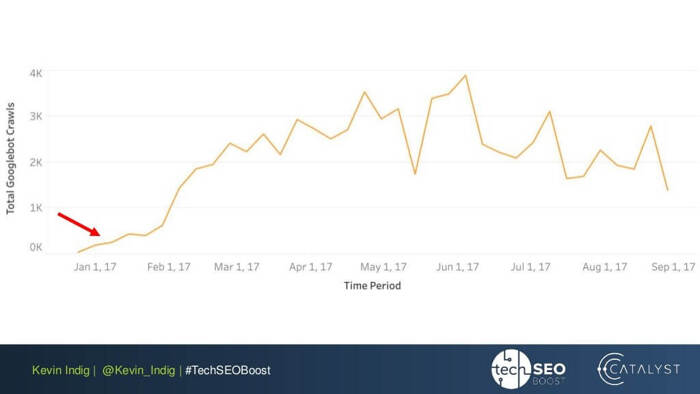
Anomalie linków nie są jedyną rzeczą, która może zaszkodzić przepływowi PageRank. Upewnij się, że nie utkniesz w żadnych problemach technicznych, które mogłyby zniszczyć Twój ciężko wypracowany PR:
Strony osierocone. Strony osierocone nie są powiązane z żadną inną stroną w Twojej witrynie, dlatego po prostu pozostają bezczynne i nie otrzymują żadnych linków. Google ich nie widzi i nie wie, że faktycznie istnieją.
Łańcuchy przekierowań. Chociaż Google twierdzi, że przekierowania obecnie spełniają 100% PR, nadal zaleca się unikanie długich łańcuchów przekierowań. Po pierwsze, i tak pożerają Twój budżet indeksowania. Po drugie, wiemy, że nie można ślepo wierzyć we wszystko, co mówi Google.
Linki w nieparsowalnym JavaScript. Ponieważ Google nie może ich odczytać, nie przejdą one do rankingu PageRank.
404 linki. Linki 404 prowadzą donikąd, więc PageRank też donikąd nie prowadzi.
Linki do nieistotnych stron. Oczywiście nie możesz pozostawić żadnej ze swoich stron bez żadnych linków, ale strony nie są sobie równe. Jeśli jakaś strona jest mniej ważna, nieracjonalne jest wkładanie zbyt dużego wysiłku w optymalizację profilu linków tej strony.
Zbyt odległe strony. Jeśli strona znajduje się zbyt głęboko w Twojej witrynie, prawdopodobnie nie będzie miała PR lub będzie miała niewielki PR. Ponieważ Google może nie być w stanie go znaleźć i zaindeksować.
Aby upewnić się, że Twoja witryna internetowa jest wolna od zagrożeń związanych z PageRank, możesz przeprowadzić jej audyt za pomocą narzędzia WebSite Auditor. To narzędzie posiada kompleksowy zestaw modułów w sekcji Struktura witryny > Audyt witryny, które pozwalają sprawdzić ogólną optymalizację Twojej witryny oraz, oczywiście, znaleźć i naprawić wszystkie problemy związane z linkami, takie jak długie przekierowania:
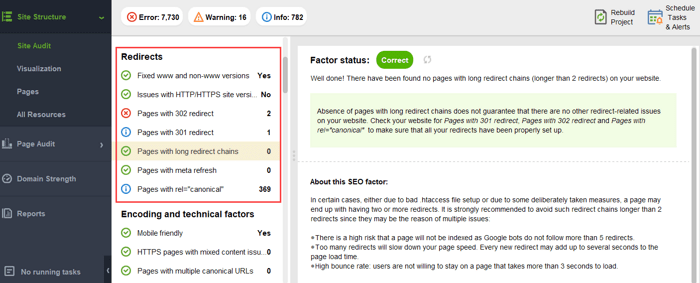
i niedziałające linki:
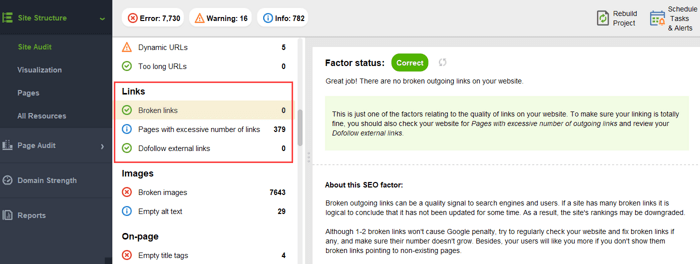
Aby sprawdzić witrynę pod kątem stron osieroconych lub stron, które są zbyt odległe, przejdź do opcji Struktura witryny > Wizualizacja:
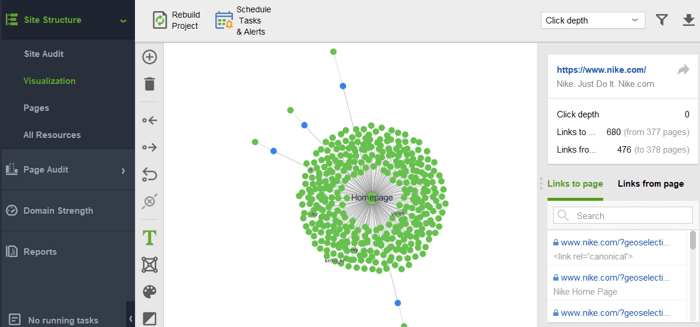
W tym roku PageRank skończył 23 lata. I wydaje mi się, że jest starszy niż niektórzy z naszych dzisiejszych czytelników:) Ale co czeka PageRank w przyszłości? Czy pewnego dnia całkowicie zniknie?
Kiedy myślę o popularnej wyszukiwarce, która nie wykorzystuje w swoim algorytmie linków zwrotnych, jedyny pomysł, jaki przychodzi mi do głowy, to eksperyment Yandex z 2014 roku. Wyszukiwarka ogłosiła, że usunięcie linków zwrotnych z ich algorytmu może w końcu powstrzymać spamerów linkujących przed manipulacją i pomóc skierować ich wysiłki na tworzenie wysokiej jakości witryn internetowych.
Mógł to być prawdziwy wysiłek zmierzający do zastosowania alternatywnych czynników rankingowych lub po prostu próba przekonania mas do porzucenia spamu linkowego. W każdym razie w ciągu zaledwie roku od ogłoszenia Yandex potwierdził, że czynniki linków zwrotnych wróciły do ich systemu.
Ale dlaczego linki zwrotne są tak niezbędne dla wyszukiwarek?
Chociaż dysponujesz niezliczoną liczbą innych punktów danych, które pozwalają na zmianę układu wyników wyszukiwania po rozpoczęciu ich wyświetlania (takich jak zachowanie użytkownika i korekty BERT ), linki zwrotne pozostają jednym z najbardziej wiarygodnych kryteriów potrzebnych do utworzenia początkowego SERP. Ich jedyną konkurentką są tu prawdopodobnie podmioty.
Jak ujął to Bill Sławski zapytany o przyszłość PageRank:
.png)
Google bada uczenie maszynowe i ekstrakcję faktów oraz zrozumienie kluczowych par wartości dla podmiotów gospodarczych, co oznacza ruch w kierunku wyszukiwania semantycznego oraz lepsze wykorzystanie danych strukturalnych i jakości danych.
Mimo to Google nie jest w stanie odrzucić czegoś, w co zainwestował dziesiątki lat rozwoju.
Google jest bardzo dobry w analizie linków, która jest obecnie bardzo dojrzałą technologią internetową. Z tego powodu jest całkiem możliwe, że PageRank będzie nadal używany do rankingu organicznych SERP.
Kolejnym trendem, na który wskazał Bill Sławski, były wiadomości i inne krótkotrwałe typy wyników wyszukiwania:
Firma Google poinformowała nas, że w mniejszym stopniu polegała na PageRank w przypadku stron, dla których ważniejsza jest aktualność, np. wyników w czasie rzeczywistym (np. z Twittera) lub wyników z wiadomościami, gdzie aktualność jest bardzo ważna.
Rzeczywiście, wiadomość jest w wynikach wyszukiwania o wiele za mała, aby zgromadzić wystarczającą liczbę linków zwrotnych. Dlatego Google pracował i może nadal pracować nad zastąpieniem linków zwrotnych innymi czynnikami rankingowymi w przypadku wiadomości.
Jednak na razie rankingi wiadomości w dużym stopniu zależą od niszowej autorytatywności wydawcy, a autorytatywność nadal odczytujemy jako linki zwrotne:
„Sygnały wiarygodności pomagają w priorytetyzacji informacji wysokiej jakości pochodzących z najbardziej wiarygodnych dostępnych źródeł. W tym celu nasze systemy identyfikują sygnały, które mogą pomóc w określeniu, które strony wykazują wiedzę specjalistyczną, autorytatywność i wiarygodność w danym temacie, na podstawie opinii osób oceniających wyszukiwarki Sygnały te mogą obejmować to, czy inne osoby cenią źródło podobnych zapytań lub czy inne znane witryny internetowe na ten temat zawierają linki do artykułu”.
I na koniec, byłem dość zaskoczony wysiłkiem Google, jaki włożył w identyfikację linków zwrotnych sponsorowanych i generowanych przez użytkowników oraz odróżnienie ich od innych linków nofollowed.
Jeśli wszystkie te linki zwrotne mają być ignorowane, po co odróżniać je od siebie? Zwłaszcza, że John Muller zasugerował, że później Google może spróbować inaczej traktować tego typu linki.
Moje najśmielsze przypuszczenie było takie, że być może Google sprawdza, czy reklamy i linki generowane przez użytkowników mogą stać się pozytywnym sygnałem rankingowym.
W końcu reklama na popularnych platformach wymaga ogromnych budżetów, a ogromne budżety są cechą dużej i popularnej marki.
Treści generowane przez użytkowników, jeśli wziąć pod uwagę je poza paradygmatem spamu w komentarzach, dotyczą prawdziwych klientów udzielających im poparcia w prawdziwym życiu.
Jednak eksperci, z którymi się skontaktowałem, nie wierzyli, że jest to możliwe:

Wątpię, żeby Google kiedykolwiek uznał linki sponsorowane za pozytywny sygnał.
Wydaje się, że pomysł jest taki, że rozróżniając różne typy linków, Google spróbuje dowiedzieć się, które z linków nofollow należy kliknąć w celu budowania encji:

Google nie ma nic przeciwko treściom generowanym przez użytkowników ani treściom sponsorowanym w witrynie internetowej, jednakże w przeszłości oba były wykorzystywane jako metody manipulowania pagerankem. W związku z tym zachęca się webmasterów do umieszczania atrybutu nofollow w tych linkach (jest to między innymi powód korzystania z nofollow). Linki nofollowe mogą jednak nadal być przydatne dla Google w różnych sytuacjach (np. w rozpoznawaniu podmiotów), dlatego zauważyli już wcześniej, że możesz potraktować to jako raczej sugestię, a nie dyrektywę, taką jak reguła nie zezwalająca na plik robots.txt, która znalazłaby się w Twojej witrynie. Oświadczenie Johna Muellera brzmiało: „Wyobrażam sobie, że w naszych systemach z czasem nauczymy się traktować je nieco inaczej.” Może to odnosić się do przypadków, w których Google traktuje nofollow jako sugestię. Hipotetycznie jest możliwe, że systemy Google dowiedzą się, które linki nofollowe należy kliknąć, na podstawie wniosków zebranych na podstawie typów linków oznaczonych jako ugc i sponsorowanych. Ponownie, nie powinno to mieć dużego wpływu na rankingi witryny - ale teoretycznie może mieć również wpływ na witrynę, do której prowadzą linki.
Mam nadzieję, że udało mi się wyjaśnić rolę linków zwrotnych w obecnych algorytmach wyszukiwania Google. Niektóre dane, na które natknąłem się podczas zbierania materiałów do artykułu, nawet dla mnie były zaskoczeniem. Dlatego z niecierpliwością czekam na dołączenie do dyskusji w komentarzach.
Czy są jeszcze jakieś pytania, na które nie masz odpowiedzi? Masz jakieś pomysły na przyszłość PageRank?
| Linking websites | N/A |
| Backlinks | N/A |
| InLink Rank | N/A |









