27668
•
Leitura de 12 minutos
•


Problemas de indexação podem tornar seus esforços de SEO nulos – uma página pode estar perfeitamente otimizada e ter uma ótima experiência do usuário, mas não vale de nada se o Google não a perceber. As páginas não indexadas não entrarão nas SERPs e não trarão tráfego e conversões.
Vice-versa, se o Google ocasionalmente vir e indexar uma página que não deveria ser indexada, você corre o risco de vazamento de informações privadas, penalidades do Google por conteúdo de baixa qualidade e outras consequências pouco satisfatórias.
Neste guia, compartilharei quais tipos de problemas de indexação existem e como corrigi-los para que não causem quedas repentinas na classificação. Mas primeiro, vamos ver como verificar se você tem algum problema de indexação em seu site.
O Google Search Console pode fornecer uma compreensão básica, mas ainda suficiente, dos problemas de indexação do seu site. Consulte o relatório Índice > Páginas para vê-los.
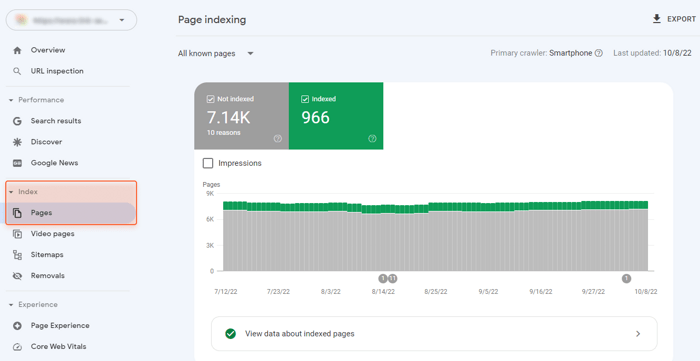
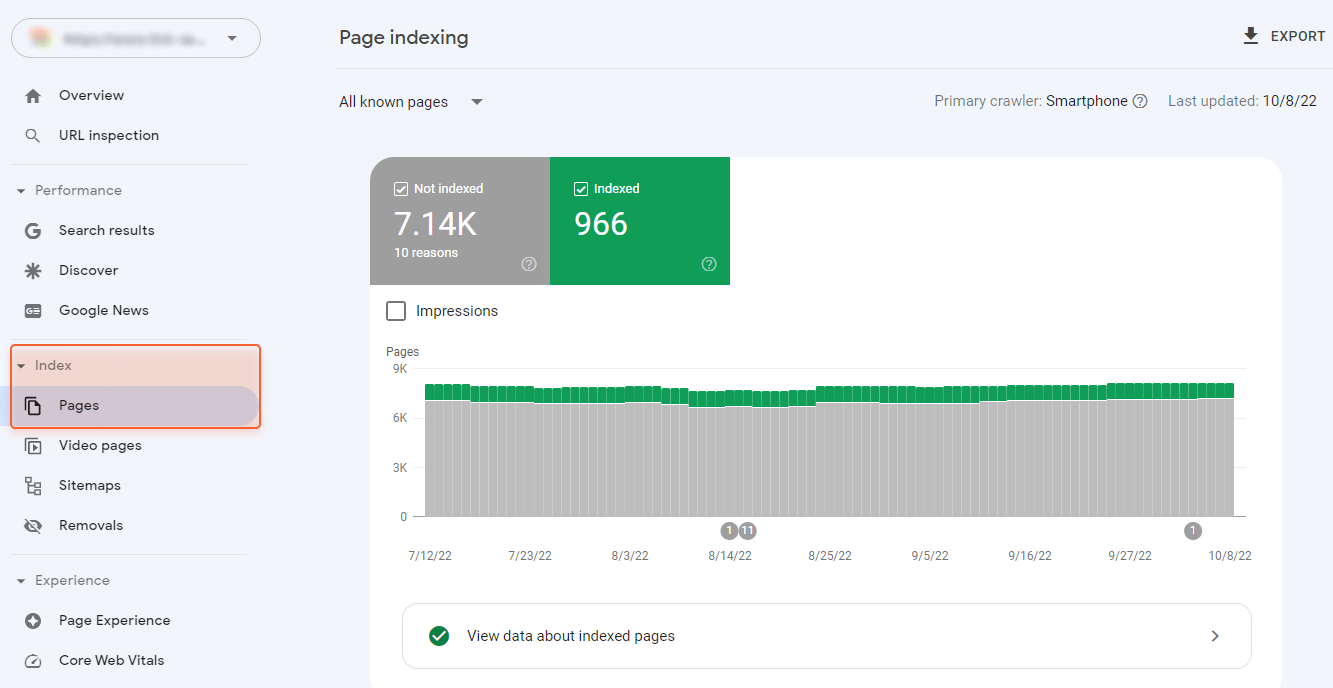
As páginas não indexadas, independentemente do motivo, são colocadas em uma seção, Not Indexed. As páginas que foram indexadas, mas ainda apresentam problemas e requerem sua atenção, podem ser encontradas na parte inferior da página, na seção Melhorar a aparência da página:
Para investigar melhor qualquer problema, clique na linha de erro e depois no ícone de lente próximo ao URL que você deseja verificar:
O Search Console mostrará os detalhes e ajudará a identificar o que há de errado com a página.
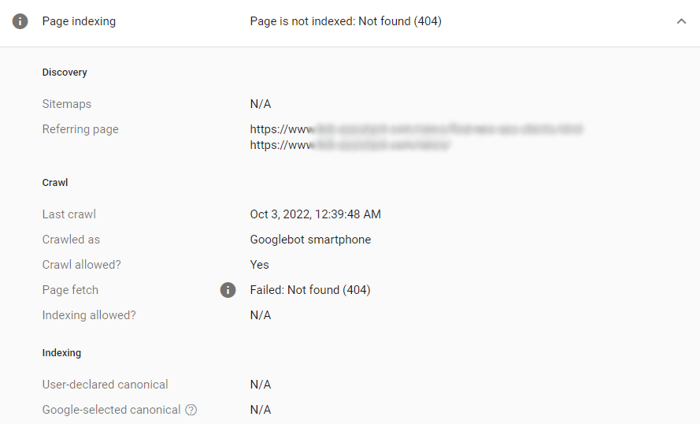
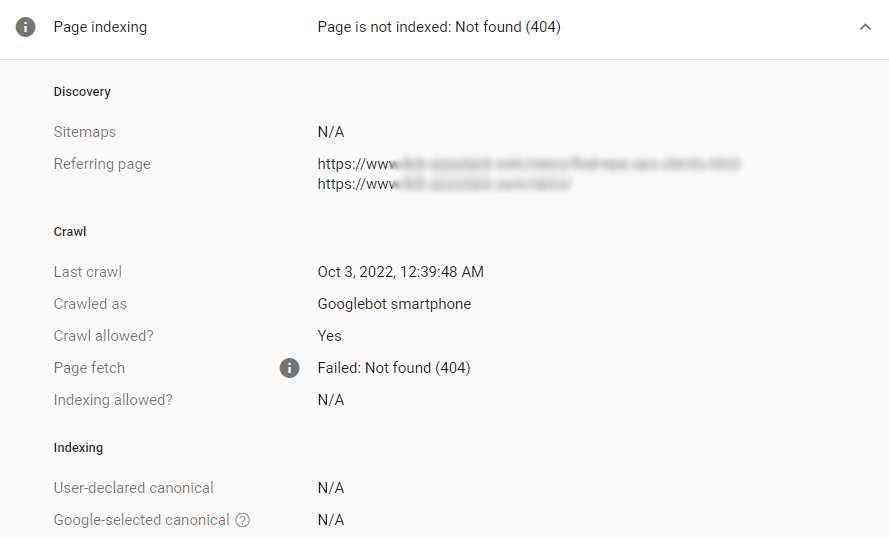
Quando você precisar se aprofundar e obter recomendações sobre o que corrigir para tornar uma página sólida, consulte a seção Indexação e rastreabilidade do WebSite Auditor:
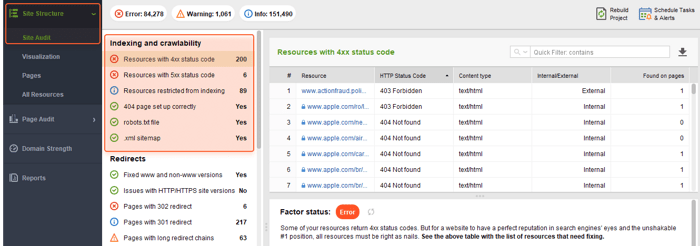
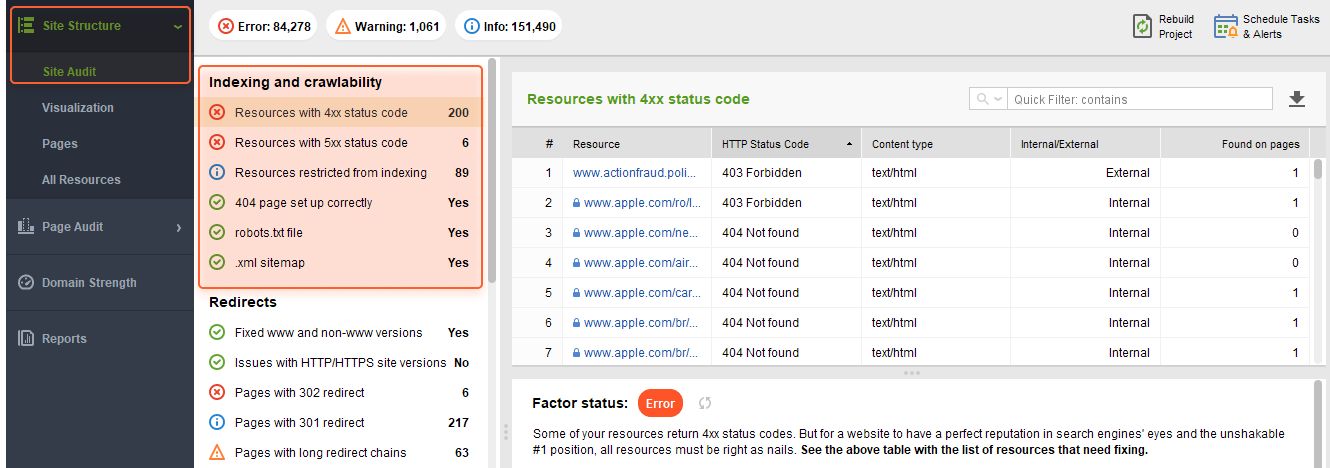
A ferramenta coletará todos os URLs com erros para que você não precise verificar manualmente cada página separadamente.
Bem, agora terminamos a parte “onde encontrar”. Agora é hora de ver quais tipos de problemas de indexação você pode encontrar e como corrigi-los para manter seu site rastreado e indexado.
Não encontrado (404) ou URL quebrado é provavelmente um dos problemas de indexação mais comuns. Uma página pode ter um código de status 404 por vários motivos. Digamos que você excluiu o URL, mas não removeu a página do mapa do site, escreveu o URL incorretamente, etc.
Como diz o Google, os próprios 404s não prejudicam o desempenho do seu site até que sejam URLs enviados (ou seja, aqueles que você pediu explicitamente ao Google para indexar).
Se você vir URLs 404 em seus relatórios de indexação, aqui estão as opções possíveis de como corrigi-los caso não fosse planejado:
Observe que o GSC não diferencia 404 (não encontrado) de 410 (desaparecido) e os reúne no relatório 404. Costumavam ser diferentes tipos de códigos de resposta: 404 significava “não encontrado, mas poderá ser encontrado mais tarde”, enquanto 410 significava “não encontrado e não será, pois desapareceu para sempre”.
Hoje, o Google diz que trata 404 e 410 da mesma forma, então você provavelmente não precisará se preocupar se encontrar uma página 410 no relatório 404. A única coisa que sugiro que você faça é definir uma página 404 personalizada em vez de uma 410 vazia para economizar tráfego e evitar que os usuários saiam do seu site.
Muitos SEOs e proprietários de sites têm o hábito de redirecionar erros 404 para a página inicial, mas a verdade é que essa não é a prática recomendada. Fazer isso é confuso para o Google e resulta em problemas 404. Bem, vamos ver o que são esses 404s suaves.
Problemas soft 404 acontecem quando uma página tem uma resposta 200 OK, mas o Google não consegue encontrar seu conteúdo e o considera um 404. Soft 404s podem ocorrer por vários motivos, e alguns deles podem nem depender de você, como erros nos navegadores dos usuários. Aqui estão mais alguns motivos:
Um arquivo de inclusão do lado do servidor ausente
Uma conexão interrompida com o banco de dados
Uma página de resultados de pesquisa interna vazia
Um arquivo JavaScript descarregado ou ausente
Muito pouco conteúdo
Cloaking de página
Na verdade, esses problemas não são tão difíceis de corrigir. Aqui estão alguns cenários comuns:
Se o conteúdo foi movido e a página está realmente 200 OK, mas vazia, configure um redirecionamento 301 para o novo endereço;
Se o conteúdo excluído não tiver alternativa, marque-o como 404 e remova-o do mapa do site;
Se a página existir, adicione algum conteúdo e verifique se todos os scripts nela são renderizados e exibidos corretamente (não bloqueados por robots.txt, suportados por navegadores, etc.);
Se o erro ocorrer porque o servidor está inativo quando o Googlebot tenta buscar a página, verifique se o servidor funciona bem. Se isso acontecer, solicite a reindexação desta página.
O erro 401 ocorre quando o Googlebot tenta acessar uma página que requer autorização e seu servidor impede que o Googlebot faça isso.
Se você deseja que essa página seja indexada, conceda ao Googlebot a permissão relevante ou remova a solicitação de autorização.
Esse tipo de erro ocorre quando o agente do usuário forneceu credenciais para entrar na página (login, senha), mas não recebeu acesso para realmente fazer isso. O Googlebot, porém, nunca fornece credenciais, então o servidor retorna 403 em vez da página pretendida.
Se uma página foi bloqueada por engano e você realmente precisa indexá-la, permita o acesso de usuários não conectados ou permita explicitamente que o Googlebot entre na página para lê-la e indexá-la.
Como fica claro pelo nome, esse erro ocorre quando você pede explicitamente ao Google para indexar uma página (ou seja, adicioná-la ao mapa do site ou solicitar indexação manualmente), mas essa página tem uma tag noindex.
A correção é bastante simples – remova a tag noindex para que o Google possa acessar a página.
Se você bloquear uma página com a ajuda do robots.txt, o Google não a rastreará. Remova as restrições para indexar a página.
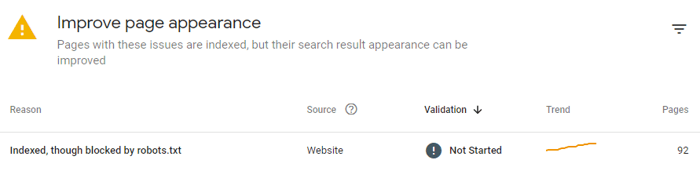
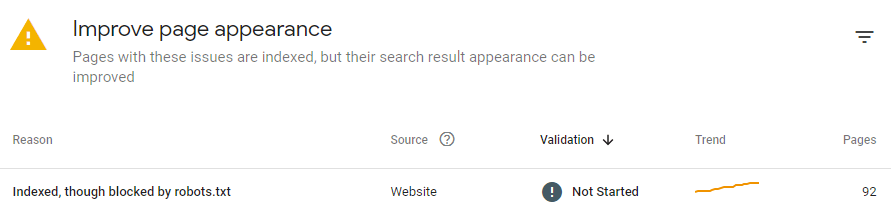
Nota: Robots.txt não é uma garantia de que a página não será indexada. É por isso que às vezes o Google Search Console pode mostrar algo assim:
Questões como essa podem trazer mais problemas do que páginas não indexadas, pois o Google pode acessar e revelar informações que não deveriam aparecer nas SERPs (como carrinhos, dados privados, etc.).
Se você se deparar com um problema como esse, decida se precisa ou não da página indexada. Nesse caso, remova o URL do arquivo robots.txt. Caso contrário, remova-o também do robots.txt, mas aplique a tag noindex ou limite o acesso para usuários não autorizados. Depois de aplicar novas restrições, você também pode solicitar ao Google que remova a página do índice por meio do GSC ( Índice > Remoções > Nova solicitação).
Esse é outro tipo de problema que pode prejudicar ainda mais o desempenho do seu site do que páginas não indexadas. O Google não favorece páginas vazias e provavelmente irá rebaixar suas posições, pois páginas vazias são um sinal de sites com spam e conteúdo de baixa qualidade.
Se você notar que algumas de suas páginas estão com o status Indexado sem conteúdo, verifique manualmente a URL para descobrir o motivo. Por exemplo:
A página pode ter pouco conteúdo;
A página pode ter algum conteúdo que bloqueia a renderização e que não carrega corretamente;
O conteúdo está camuflado.
Tome medidas dependendo do que você vê.
Por exemplo, se a página estiver muito vazia, adicione mais conteúdo. Aqui você pode verificar seus concorrentes SERP e seguir suas melhores práticas com a ajuda da seção Editor de Conteúdo do WebSite Auditor.
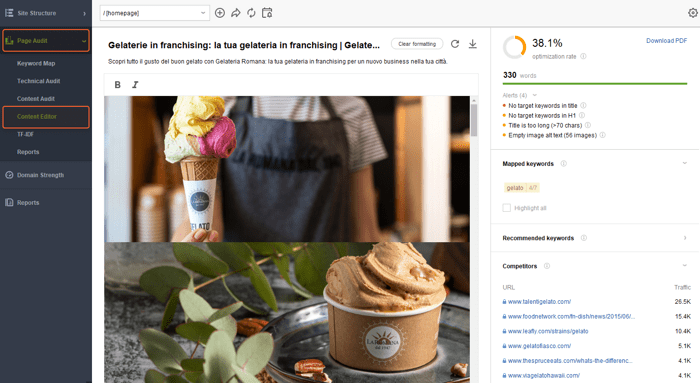
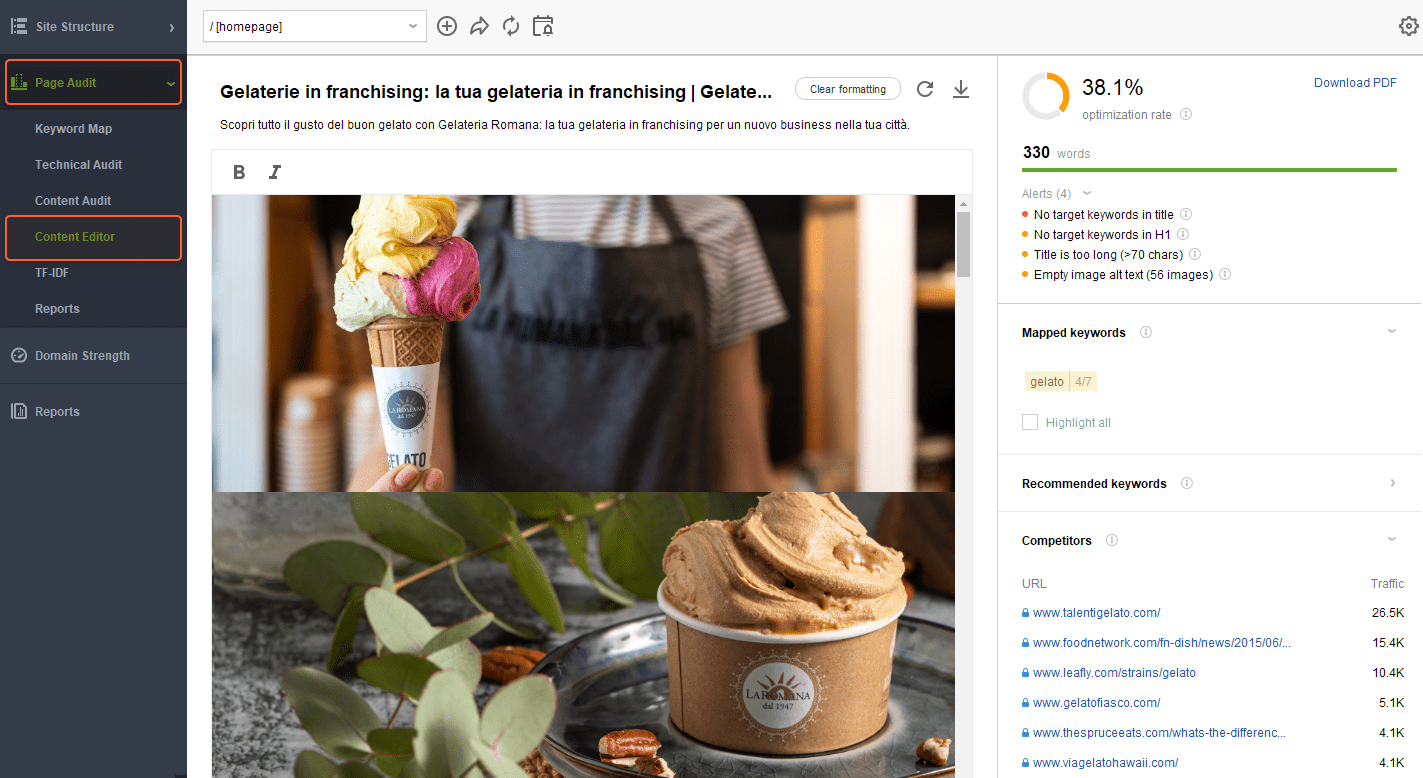
Se você suspeitar que pode haver algum conteúdo de bloqueio de renderização na página afetada, verifique os pop-ups que utilizam scripts de terceiros e certifique-se de que funcionem corretamente e sejam realmente legíveis pelo Google. Resumindo, o Google deve ver o conteúdo das suas páginas da mesma forma que os usuários o veem.
Se o conteúdo da sua página estiver oculto, verifique se todos os scripts ou imagens estão acessíveis ao Google.
A comunidade SEO tem falado muito sobre redirecionamentos de URL. Mesmo assim, os SEOs continuam cometendo erros que levam a erros de redirecionamento e indexação corrompida. Aqui estão alguns motivos comuns pelos quais o Google não consegue ler os redirecionamentos corretamente:
Uma cadeia de redirecionamento é muito longa
Um redirecionamento resulta em um loop infinito de redirecionamentos (loop de redirecionamento)
Um URL de redirecionamento excede o comprimento máximo do URL (2 MB para Google Chrome)
Uma cadeia de redirecionamento contém um URL inválido ou vazio
A única maneira de corrigir erros de redirecionamento se resume a uma frase: configure os redirecionamentos corretamente. Evite longas cadeias de redirecionamento que apenas desperdiçam orçamento de rastreamento de SEO e drenam o suco de links, certifique-se de que não haja URLs 404 ou 410 na cadeia e sempre redirecione URLs para páginas relevantes.
Erros de servidor podem ocorrer porque o servidor pode ter travado, expirado ou inativo quando o Googlebot apareceu.
A primeira coisa a fazer aqui é verificar o URL afetado. Vá para a ferramenta Inspecionar URL no GSC e veja se ainda mostra um erro. Se estiver tudo bem, a única coisa que você pode fazer é solicitar a reindexação.
Se ainda houver um erro, você terá as seguintes opções dependendo da natureza do erro:
Reduza o carregamento excessivo de páginas para solicitações de páginas dinâmicas
Certifique-se de que o servidor de hospedagem do seu site não esteja inoperante, sobrecarregado ou configurado incorretamente
Verifique se você não está bloqueando acidentalmente o Google
Controle o rastreamento e a indexação do site com sabedoria
Depois de consertar tudo, solicite a reindexação para que o Google busque a página mais rapidamente.
Duplicar sem canônico selecionado pelo usuário é um problema comum em sites multilíngues e/ou de comércio eletrônico que possuem muitas páginas com conteúdo idêntico ou muito semelhante, projetadas para finalidades diferentes. Nesse caso, você deve marcar uma página como canônica para evitar problemas de conteúdo duplicado.
Este é uma coisa interessante. Pode acontecer que você tenha indicado uma determinada página como canônica, mas o Google decidiu escolher outra versão dessa página como canônica, indexando-a assim.
A maneira mais fácil de corrigir esses erros é colocar uma tag canônica na página escolhida pelo Google para não confundi-la no futuro. Se quiser manter o canônico na página escolhida, você pode redirecionar a página escolhida pelo Google para o URL necessário.
O Google não indexa uma página porque ela é uma duplicata de uma página canônica. Apenas deixe como está.
Se uma página tiver o status Descoberta, o Google já a descobriu, mas ainda não a rastreou e indexou. A única coisa que você pode fazer aqui é verificar as instruções de indexação da página em caso de dúvidas. Se estiver tudo bem (ou seja, do jeito que você pretendia), deixe o Google fazer o resto mais tarde.
Logicamente, esta descrição significa que o Google rastreou sua página, mas não a indexou. A página será indexada se as instruções de indexação não indicarem o contrário. Você não precisa solicitar a reindexação – o Googlebot sabe que a página está aguardando sua vez de ser indexada.
O Google Search Console pode ajudá-lo muito quando se trata de detectar e corrigir problemas de indexação. Mas seria bom demais se não houvesse mas. O problema é que o Search Console só mostra problemas quando o Google tenta buscar uma página e falha por qualquer motivo. Se tal página nem for descoberta pelo Google, não haverá noção do problema de indexação no GSC. Embora a questão possa ser importante, na verdade pode haver muitos deles.
O WebSite Auditor pode ajudá-lo a encontrar e corrigir problemas como esse. Vá para Estrutura do site > Páginas e habilite a coluna Data do cache no Google no espaço de trabalho que você precisa.
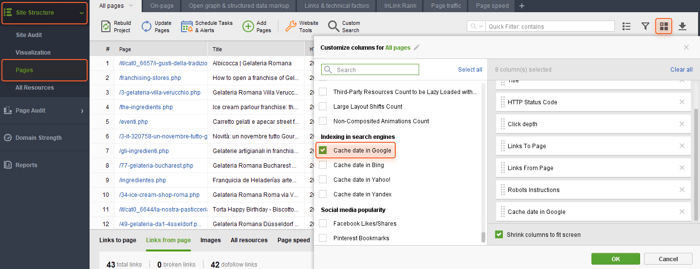
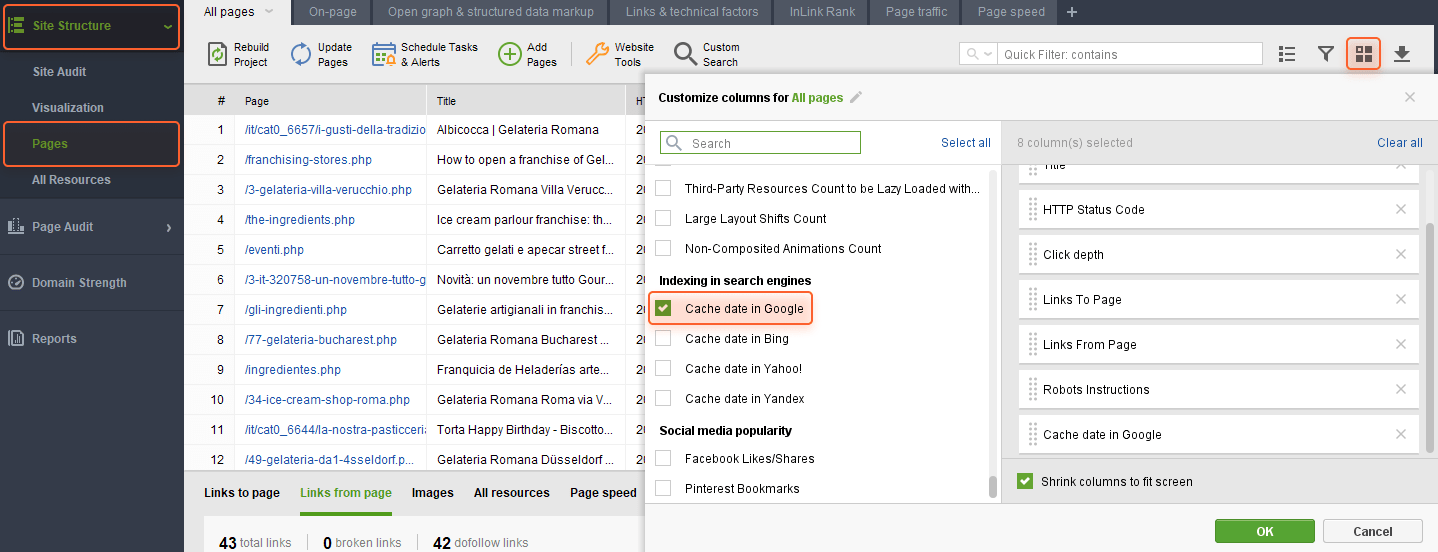
Isso permitirá que você veja a data em que uma página foi armazenada em cache no Google.
Agora dê uma olhada na data do cache.
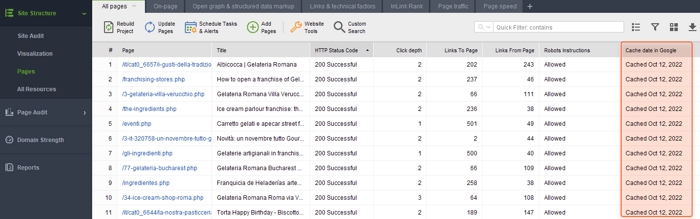
Se a data estiver um pouco distante (há mais de um ano) ou estiver faltando, o Google provavelmente não sabe que a página existe. E você tem que descobrir o porquê.
Primeiro, dê uma olhada na coluna Links para página no mesmo espaço de trabalho. Se não houver links, isso significa que esta é uma página órfã e o Google não consegue encontrá-la rastreando seu site. Se você deseja que a página seja indexada, crie um link para ela nas páginas relevantes e ricas em tráfego.
Além disso, verifique a coluna Instruções dos robôs e aprofunde-se nas páginas marcadas como Não permitidas. Pode ser que você tenha bloqueado por engano as páginas que deveriam ser indexadas.
A visualização é mais um módulo útil para encontrar problemas de indexação
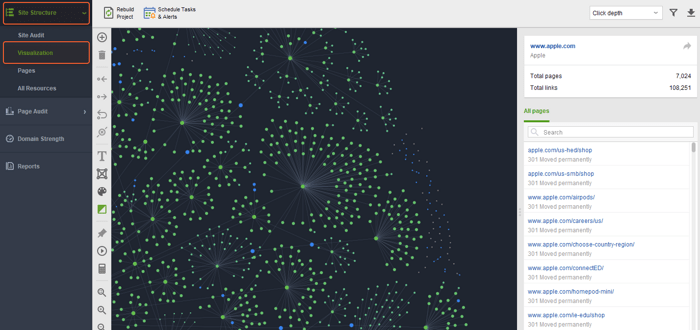
Aqui você identificará facilmente páginas órfãs (aquelas que não têm conexões com outras páginas), páginas quebradas (destacadas em vermelho) e longas cadeias de redirecionamento, que também podem ser o motivo pelo qual algumas páginas não estão sendo indexadas.
Depois de identificar e corrigir todos os problemas, peça à ferramenta para gerar um novo mapa do site (e um arquivo robots.txt, se necessário), que será enviado ao Google para que ele possa descobrir todas as páginas que você precisa.
Se precisar que URLs fixos sejam indexados o mais rápido possível, você pode solicitar manualmente a reindexação no Google Search Console.
Audite regularmente como suas páginas são indexadas, pois erros podem ocorrer a qualquer momento. E por qualquer motivo: desde problemas com provedores de hospedagem até bugs e atualizações do Google que podem afetar a forma como os algoritmos do Google tratam as coisas.
Quais são os problemas de indexação que você enfrenta com mais frequência? Compartilhe sua experiência em nossa comunidade SEO do Facebook.
| Linking websites | N/A |
| Backlinks | N/A |
| InLink Rank | N/A |







