How Google May Track the Media You Consume (to Influence Search Results)

 Photo by Jason Briscoe on Unsplash
Photo by Jason Briscoe on Unsplash
Google knows what you are watching on television. It's likely it hears your radio playing. It knows what you listen to on Spotify, and what you watch on Netflix. It's possible it can take that information and personalize your search results based upon that information. And it is possible you wouldn't even hear your devices talking to each other when that happens, as described in Google's patent Communicating Information Between Devices Using Ultra High Frequency Audio.
A couple of years ago, I wrote about Google Media Consumption History Patent Filed, which had me interested in what else my phone was picking up and listening to during the course of a day. The post is about the patent called Query Response using Media Consumption history. I've wanted to look deeper into what Google might be doing with this type of information, and that curiosity inspired this post.
Google was granted a patent the year before about what you were watching on TV being used as a ranking signal, but the media consumption history patent was different. Google has been granted at least one patent that involves picking up an audio from a television to enable it to identify views of that television. I was curious about what else Google might be doing with such information, and thought it was worth looking at some other patents on personal media consumption histories that may be related. Imagine being able to conduct queries such as this one, an example from the query response patent:

Media We Consume online
One of the first related patents that I found provided more details on what a media consumption history might contain. It looks like it was inspired by retaining a record of ratings and reviews a person might make at subscription-based services, in case they unsubscribe from those services or it might be shut down for some reason:
Personal media database
The abstract from the patent gives us a summary of what it is about
This sounds like a thoughtful aid to someone who might be interested in movies or songs or tracking what they watch or listen to and possibly review. Google Now shows off stories that are related to things you have searched for in the past, and things that you have indicated that you have an interest in such as media involving specific actors and musicians. Google's search personalization approach is a matter of showing searchers documents that they consider authoritative and documents that reflect their interests from their search history. Adding a media consumption history to a search history based personalization makes sense. It is information on a level that captures the interests of a searcher. As the Personal Media Database patent tells us:
Media Consumption Influencing Search Results
The next patent I came across that discussed a media consumption history focuses upon how that history might influence the search results that we see.
Determining media consumption preferences
Abstract:
This patent goes beyond looking at what someone listens to and watches, and the idea of media consumption is expanded to cover content that someone may purchase. This patent also brings recommendation systems into the discussion about media consumption histories. It tells us how these histories might be used to influence search results:
We are given the context of an example search. Someone who searches for "free games" may be shown "board games" if past purchases from them have shown an interest in board games. A person searching for "action movies" may be shown movies that have an element of romance to them if the searcher has indicated liking romantic films in addition to action movies. Someone searching for "foreign films" may be shown Russian Films, if there is a history of past digital media purchases of content presented in Russian.
There have been many articles that have come out that talk about personalized search results leading to filter bubbles at Google. If you are surrounded by a bubble, and see reflections within it, those reflections show you your interests where ever you look. How might you avoid such bubbles? Would bringing other influences beyond a previous search history, such as a media consumption history help avoid those filter bubbles?
The patent tells us about a language preference extraction module where if you buy books, magazines, and watch movies and listen to recordings all in one particular language, that may indicate a preference for media in that language.
Similar to a language preference, this media consumption preference patent also mentions an example category/genre preference extraction system. It may contain information about a person's purchase or viewing history when it comes to digital media items. If someone were to catalogue all of the movies and TV shows that you have streamed or watched on television, or books and magazines that you have read, or songs that you have listened to, and tried to determine which genres or categories were most popular, that could influence search results as well. I like watching horror movies, but not reading horror books, and this preference system would understand that genre preference for different media categories.
Entities in Media
When Google introduced the knowledge graph in 2012, it started bringing us a new way of searching that didn't rely as much on matching keywords in a query to keywords on a document found on the Web. I wrote about a patent about how search results might be answered directly from a data store of information collected from a knowledge graph, in the post, How Knowledge Base Entities can be Used in Searches. An example from that post was how a particular query about a movie was answered by including information from the knowledge graph. The query was, "What Movie did Robert Duvall say he loves the smell of Napalm in the Morning?" The search results providing an answer aren't a featured snippet with a text-based answer to the question, but instead those SERPs start with a couple of videos from the Movie, Apocalypse Now, with Robert Duvall making that statement.
There is a media consumption history patent that understands the entities that you may have seen or listened to, and may answer queries about them. This patent is:
Displaying a summary of media content items
Abstract
Why have a patent about the media you consume if there is a way to get such information from sources such as a knowledge graph? Like many patents, this one starts out by describing the problem that it was designed to address. It tells us directly that:
It is interesting asking about entities that appear in videos, such as these two:
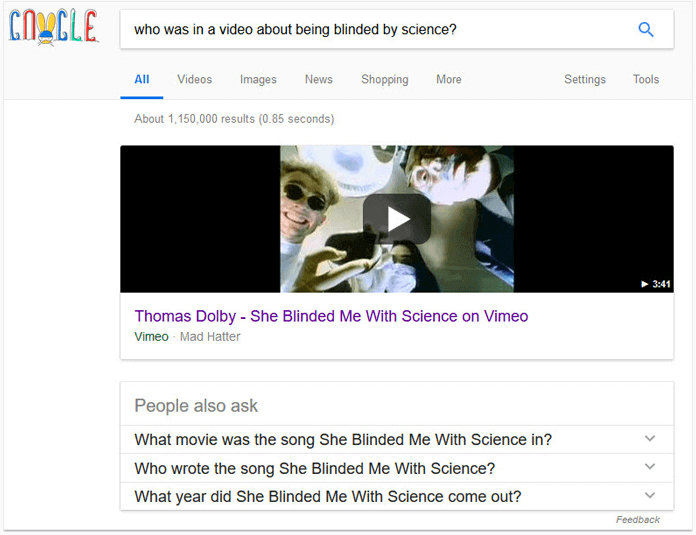
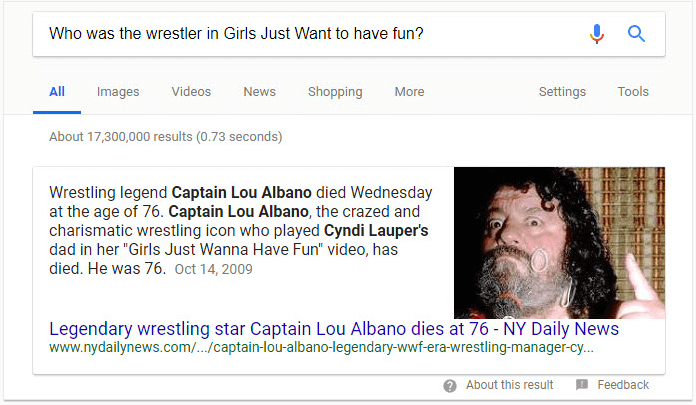
The patent tells us about an entities database, where information about entities that appear in videos may be stored:
In addition to this entities data base, the patent also tells us about another type of database known as a "graph" database. It is possible that you may see more references to this type of database, because I have started to see it mentioned in other newer patents from Google. It looks like a good resource that can be used to answer questions that people might have:
The patent also tells us that it tries to gauge how popular entities are that appear on video, and when such entities show up off the videos, such as in news.
In addition to storing information about entities that appear in media sources, the patent tells us that it contains information that summaries media content and it stores quotation information from media sources.
In Conclusion
I've written about patents in this post. A company files a patent when they have investigated a process or approach that they might use and want to protect it from other companies. Just because Google may have patents on a particular process doesn't necessarily mean that they are using it. But it does show that they have researched a particular concept, and worked out how to make it work, and have spent time and effort doing so. I've seen some concepts that appear in multiple patents, such as in many that I have written about in this article that focus upon using a media consumption history. Google may possibly be listening as you go about your day as TVs and Radios broadcast ultra-high frequency messages know as audio watermarks or audio beacons that can tell it that you have been subjected to commercials or songs or presentations. It may have access to media services that you subscribe to. You can tell Google now about your interests, so that it can show you news about those topics.

I have written in the past about a Google Location History where it tracks all the places you visit, and may show you Google Maps search results that are within certain distances from places that you regularly visit. It may be collecting information about Movies and Music and Television that you watch and listen to, so that it can answer questions about the media you consume.
Bill Slawski is the Director of SEO Research at Go Fish Digital and the founder and editor at SEO by the Sea. He lives in Carlsbad, California (North County, San Diego) a few miles from the Pacific Ocean, and is busy exploring the History of California and taking photographs along the way. He started promoting web sites in 1996, and started learning about Search Engines after seeing Alta Vista for the first time in the mid-90s. Reading patents from the search engines has been a great way of learning about the assumptions search engineers make about the Web, Search, and Searchers, and he has been reading them and writing about them regularly for the last 12 years.
| Linking websites | N/A |
| Backlinks | N/A |
| InLink Rank | N/A |

